 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Effective Representations for Retrieval Using Self-Distillation with Adaptive Relevance Margins
Paper and Code

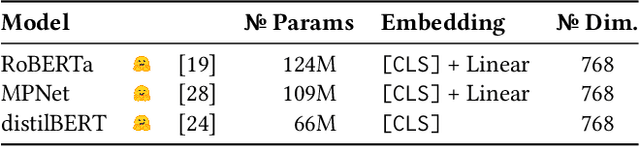
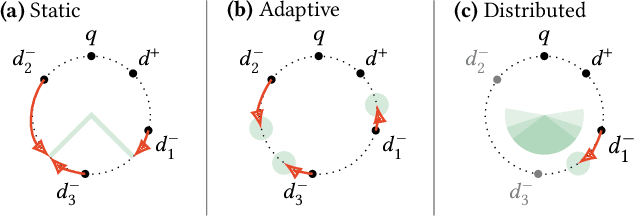

Representation-based retrieval models, so-called biencoders, estimate the relevance of a document to a query by calculating the similarity of their respective embeddings. Current state-of-the-art biencoders are trained using an expensive training regime involving knowledge distillation from a teacher model and batch-sampling. Instead of relying on a teacher model, we contribute a novel parameter-free loss function for self-supervision that exploits the pre-trained language modeling capabilities of the encoder model as a training signal, eliminating the need for batch sampling by performing implicit hard negative mining. We investigate the capabilities of our proposed approach through extensive ablation studies, demonstrating that self-distillation can match the effectiveness of teacher distillation using only 13.5% of the data, while offering a speedup in training time between 3x and 15x compared to parametrized losses. Code and data is made openly available.