 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Agent-Controller: A Universal Multi-Agent Large Language Model System as a Control Engineer
May 26, 2025This study presents the LLM-Agent-Controller, a multi-agent large language model (LLM) system developed to address a wide range of problems in control engineering (Control Theory). The system integrates a central controller agent with multiple specialized auxiliary agents, responsible for tasks such as controller design, model representation, control analysis, time-domain response, and simulation. A supervisor oversees high-level decision-making and workflow coordination, enhancing the system's reliability and efficiency. The LLM-Agent-Controller incorporates advanced capabilities, including Retrieval-Augmented Generation (RAG), Chain-of-Thought reasoning, self-criticism and correction, efficient memory handling, and user-friendly natural language communication. It is designed to function without requiring users to have prior knowledge of Control Theory, enabling them to input problems in plain language and receive complete, real-time solutions. To evaluate the system, we propose new performance metrics assessing both individual agents and the system as a whole. We test five categories of Control Theory problems and benchmark performance across three advanced LLMs. Additionally, we conduct a comprehensive qualitative conversational analysis covering all key services. Results show that the LLM-Agent-Controller successfully solved 83% of general tasks, with individual agents achieving an average success rate of 87%. Performance improved with more advanced LLMs. This research demonstrates the potential of multi-agent LLM architectures to solve complex, domain-specific problems. By integrating specialized agents, supervisory control, and advanced reasoning, the LLM-Agent-Controller offers a scalable, robust, and accessible solution framework that can be extended to various technical domains.
ISLR101: an Iranian Word-Level Sign Language Recognition Dataset
Mar 16, 2025


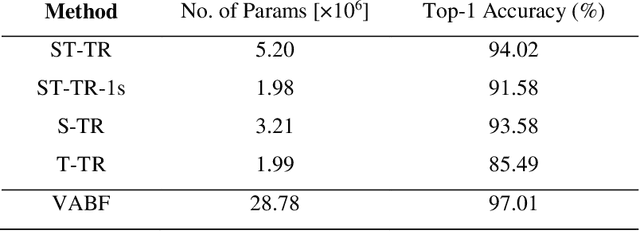
Sign language recognition involves modeling complex multichannel information, such as hand shapes and movements while relying on sufficient sign language-specific data. However, sign languages are often under-resourced, posing a significant challenge for research and development in this field. To address this gap, we introduce ISLR101, the first publicly available Iranian Sign Language dataset for isolated sign language recognition. This comprehensive dataset includes 4,614 videos covering 101 distinct signs, recorded by 10 different signers (3 deaf individuals, 2 sign language interpreters, and 5 L2 learners) against varied backgrounds, with a resolution of 800x600 pixels and a frame rate of 25 frames per second. It also includes skeleton pose information extracted using OpenPose. We establish both a visual appearance-based and a skeleton-based framework as baseline models, thoroughly training and evaluating them on ISLR101. These models achieve 97.01% and 94.02% accuracy on the test set, respectively. Additionally, we publish the train, validation, and test splits to facilitate fair comparisons.
Continuous Sign Language Recognition Using Intra-inter Gloss Attention
Jun 26, 2024Many continuous sign language recognition (CSLR) studies adopt transformer-based architectures for sequence modeling due to their powerful capacity for capturing global contexts. Nevertheless, vanilla self-attention, which serves as the core module of the transformer, calculates a weighted average over all time steps; therefore, the local temporal semantics of sign videos may not be fully exploited. In this study, we introduce a novel module in sign language recognition studies, called intra-inter gloss attention module, to leverage the relationships among frames within glosses and the semantic and grammatical dependencies between glosses in the video. In the intra-gloss attention module, the video is divided into equally sized chunks and a self-attention mechanism is applied within each chunk. This localized self-attention significantly reduces complexity and eliminates noise introduced by considering non-relative frames. In the inter-gloss attention module, we first aggregate the chunk-level features within each gloss chunk by average pooling along the temporal dimension. Subsequently, multi-head self-attention is applied to all chunk-level features. Given the non-significance of the signer-environment interaction, we utilize segmentation to remove the background of the videos. This enables the proposed model to direct its focus toward the signer. Experimental results on the PHOENIX-2014 benchmark dataset demonstrate that our method can effectively extract sign language features in an end-to-end manner without any prior knowledge, improve the accuracy of CSLR, and achieve the word error rate (WER) of 20.4 on the test set which is a competitive result compare to the state-of-the-art which uses additional supervisions.
Reacting like Humans: Incorporating Intrinsic Human Behaviors into NAO through Sound-Based Reactions for Enhanced Sociability
Dec 12, 2023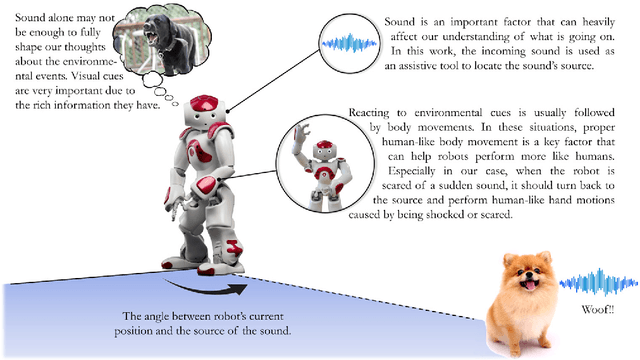

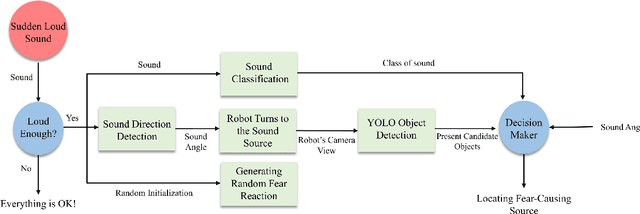

Robots' acceptability among humans and their sociability can be significantly enhanced by incorporating human-like reactions. Humans can react to environmental events very quickly and without thinking. An instance where humans display natural reactions is when they encounter a sudden and loud sound that startles or frightens them. During such moments, individuals may instinctively move their hands, turn toward the origin of the sound, and try to determine the event's cause. This inherent behavior motivated us to explore this less-studied part of social robotics. In this work, a multi-modal system composed of an action generator, sound classifier, and YOLO object detector was designed to sense the environment and, in the presence of sudden loud sounds, show natural human fear reactions, and finally, locate the fear-causing sound source in the environment. These unique and valid generated motions and inferences could imitate intrinsic human reactions and enhance the sociability of robots. For motion generation, a model based on LSTM and MDN networks was proposed to synthesize various motions. Also, in the case of sound detection, a transfer learning model was preferred that used the spectrogram of sound signals as its input. After developing individual models for sound detection, motion generation, and image recognition, they were integrated into a comprehensive fear module that was implemented on the NAO robot. Finally, the fear module was tested in practical application and two groups of experts and non-experts filled out a questionnaire to evaluate the performance of the robot. Given our promising results, this preliminary exploratory research provides a fresh perspective on social robotics and could be a starting point for modeling intrinsic human behaviors and emotions in robots.
cGAN-Based High Dimensional IMU Sensor Data Generation for Therapeutic Activities
Feb 16, 2023Human activity recognition is a core technology for applications such as rehabilitation, ambient health monitoring, and human-computer interactions. Wearable devices, particularly IMU sensors, can help us collect rich features of human movements that can be leveraged in activity recognition. Developing a robust classifier for activity recognition has always been of interest to researchers. One major problem is that there is usually a deficit of training data for some activities, making it difficult and sometimes impossible to develop a classifier. In this work, a novel GAN network called TheraGAN was developed to generate realistic IMU signals associated with a particular activity. The generated signal is of a 6-channel IMU. i.e., angular velocities and linear accelerations. Also, by introducing simple activities, which are meaningful subparts of a complex full-length activity, the generation process was facilitated for any activity with arbitrary length. To evaluate the generated signals, besides perceptual similarity metrics, they were applied along with real data to improve the accuracy of classifiers. The results show that the maximum increase in the f1-score belongs to the LSTM classifier by a 13.27% rise when generated data were added. This shows the validity of the generated data as well as TheraGAN as a tool to build more robust classifiers in case of imbalanced data problem.