 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiLinguahah : A New Unsupervised Multilingual Acoustic Laughter Segmentation Method
May 07, 2026Laughter is a social non-vocalization that is universal across cultures and languages, and is crucial for human communication, including social bonding and communication signaling. However, detecting laughter in audio is a challenging task, and segmenting is even more difficult. Currently, Machine Learning methods generally rely on costly manual annotation, and their datasets are mostly based on English contexts. Thus, we propose an unsupervised multilingual method that sets up the laughter segmentation task as an anomaly detection of energy-based segmented audio sequences. Our method applies an Isolation Forest on audio representations learned from BYOL-A encoder. We compare our method with several state-of-the-art laughter detection algorithms on four datasets, including stand-up comedy, sitcoms, and general short audio from AudioSet. Our results show that state-of-the-art methods are not optimized for multilingual contexts, while our method outperforms them in non-English settings.
The Touché23-ValueEval Dataset for Identifying Human Values behind Arguments
Jan 31, 2023

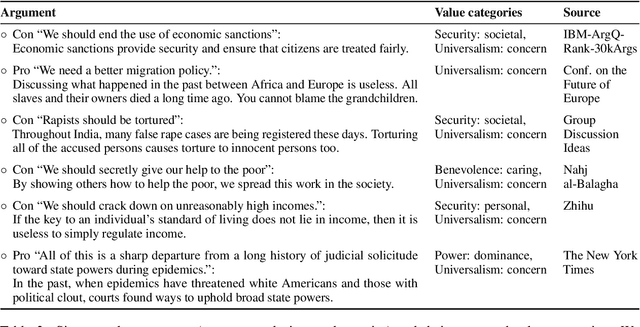

We present the Touch\'e23-ValueEval Dataset for Identifying Human Values behind Arguments. To investigate approaches for the automated detection of human values behind arguments, we collected 9324 arguments from 6 diverse sources, covering religious texts, political discussions, free-text arguments, newspaper editorials, and online democracy platforms. Each argument was annotated by 3 crowdworkers for 54 values. The Touch\'e23-ValueEval dataset extends the Webis-ArgValues-22. In comparison to the previous dataset, the effectiveness of a 1-Baseline decreases, but that of an out-of-the-box BERT model increases. Therefore, though the classification difficulty increased as per the label distribution, the larger dataset allows for training better models.
How does a Pre-Trained Transformer Integrate Contextual Keywords? Application to Humanitarian Computing
Nov 07, 2021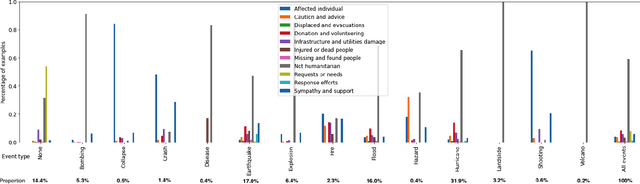
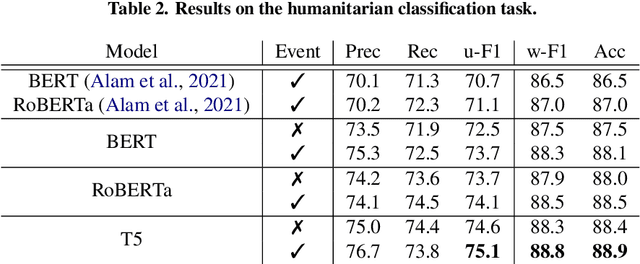
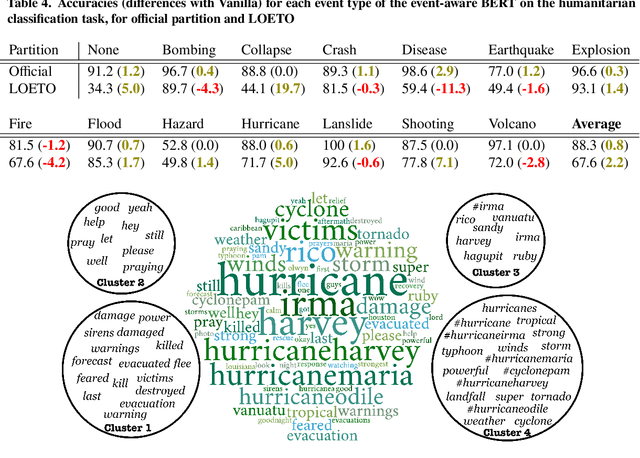
In a classification task, dealing with text snippets and metadata usually requires dealing with multimodal approaches. When those metadata are textual, it is tempting to use them intrinsically with a pre-trained transformer, in order to leverage the semantic information encoded inside the model. This paper describes how to improve a humanitarian classification task by adding the crisis event type to each tweet to be classified. Based on additional experiments of the model weights and behavior, it identifies how the proposed neural network approach is partially over-fitting the particularities of the Crisis Benchmark, to better highlight how the model is still undoubtedly learning to use and take advantage of the metadata's textual semantics.