 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Visual Analytics Framework for Composing a Hierarchical Classification for Medieval Illuminations
Paper and Code
Aug 20, 2022
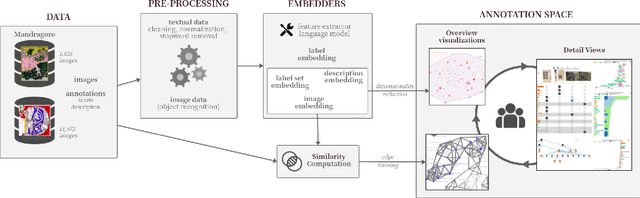
Annotated data is a requirement for applying supervised machine learning methods, and the quality of annotations is crucial for the result. Especially when working with cultural heritage collections that inhere a manifold of uncertainties, annotating data remains a manual, arduous task to be carried out by domain experts. Our project started with two already annotated sets of medieval manuscript images which however were incomplete and comprised conflicting metadata based on scholarly and linguistic differences. Our aims were to create (1) a uniform set of descriptive labels for the combined data set, and (2) a hierarchical classification of a high quality that can be used as a valuable input for supervised machine learning. To reach these goals, we developed a visual analytics system to enable medievalists to combine, regularize and extend the vocabulary used to describe these data sets. Visual interfaces for word and image embeddings as well as co-occurrences of the annotations across the data sets enable annotating multiple images at the same time, recommend annotation label candidates and support composing a hierarchical classification of labels. Our system itself implements a semi-supervised method as it updates visual representations based on the medievalists' feedback, and a series of usage scenarios document its value for the target community.