 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSDNet: State Space Decomposition Neural Network for Time Series Forecasting
Dec 19, 2021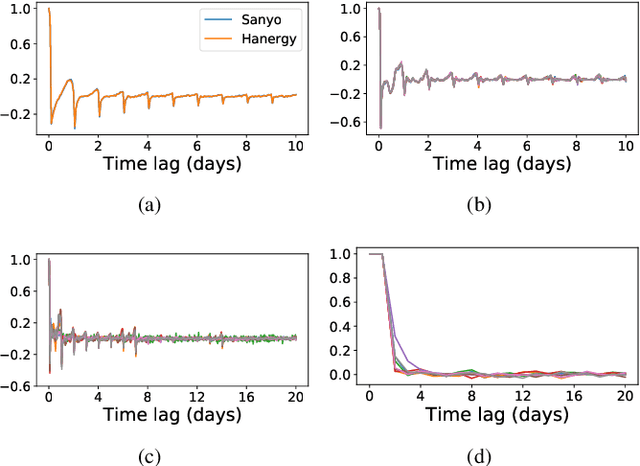
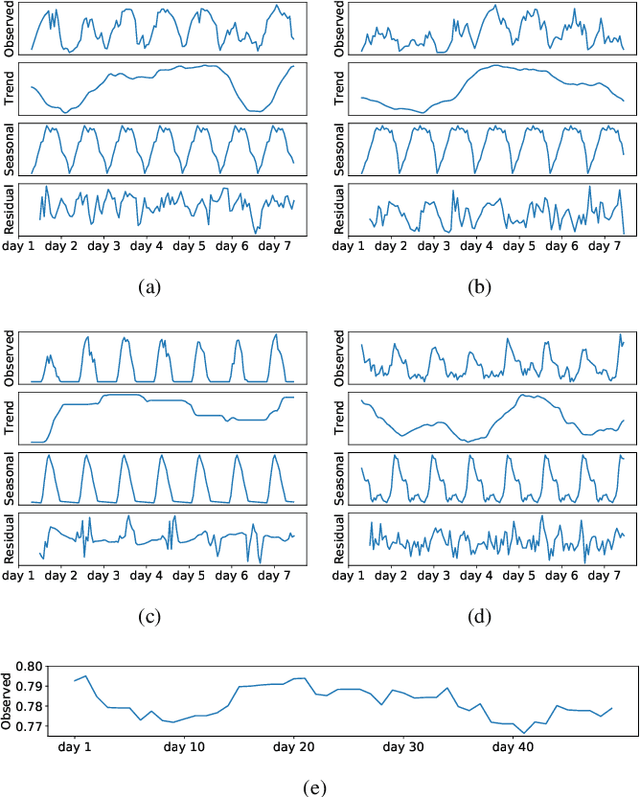
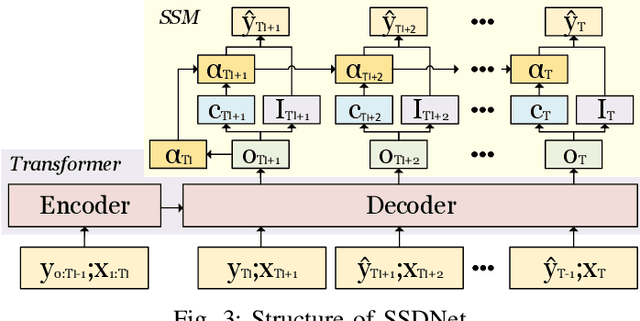
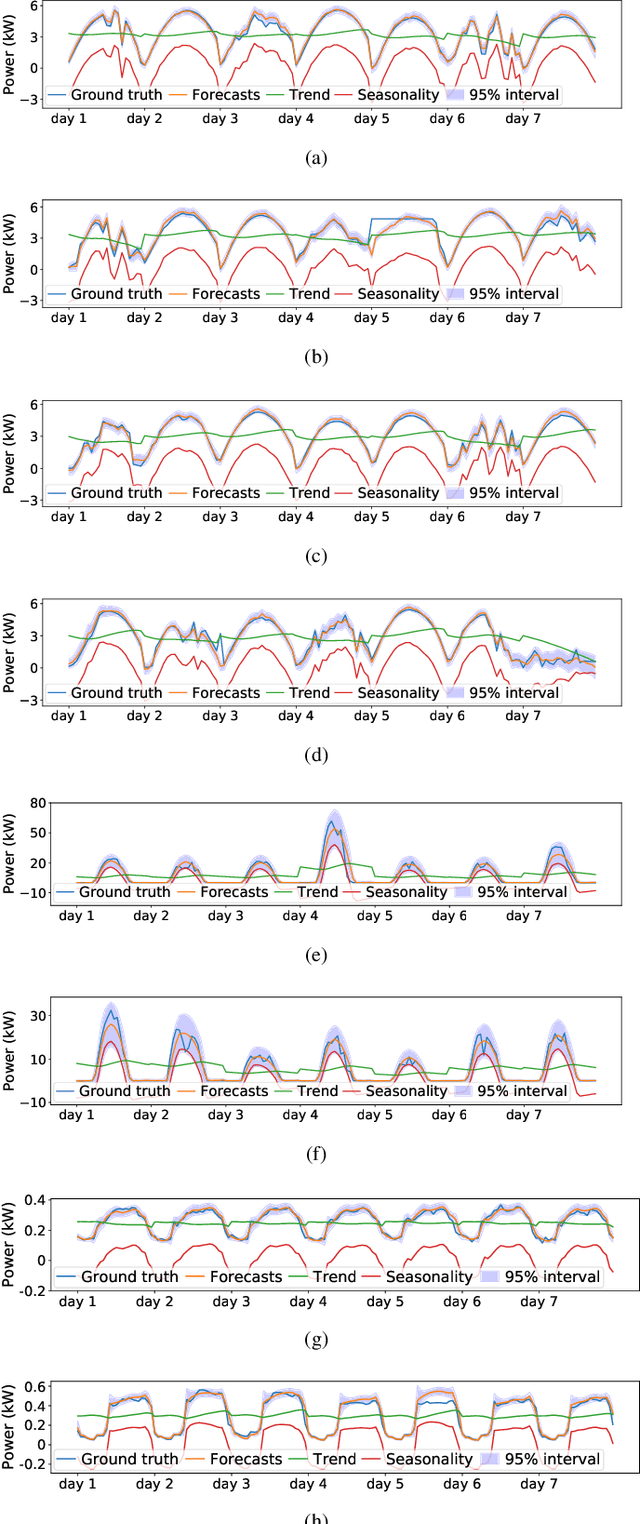
In this paper, we present SSDNet, a novel deep learning approach for time series forecasting. SSDNet combines the Transformer architecture with state space models to provide probabilistic and interpretable forecasts, including trend and seasonality components and previous time steps important for the prediction. The Transformer architecture is used to learn the temporal patterns and estimate the parameters of the state space model directly and efficiently, without the need for Kalman filters. We comprehensively evaluate the performance of SSDNet on five data sets, showing that SSDNet is an effective method in terms of accuracy and speed, outperforming state-of-the-art deep learning and statistical methods, and able to provide meaningful trend and seasonality components.
ast2vec: Utilizing Recursive Neural Encodings of Python Programs
Mar 22, 2021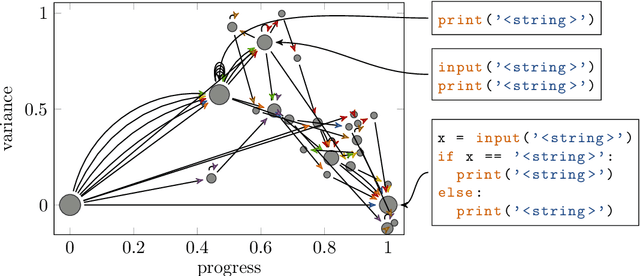
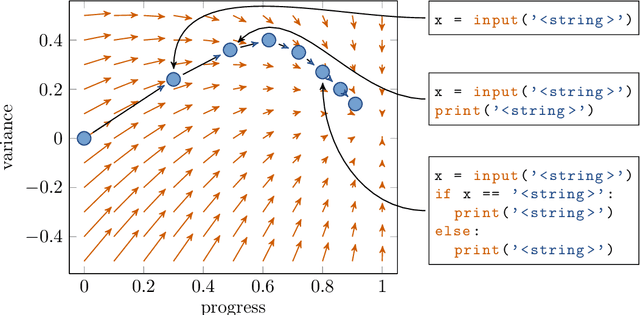
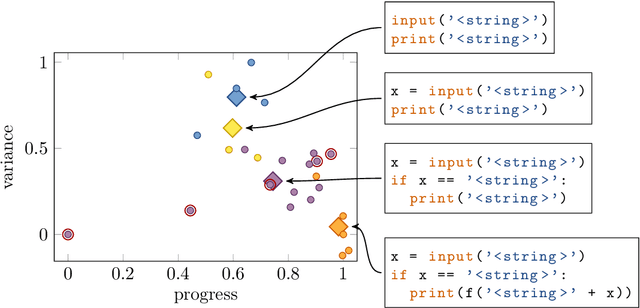
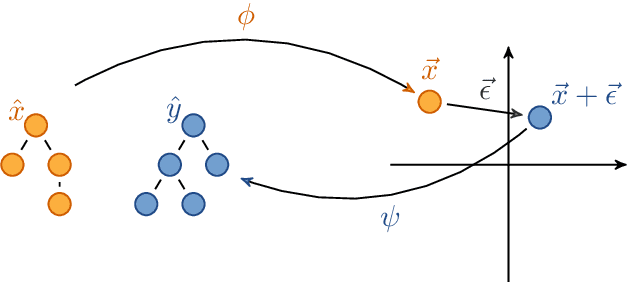
Educational datamining involves the application of datamining techniques to student activity. However, in the context of computer programming, many datamining techniques can not be applied because they expect vector-shaped input whereas computer programs have the form of syntax trees. In this paper, we present ast2vec, a neural network that maps Python syntax trees to vectors and back, thereby facilitating datamining on computer programs as well as the interpretation of datamining results. Ast2vec has been trained on almost half a million programs of novice programmers and is designed to be applied across learning tasks without re-training, meaning that users can apply it without any need for (additional) deep learning. We demonstrate the generality of ast2vec in three settings: First, we provide example analyses using ast2vec on a classroom-sized dataset, involving visualization, student motion analysis, clustering, and outlier detection, including two novel analyses, namely a progress-variance-projection and a dynamical systems analysis. Second, we consider the ability of ast2vec to recover the original syntax tree from its vector representation on the training data and two further large-scale programming datasets. Finally, we evaluate the predictive capability of a simple linear regression on top of ast2vec, obtaining similar results to techniques that work directly on syntax trees. We hope ast2vec can augment the educational datamining toolbelt by making analyses of computer programs easier, richer, and more efficient.
Recursive Tree Grammar Autoencoders
Dec 15, 2020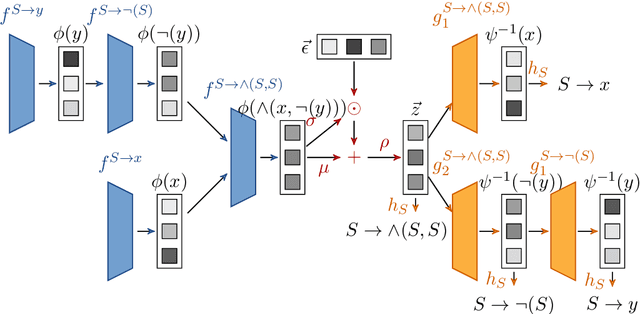

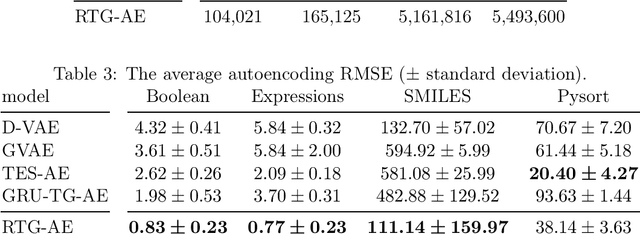
Machine learning on tree data has been mostly focused on trees as input. Much less research has investigates trees as output, like in molecule optimization for drug discovery or hint generation for intelligent tutoring systems. In this work, we propose a novel autoencoder approach, called recursive tree grammar autoencoder (RTG-AE), which encodes trees via a bottom-up parser and decodes trees via a tree grammar, both controlled by neural networks that minimize the variational autoencoder loss. The resulting encoding and decoding functions can then be employed in subsequent tasks, such as optimization and time series prediction. RTG-AE combines variational autoencoders, grammatical knowledge, and recursive processing. Our key message is that this combination improves performance compared to only combining two of these three components. In particular, we show experimentally that our proposed method improves the autoencoding error, training time, and optimization score on four benchmark datasets compared to baselines from the literature.
DETECT: A Hierarchical Clustering Algorithm for Behavioural Trends in Temporal Educational Data
May 04, 2020
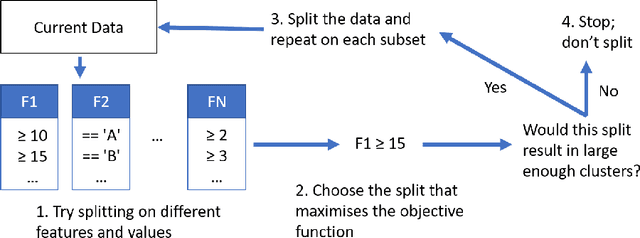

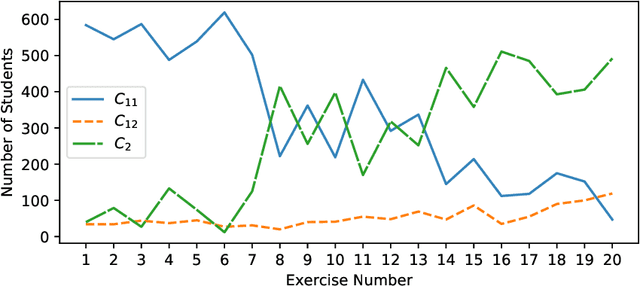
Techniques for clustering student behaviour offer many opportunities to improve educational outcomes by providing insight into student learning. However, one important aspect of student behaviour, namely its evolution over time, can often be challenging to identify using existing methods. This is because the objective functions used by these methods do not explicitly aim to find cluster trends in time, so these trends may not be clearly represented in the results. This paper presents `DETECT' (Detection of Educational Trends Elicited by Clustering Time-series data), a novel divisive hierarchical clustering algorithm that incorporates temporal information into its objective function to prioritise the detection of behavioural trends. The resulting clusters are similar in structure to a decision tree, with a hierarchy of clusters defined by decision rules on features. DETECT is easy to apply, highly customisable, applicable to a wide range of educational datasets and yields easily interpretable results. Through a case study of two online programming courses (N>600), this paper demonstrates two example applications of DETECT: 1) to identify how cohort behaviour develops over time and 2) to identify student behaviours that characterise exercises where many students give up.
Tree Echo State Autoencoders with Grammars
Apr 19, 2020

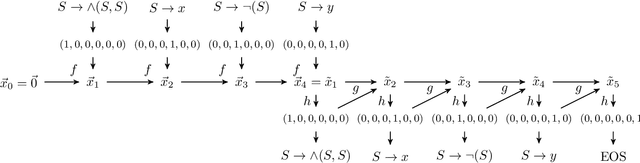

Tree data occurs in many forms, such as computer programs, chemical molecules, or natural language. Unfortunately, the non-vectorial and discrete nature of trees makes it challenging to construct functions with tree-formed output, complicating tasks such as optimization or time series prediction. Autoencoders address this challenge by mapping trees to a vectorial latent space, where tasks are easier to solve, and then mapping the solution back to a tree structure. However, existing autoencoding approaches for tree data fail to take the specific grammatical structure of tree domains into account and rely on deep learning, thus requiring large training datasets and long training times. In this paper, we propose tree echo state autoencoders (TES-AE), which are guided by a tree grammar and can be trained within seconds by virtue of reservoir computing. In our evaluation on three datasets, we demonstrate that our proposed approach is not only much faster than a state-of-the-art deep learning autoencoding approach (D-VAE) but also has less autoencoding error if little data and time is given.
A Survey of Automated Programming Hint Generation -- The HINTS Framework
Aug 30, 2019
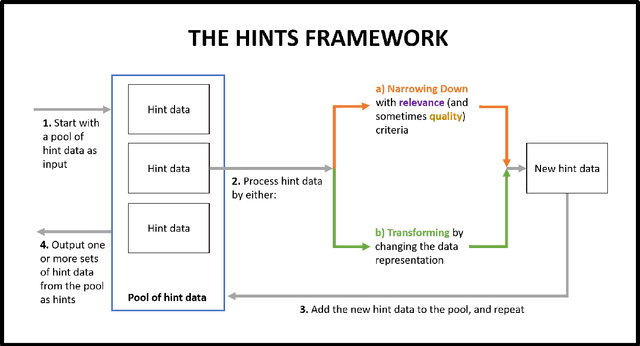
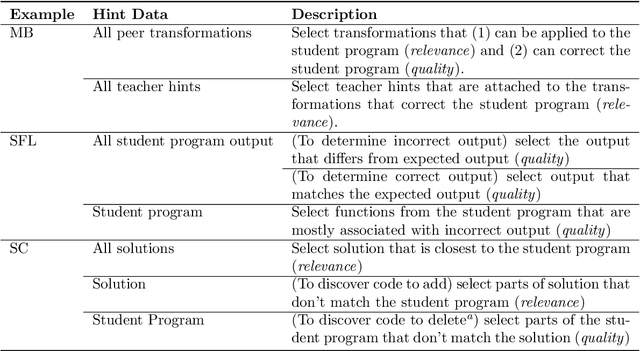
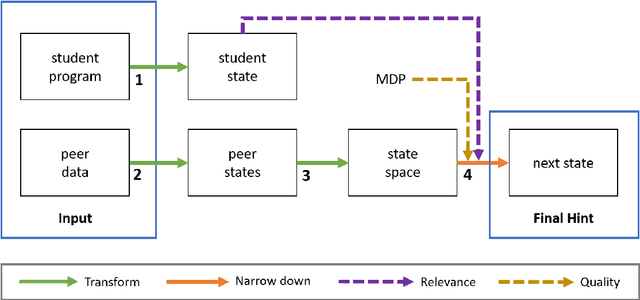
Automated tutoring systems offer the flexibility and scalability necessary to facilitate the provision of high quality and universally accessible programming education. In order to realise the full potential of these systems, recent work has proposed a diverse range of techniques for automatically generating hints to assist students with programming exercises. This paper integrates these apparently disparate approaches into a coherent whole. Specifically, it emphasises that all hint techniques can be understood as a series of simpler components with similar properties. Using this insight, it presents a simple framework for describing such techniques, the Hint Iteration by Narrow-down and Transformation Steps (HINTS) framework, and it surveys recent work in the context of this framework. It discusses important implications of the survey and framework, including the need to further develop evaluation methods and the importance of considering hint technique components when designing, communicating and evaluating hint systems. Ultimately, this paper is designed to facilitate future opportunities for the development, extension and comparison of automated programming hint techniques in order to maximise their educational potential.