 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2I-FineEval: Fine-Grained Compositional Metric for Text-to-Image Evaluation
Mar 14, 2025



Although recent text-to-image generative models have achieved impressive performance, they still often struggle with capturing the compositional complexities of prompts including attribute binding, and spatial relationships between different entities. This misalignment is not revealed by common evaluation metrics such as CLIPScore. Recent works have proposed evaluation metrics that utilize Visual Question Answering (VQA) by decomposing prompts into questions about the generated image for more robust compositional evaluation. Although these methods align better with human evaluations, they still fail to fully cover the compositionality within the image. To address this, we propose a novel metric that breaks down images into components, and texts into fine-grained questions about the generated image for evaluation. Our method outperforms previous state-of-the-art metrics, demonstrating its effectiveness in evaluating text-to-image generative models. Code is available at https://github.com/hadi-hosseini/ T2I-FineEval.
Fine-Grained Alignment and Noise Refinement for Compositional Text-to-Image Generation
Mar 09, 2025
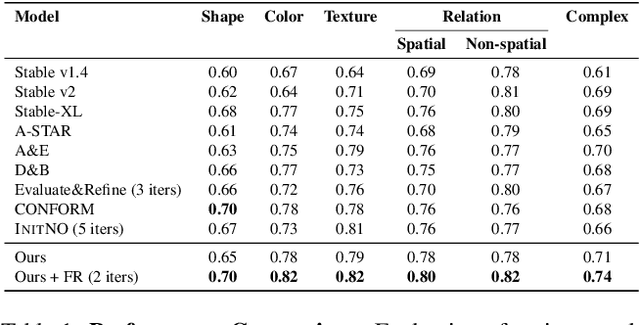
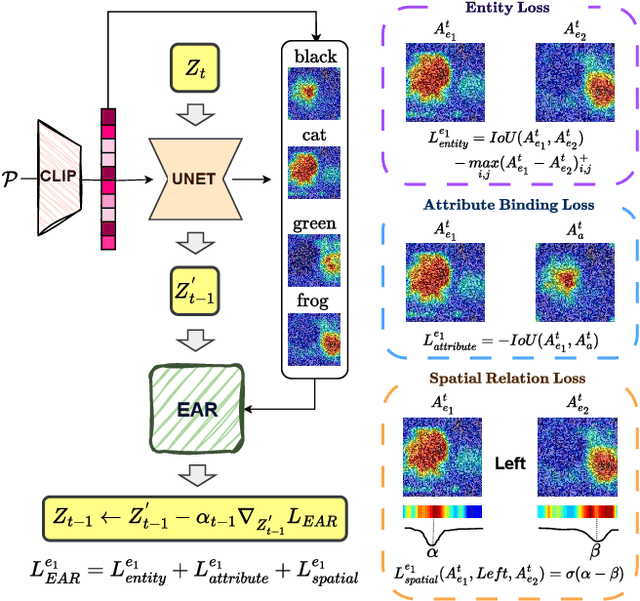

Text-to-image generative models have made significant advancements in recent years; however, accurately capturing intricate details in textual prompts, such as entity missing, attribute binding errors, and incorrect relationships remains a formidable challenge. In response, we present an innovative, training-free method that directly addresses these challenges by incorporating tailored objectives to account for textual constraints. Unlike layout-based approaches that enforce rigid structures and limit diversity, our proposed approach offers a more flexible arrangement of the scene by imposing just the extracted constraints from the text, without any unnecessary additions. These constraints are formulated as losses-entity missing, entity mixing, attribute binding, and spatial relationships, integrated into a unified loss that is applied in the first generation stage. Furthermore, we introduce a feedback-driven system for fine-grained initial noise refinement. This system integrates a verifier that evaluates the generated image, identifies inconsistencies, and provides corrective feedback. Leveraging this feedback, our refinement method first targets the unmet constraints by refining the faulty attention maps caused by initial noise, through the optimization of selective losses associated with these constraints. Subsequently, our unified loss function is reapplied to proceed the second generation phase. Experimental results demonstrate that our method, relying solely on our proposed objective functions, significantly enhances compositionality, achieving a 24% improvement in human evaluation and a 25% gain in spatial relationships. Furthermore, our fine-grained noise refinement proves effective, boosting performance by up to 5%. Code is available at https://github.com/hadi-hosseini/noise-refinement.