 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the "Great Unseen" in Medieval Manuscripts: Instance-Level Labeling of Legacy Image Collections with Zero-Shot Models
Nov 10, 2025We aim to theorize the medieval manuscript page and its contents more holistically, using state-of-the-art techniques to segment and describe the entire manuscript folio, for the purpose of creating richer training data for computer vision techniques, namely instance segmentation, and multimodal models for medieval-specific visual content.
Cluster-Based Random Forest Visualization and Interpretation
Jul 30, 2025Random forests are a machine learning method used to automatically classify datasets and consist of a multitude of decision trees. While these random forests often have higher performance and generalize better than a single decision tree, they are also harder to interpret. This paper presents a visualization method and system to increase interpretability of random forests. We cluster similar trees which enables users to interpret how the model performs in general without needing to analyze each individual decision tree in detail, or interpret an oversimplified summary of the full forest. To meaningfully cluster the decision trees, we introduce a new distance metric that takes into account both the decision rules as well as the predictions of a pair of decision trees. We also propose two new visualization methods that visualize both clustered and individual decision trees: (1) The Feature Plot, which visualizes the topological position of features in the decision trees, and (2) the Rule Plot, which visualizes the decision rules of the decision trees. We demonstrate the efficacy of our approach through a case study on the "Glass" dataset, which is a relatively complex standard machine learning dataset, as well as a small user study.
A Visual Analytics Framework for Composing a Hierarchical Classification for Medieval Illuminations
Aug 20, 2022
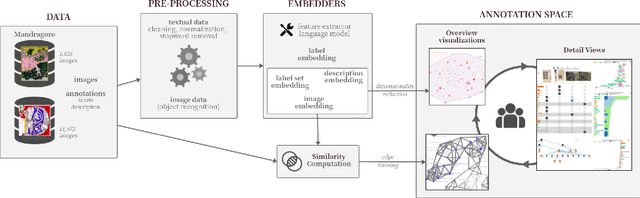
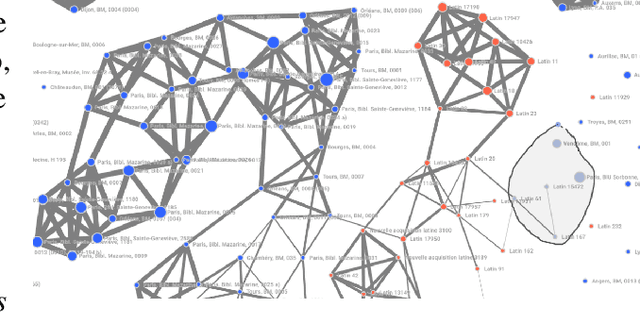
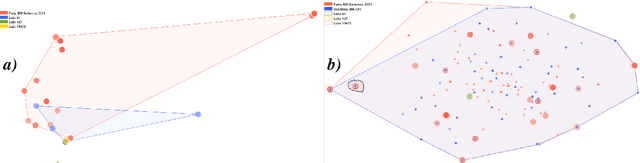
Annotated data is a requirement for applying supervised machine learning methods, and the quality of annotations is crucial for the result. Especially when working with cultural heritage collections that inhere a manifold of uncertainties, annotating data remains a manual, arduous task to be carried out by domain experts. Our project started with two already annotated sets of medieval manuscript images which however were incomplete and comprised conflicting metadata based on scholarly and linguistic differences. Our aims were to create (1) a uniform set of descriptive labels for the combined data set, and (2) a hierarchical classification of a high quality that can be used as a valuable input for supervised machine learning. To reach these goals, we developed a visual analytics system to enable medievalists to combine, regularize and extend the vocabulary used to describe these data sets. Visual interfaces for word and image embeddings as well as co-occurrences of the annotations across the data sets enable annotating multiple images at the same time, recommend annotation label candidates and support composing a hierarchical classification of labels. Our system itself implements a semi-supervised method as it updates visual representations based on the medievalists' feedback, and a series of usage scenarios document its value for the target community.