 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Gap: Automated Corpus Creation for Enthymeme Detection and Reconstruction in Learner Arguments
Oct 27, 2023Writing strong arguments can be challenging for learners. It requires to select and arrange multiple argumentative discourse units (ADUs) in a logical and coherent way as well as to decide which ADUs to leave implicit, so called enthymemes. However, when important ADUs are missing, readers might not be able to follow the reasoning or understand the argument's main point. This paper introduces two new tasks for learner arguments: to identify gaps in arguments (enthymeme detection) and to fill such gaps (enthymeme reconstruction). Approaches to both tasks may help learners improve their argument quality. We study how corpora for these tasks can be created automatically by deleting ADUs from an argumentative text that are central to the argument and its quality, while maintaining the text's naturalness. Based on the ICLEv3 corpus of argumentative learner essays, we create 40,089 argument instances for enthymeme detection and reconstruction. Through manual studies, we provide evidence that the proposed corpus creation process leads to the desired quality reduction, and results in arguments that are similarly natural to those written by learners. Finally, first baseline approaches to enthymeme detection and reconstruction demonstrate the corpus' usefulness.
Assessing the Helpfulness of Learning Materials with Inference-Based Learner-Like Agent
Oct 05, 2020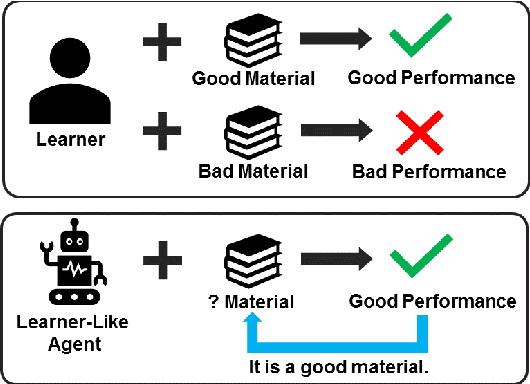
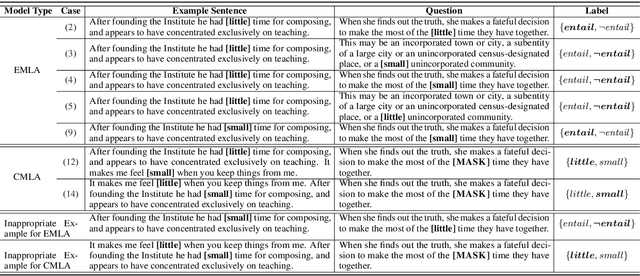
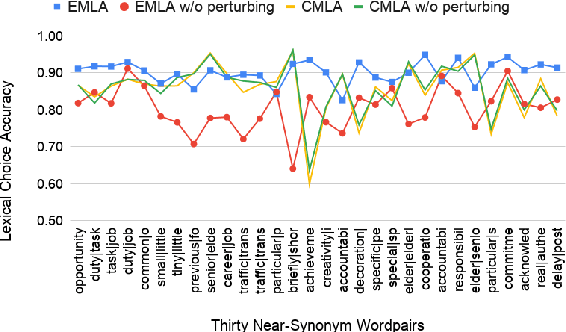

Many English-as-a-second language learners have trouble using near-synonym words (e.g., small vs.little; briefly vs.shortly) correctly, and often look for example sentences to learn how two nearly synonymous terms differ. Prior work uses hand-crafted scores to recommend sentences but has difficulty in adopting such scores to all the near-synonyms as near-synonyms differ in various ways. We notice that the helpfulness of the learning material would reflect on the learners' performance. Thus, we propose the inference-based learner-like agent to mimic learner behavior and identify good learning materials by examining the agent's performance. To enable the agent to behave like a learner, we leverage entailment modeling's capability of inferring answers from the provided materials. Experimental results show that the proposed agent is equipped with good learner-like behavior to achieve the best performance in both fill-in-the-blank (FITB) and good example sentence selection tasks. We further conduct a classroom user study with college ESL learners. The results of the user study show that the proposed agent can find out example sentences that help students learn more easily and efficiently. Compared to other models, the proposed agent improves the score of more than 17% of students after learning.
From Receptive to Productive: Learning to Use Confusing Words through Automatically Selected Example Sentences
Jun 06, 2019



Knowing how to use words appropriately has been a key to improving language proficiency. Previous studies typically discuss how students learn receptively to select the correct candidate from a set of confusing words in the fill-in-the-blank task where specific context is given. In this paper, we go one step further, assisting students to learn to use confusing words appropriately in a productive task: sentence translation. We leverage the GiveMeExample system, which suggests example sentences for each confusing word, to achieve this goal. In this study, students learn to differentiate the confusing words by reading the example sentences, and then choose the appropriate word(s) to complete the sentence translation task. Results show students made substantial progress in terms of sentence structure. In addition, highly proficient students better managed to learn confusing words. In view of the influence of the first language on learners, we further propose an effective approach to improve the quality of the suggested sentences.