 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Adversarial Attacks on High-dimensional Offline Bandits
Feb 02, 2026Bandit algorithms have recently emerged as a powerful tool for evaluating machine learning models, including generative image models and large language models, by efficiently identifying top-performing candidates without exhaustive comparisons. These methods typically rely on a reward model, often distributed with public weights on platforms such as Hugging Face, to provide feedback to the bandit. While online evaluation is expensive and requires repeated trials, offline evaluation with logged data has become an attractive alternative. However, the adversarial robustness of offline bandit evaluation remains largely unexplored, particularly when an attacker perturbs the reward model (rather than the training data) prior to bandit training. In this work, we fill this gap by investigating, both theoretically and empirically, the vulnerability of offline bandit training to adversarial manipulations of the reward model. We introduce a novel threat model in which an attacker exploits offline data in high-dimensional settings to hijack the bandit's behavior. Starting with linear reward functions and extending to nonlinear models such as ReLU neural networks, we study attacks on two Hugging Face evaluators used for generative model assessment: one measuring aesthetic quality and the other assessing compositional alignment. Our results show that even small, imperceptible perturbations to the reward model's weights can drastically alter the bandit's behavior. From a theoretical perspective, we prove a striking high-dimensional effect: as input dimensionality increases, the perturbation norm required for a successful attack decreases, making modern applications such as image evaluation especially vulnerable. Extensive experiments confirm that naive random perturbations are ineffective, whereas carefully targeted perturbations achieve near-perfect attack success rates ...
SUSD: Structured Unsupervised Skill Discovery through State Factorization
Feb 02, 2026Unsupervised Skill Discovery (USD) aims to autonomously learn a diverse set of skills without relying on extrinsic rewards. One of the most common USD approaches is to maximize the Mutual Information (MI) between skill latent variables and states. However, MI-based methods tend to favor simple, static skills due to their invariance properties, limiting the discovery of dynamic, task-relevant behaviors. Distance-Maximizing Skill Discovery (DSD) promotes more dynamic skills by leveraging state-space distances, yet still fall short in encouraging comprehensive skill sets that engage all controllable factors or entities in the environment. In this work, we introduce SUSD, a novel framework that harnesses the compositional structure of environments by factorizing the state space into independent components (e.g., objects or controllable entities). SUSD allocates distinct skill variables to different factors, enabling more fine-grained control on the skill discovery process. A dynamic model also tracks learning across factors, adaptively steering the agent's focus toward underexplored factors. This structured approach not only promotes the discovery of richer and more diverse skills, but also yields a factorized skill representation that enables fine-grained and disentangled control over individual entities which facilitates efficient training of compositional downstream tasks via Hierarchical Reinforcement Learning (HRL). Our experimental results across three environments, with factors ranging from 1 to 10, demonstrate that our method can discover diverse and complex skills without supervision, significantly outperforming existing unsupervised skill discovery methods in factorized and complex environments. Code is publicly available at: https://github.com/hadi-hosseini/SUSD.
MEENA (PersianMMMU): Multimodal-Multilingual Educational Exams for N-level Assessment
Aug 24, 2025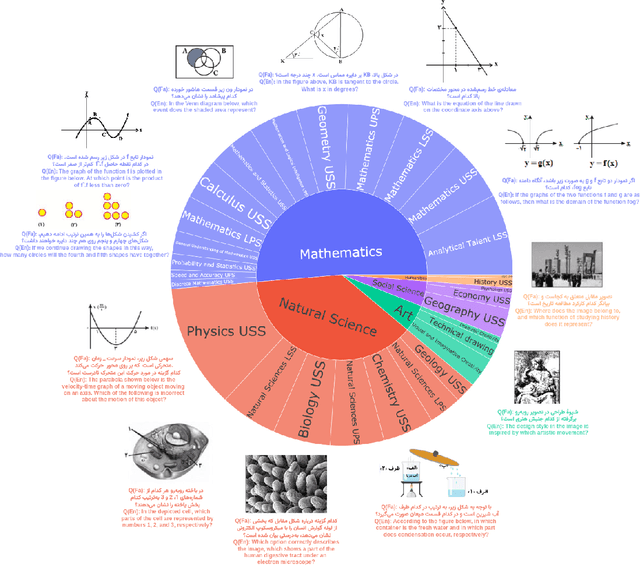

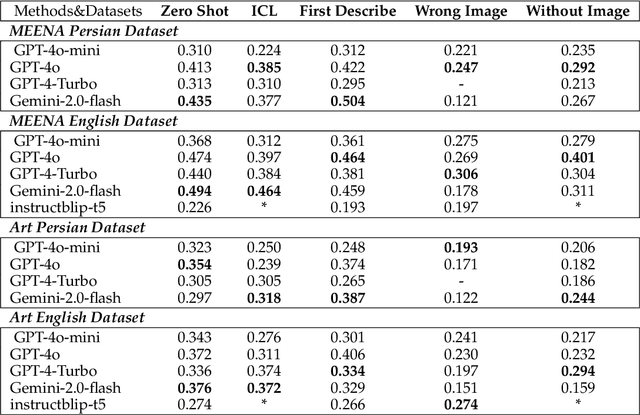
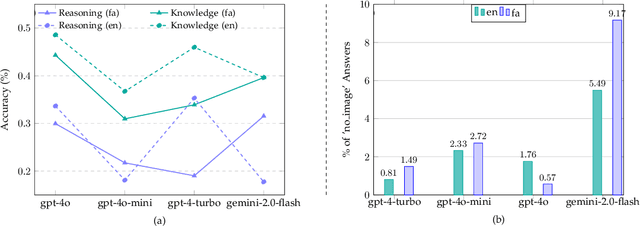
Recent advancements in large vision-language models (VLMs) have primarily focused on English, with limited attention given to other languages. To address this gap, we introduce MEENA (also known as PersianMMMU), the first dataset designed to evaluate Persian VLMs across scientific, reasoning, and human-level understanding tasks. Our dataset comprises approximately 7,500 Persian and 3,000 English questions, covering a wide range of topics such as reasoning, mathematics, physics, diagrams, charts, and Persian art and literature. Key features of MEENA include: (1) diverse subject coverage spanning various educational levels, from primary to upper secondary school, (2) rich metadata, including difficulty levels and descriptive answers, (3) original Persian data that preserves cultural nuances, (4) a bilingual structure to assess cross-linguistic performance, and (5) a series of diverse experiments assessing various capabilities, including overall performance, the model's ability to attend to images, and its tendency to generate hallucinations. We hope this benchmark contributes to enhancing VLM capabilities beyond English.
T2I-FineEval: Fine-Grained Compositional Metric for Text-to-Image Evaluation
Mar 14, 2025



Although recent text-to-image generative models have achieved impressive performance, they still often struggle with capturing the compositional complexities of prompts including attribute binding, and spatial relationships between different entities. This misalignment is not revealed by common evaluation metrics such as CLIPScore. Recent works have proposed evaluation metrics that utilize Visual Question Answering (VQA) by decomposing prompts into questions about the generated image for more robust compositional evaluation. Although these methods align better with human evaluations, they still fail to fully cover the compositionality within the image. To address this, we propose a novel metric that breaks down images into components, and texts into fine-grained questions about the generated image for evaluation. Our method outperforms previous state-of-the-art metrics, demonstrating its effectiveness in evaluating text-to-image generative models. Code is available at https://github.com/hadi-hosseini/ T2I-FineEval.
Fine-Grained Alignment and Noise Refinement for Compositional Text-to-Image Generation
Mar 09, 2025
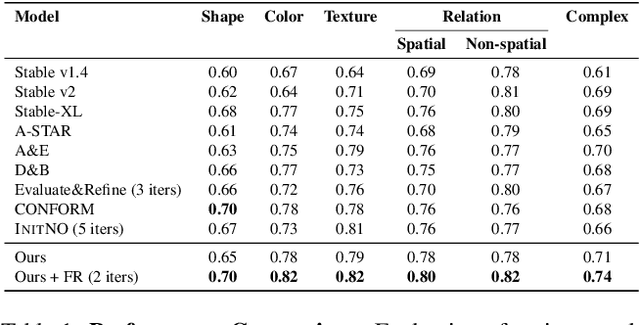
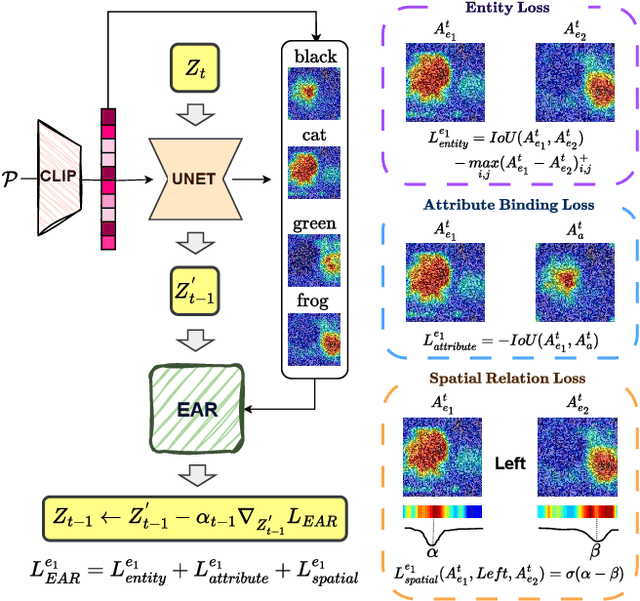

Text-to-image generative models have made significant advancements in recent years; however, accurately capturing intricate details in textual prompts, such as entity missing, attribute binding errors, and incorrect relationships remains a formidable challenge. In response, we present an innovative, training-free method that directly addresses these challenges by incorporating tailored objectives to account for textual constraints. Unlike layout-based approaches that enforce rigid structures and limit diversity, our proposed approach offers a more flexible arrangement of the scene by imposing just the extracted constraints from the text, without any unnecessary additions. These constraints are formulated as losses-entity missing, entity mixing, attribute binding, and spatial relationships, integrated into a unified loss that is applied in the first generation stage. Furthermore, we introduce a feedback-driven system for fine-grained initial noise refinement. This system integrates a verifier that evaluates the generated image, identifies inconsistencies, and provides corrective feedback. Leveraging this feedback, our refinement method first targets the unmet constraints by refining the faulty attention maps caused by initial noise, through the optimization of selective losses associated with these constraints. Subsequently, our unified loss function is reapplied to proceed the second generation phase. Experimental results demonstrate that our method, relying solely on our proposed objective functions, significantly enhances compositionality, achieving a 24% improvement in human evaluation and a 25% gain in spatial relationships. Furthermore, our fine-grained noise refinement proves effective, boosting performance by up to 5%. Code is available at https://github.com/hadi-hosseini/noise-refinement.
CER: Confidence Enhanced Reasoning in LLMs
Feb 20, 2025



Ensuring the reliability of Large Language Models (LLMs) in complex reasoning tasks remains a formidable challenge, particularly in scenarios that demand precise mathematical calculations and knowledge-intensive open-domain generation. In this work, we introduce an uncertainty-aware framework designed to enhance the accuracy of LLM responses by systematically incorporating model confidence at critical decision points. We propose an approach that encourages multi-step reasoning in LLMs and quantify the confidence of intermediate answers such as numerical results in mathematical reasoning and proper nouns in open-domain generation. Then, the overall confidence of each reasoning chain is evaluated based on confidence of these critical intermediate steps. Finally, we aggregate the answer of generated response paths in a way that reflects the reliability of each generated content (as opposed to self-consistency in which each generated chain contributes equally to majority voting). We conducted extensive experiments in five datasets, three mathematical datasets and two open-domain datasets, using four LLMs. The results consistently validate the effectiveness of our novel confidence aggregation method, leading to an accuracy improvement of up to 7.4% and 5.8% over baseline approaches in math and open-domain generation tasks, respectively. Code is publicly available at https://github.com/ Aquasar11/CER.