 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Visual Analytics Framework for Composing a Hierarchical Classification for Medieval Illuminations
Aug 20, 2022
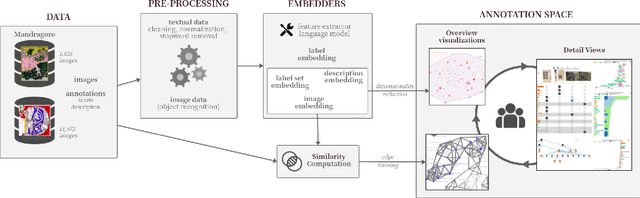
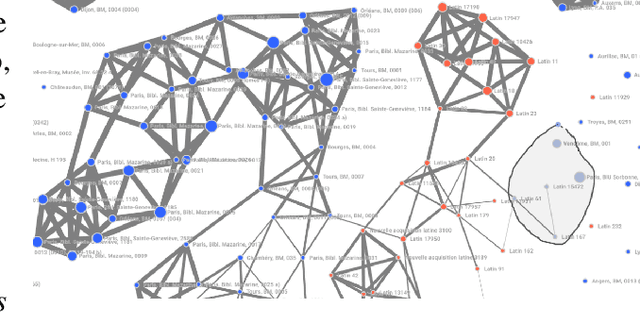
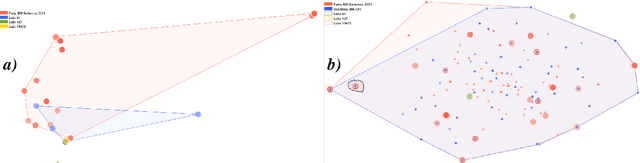
Annotated data is a requirement for applying supervised machine learning methods, and the quality of annotations is crucial for the result. Especially when working with cultural heritage collections that inhere a manifold of uncertainties, annotating data remains a manual, arduous task to be carried out by domain experts. Our project started with two already annotated sets of medieval manuscript images which however were incomplete and comprised conflicting metadata based on scholarly and linguistic differences. Our aims were to create (1) a uniform set of descriptive labels for the combined data set, and (2) a hierarchical classification of a high quality that can be used as a valuable input for supervised machine learning. To reach these goals, we developed a visual analytics system to enable medievalists to combine, regularize and extend the vocabulary used to describe these data sets. Visual interfaces for word and image embeddings as well as co-occurrences of the annotations across the data sets enable annotating multiple images at the same time, recommend annotation label candidates and support composing a hierarchical classification of labels. Our system itself implements a semi-supervised method as it updates visual representations based on the medievalists' feedback, and a series of usage scenarios document its value for the target community.
Detecting Wandering Behavior of People with Dementia
Oct 25, 2021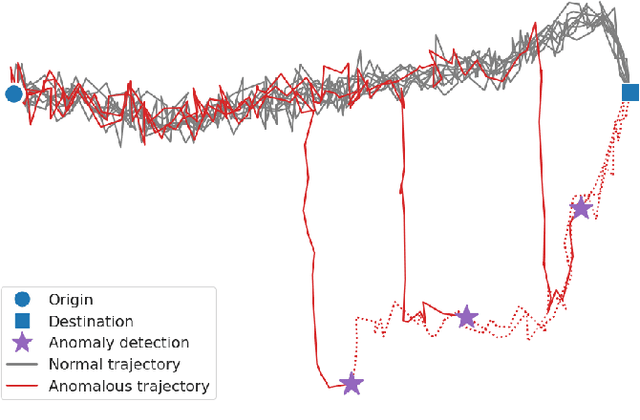
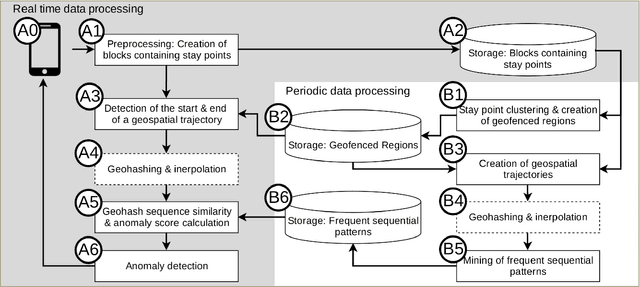
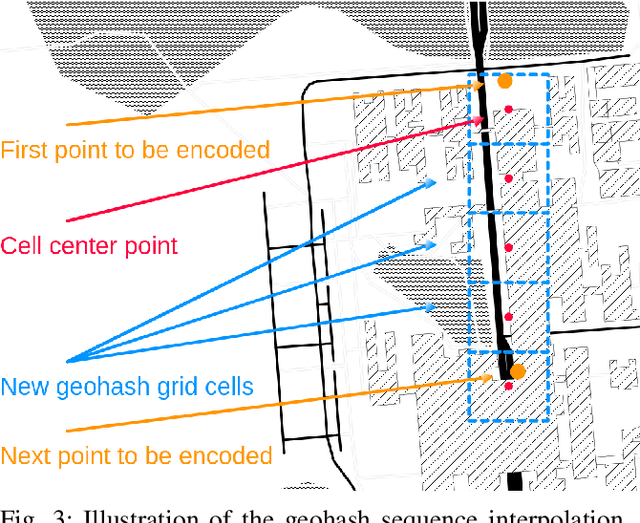

Wandering is a problematic behavior in people with dementia that can lead to dangerous situations. To alleviate this problem we design an approach for the real-time automatic detection of wandering leading to getting lost. The approach relies on GPS data to determine frequent locations between which movement occurs and a step that transforms GPS data into geohash sequences. Those can be used to find frequent and normal movement patterns in historical data to then be able to determine whether a new on-going sequence is anomalous. We conduct experiments on synthetic data to test the ability of the approach to find frequent locations and to compare it against an alternative, state-of-the-art approach. Our approach is able to identify frequent locations and to obtain good performance (up to AUC = 0.99 for certain parameter settings) outperforming the state-of-the-art approach.
Summary Explorer: Visualizing the State of the Art in Text Summarization
Aug 04, 2021
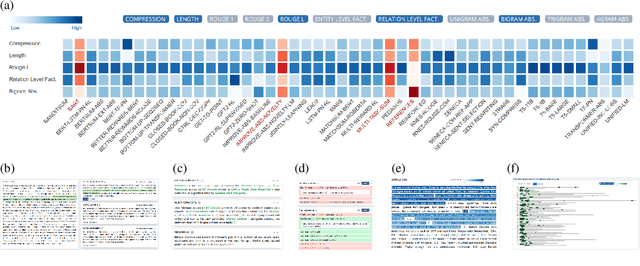

This paper introduces Summary Explorer, a new tool to support the manual inspection of text summarization systems by compiling the outputs of 55~state-of-the-art single document summarization approaches on three benchmark datasets, and visually exploring them during a qualitative assessment. The underlying design of the tool considers three well-known summary quality criteria (coverage, faithfulness, and position bias), encapsulated in a guided assessment based on tailored visualizations. The tool complements existing approaches for locally debugging summarization models and improves upon them. The tool is available at https://tldr.webis.de/