 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeISLR101: an Iranian Word-Level Sign Language Recognition Dataset
Mar 16, 2025


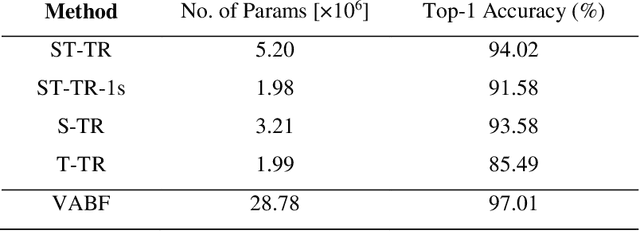
Sign language recognition involves modeling complex multichannel information, such as hand shapes and movements while relying on sufficient sign language-specific data. However, sign languages are often under-resourced, posing a significant challenge for research and development in this field. To address this gap, we introduce ISLR101, the first publicly available Iranian Sign Language dataset for isolated sign language recognition. This comprehensive dataset includes 4,614 videos covering 101 distinct signs, recorded by 10 different signers (3 deaf individuals, 2 sign language interpreters, and 5 L2 learners) against varied backgrounds, with a resolution of 800x600 pixels and a frame rate of 25 frames per second. It also includes skeleton pose information extracted using OpenPose. We establish both a visual appearance-based and a skeleton-based framework as baseline models, thoroughly training and evaluating them on ISLR101. These models achieve 97.01% and 94.02% accuracy on the test set, respectively. Additionally, we publish the train, validation, and test splits to facilitate fair comparisons.
Multimodal Emotion Recognition and Sentiment Analysis in Multi-Party Conversation Contexts
Mar 09, 2025Emotion recognition and sentiment analysis are pivotal tasks in speech and language processing, particularly in real-world scenarios involving multi-party, conversational data. This paper presents a multimodal approach to tackle these challenges on a well-known dataset. We propose a system that integrates four key modalities/channels using pre-trained models: RoBERTa for text, Wav2Vec2 for speech, a proposed FacialNet for facial expressions, and a CNN+Transformer architecture trained from scratch for video analysis. Feature embeddings from each modality are concatenated to form a multimodal vector, which is then used to predict emotion and sentiment labels. The multimodal system demonstrates superior performance compared to unimodal approaches, achieving an accuracy of 66.36% for emotion recognition and 72.15% for sentiment analysis.
Two-Stream Spatial-Temporal Transformer Framework for Person Identification via Natural Conversational Keypoints
Feb 28, 2025



In the age of AI-driven generative technologies, traditional biometric recognition systems face unprecedented challenges, particularly from sophisticated deepfake and face reenactment techniques. In this study, we propose a Two-Stream Spatial-Temporal Transformer Framework for person identification using upper body keypoints visible during online conversations, which we term conversational keypoints. Our framework processes both spatial relationships between keypoints and their temporal evolution through two specialized branches: a Spatial Transformer (STR) that learns distinctive structural patterns in keypoint configurations, and a Temporal Transformer (TTR) that captures sequential motion patterns. Using the state-of-the-art Sapiens pose estimator, we extract 133 keypoints (based on COCO-WholeBody format) representing facial features, head pose, and hand positions. The framework was evaluated on a dataset of 114 individuals engaged in natural conversations, achieving recognition accuracies of 80.12% for the spatial stream, 63.61% for the temporal stream. We then explored two fusion strategies: a shared loss function approach achieving 82.22% accuracy, and a feature-level fusion method that concatenates feature maps from both streams, significantly improving performance to 94.86%. By jointly modeling both static anatomical relationships and dynamic movement patterns, our approach learns comprehensive identity signatures that are more robust to spoofing than traditional appearance-based methods.
Continuous Sign Language Recognition Using Intra-inter Gloss Attention
Jun 26, 2024Many continuous sign language recognition (CSLR) studies adopt transformer-based architectures for sequence modeling due to their powerful capacity for capturing global contexts. Nevertheless, vanilla self-attention, which serves as the core module of the transformer, calculates a weighted average over all time steps; therefore, the local temporal semantics of sign videos may not be fully exploited. In this study, we introduce a novel module in sign language recognition studies, called intra-inter gloss attention module, to leverage the relationships among frames within glosses and the semantic and grammatical dependencies between glosses in the video. In the intra-gloss attention module, the video is divided into equally sized chunks and a self-attention mechanism is applied within each chunk. This localized self-attention significantly reduces complexity and eliminates noise introduced by considering non-relative frames. In the inter-gloss attention module, we first aggregate the chunk-level features within each gloss chunk by average pooling along the temporal dimension. Subsequently, multi-head self-attention is applied to all chunk-level features. Given the non-significance of the signer-environment interaction, we utilize segmentation to remove the background of the videos. This enables the proposed model to direct its focus toward the signer. Experimental results on the PHOENIX-2014 benchmark dataset demonstrate that our method can effectively extract sign language features in an end-to-end manner without any prior knowledge, improve the accuracy of CSLR, and achieve the word error rate (WER) of 20.4 on the test set which is a competitive result compare to the state-of-the-art which uses additional supervisions.