 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheXmask-U: Quantifying uncertainty in landmark-based anatomical segmentation for X-ray images
Dec 11, 2025Uncertainty estimation is essential for the safe clinical deployment of medical image segmentation systems, enabling the identification of unreliable predictions and supporting human oversight. While prior work has largely focused on pixel-level uncertainty, landmark-based segmentation offers inherent topological guarantees yet remains underexplored from an uncertainty perspective. In this work, we study uncertainty estimation for anatomical landmark-based segmentation on chest X-rays. Inspired by hybrid neural network architectures that combine standard image convolutional encoders with graph-based generative decoders, and leveraging their variational latent space, we derive two complementary measures: (i) latent uncertainty, captured directly from the learned distribution parameters, and (ii) predictive uncertainty, obtained by generating multiple stochastic output predictions from latent samples. Through controlled corruption experiments we show that both uncertainty measures increase with perturbation severity, reflecting both global and local degradation. We demonstrate that these uncertainty signals can identify unreliable predictions by comparing with manual ground-truth, and support out-of-distribution detection on the CheXmask dataset. More importantly, we release CheXmask-U (huggingface.co/datasets/mcosarinsky/CheXmask-U), a large scale dataset of 657,566 chest X-ray landmark segmentations with per-node uncertainty estimates, enabling researchers to account for spatial variations in segmentation quality when using these anatomical masks. Our findings establish uncertainty estimation as a promising direction to enhance robustness and safe deployment of landmark-based anatomical segmentation methods in chest X-ray. A fully working interactive demo of the method is available at huggingface.co/spaces/matiasky/CheXmask-U and the source code at github.com/mcosarinsky/CheXmask-U.
Fairness of Deep Ensembles: On the interplay between per-group task difficulty and under-representation
Jan 24, 2025



Ensembling is commonly regarded as an effective way to improve the general performance of models in machine learning, while also increasing the robustness of predictions. When it comes to algorithmic fairness, heterogeneous ensembles, composed of multiple model types, have been employed to mitigate biases in terms of demographic attributes such as sex, age or ethnicity. Moreover, recent work has shown how in multi-class problems even simple homogeneous ensembles may favor performance of the worst-performing target classes. While homogeneous ensembles are simpler to implement in practice, it is not yet clear whether their benefits translate to groups defined not in terms of their target class, but in terms of demographic or protected attributes, hence improving fairness. In this work we show how this simple and straightforward method is indeed able to mitigate disparities, particularly benefiting under-performing subgroups. Interestingly, this can be achieved without sacrificing overall performance, which is a common trade-off observed in bias mitigation strategies. Moreover, we analyzed the interplay between two factors which may result in biases: sub-group under-representation and the inherent difficulty of the task for each group. These results revealed that, contrary to popular assumptions, having balanced datasets may be suboptimal if the task difficulty varies between subgroups. Indeed, we found that a perfectly balanced dataset may hurt both the overall performance and the gap between groups. This highlights the importance of considering the interaction between multiple forces at play in fairness.
Open Challenges on Fairness of Artificial Intelligence in Medical Imaging Applications
Jul 24, 2024Recently, the research community of computerized medical imaging has started to discuss and address potential fairness issues that may emerge when developing and deploying AI systems for medical image analysis. This chapter covers some of the pressing challenges encountered when doing research in this area, and it is intended to raise questions and provide food for thought for those aiming to enter this research field. The chapter first discusses various sources of bias, including data collection, model training, and clinical deployment, and their impact on the fairness of machine learning algorithms in medical image computing. We then turn to discussing open challenges that we believe require attention from researchers and practitioners, as well as potential pitfalls of naive application of common methods in the field. We cover a variety of topics including the impact of biased metrics when auditing for fairness, the leveling down effect, task difficulty variations among subgroups, discovering biases in unseen populations, and explaining biases beyond standard demographic attributes.
Uncertainty in latent representations of variational autoencoders optimized for visual tasks
Apr 23, 2024



Deep learning methods are increasingly becoming instrumental as modeling tools in computational neuroscience, employing optimality principles to build bridges between neural responses and perception or behavior. Developing models that adequately represent uncertainty is however challenging for deep learning methods, which often suffer from calibration problems. This constitutes a difficulty in particular when modeling cortical circuits in terms of Bayesian inference, beyond single point estimates such as the posterior mean or the maximum a posteriori. In this work we systematically studied uncertainty representations in latent representations of variational auto-encoders (VAEs), both in a perceptual task from natural images and in two other canonical tasks of computer vision, finding a poor alignment between uncertainty and informativeness or ambiguities in the images. We next showed how a novel approach which we call explaining-away variational auto-encoders (EA-VAEs), fixes these issues, producing meaningful reports of uncertainty in a variety of scenarios, including interpolation, image corruption, and even out-of-distribution detection. We show EA-VAEs may prove useful both as models of perception in computational neuroscience and as inference tools in computer vision.
Unsupervised bias discovery in medical image segmentation
Sep 01, 2023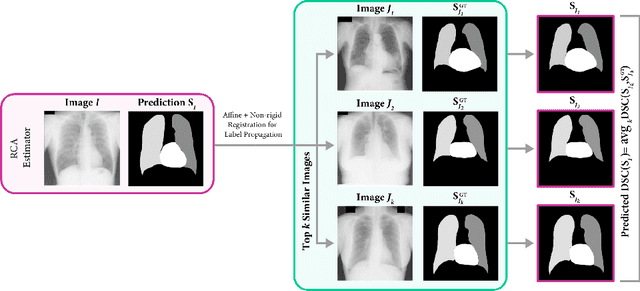
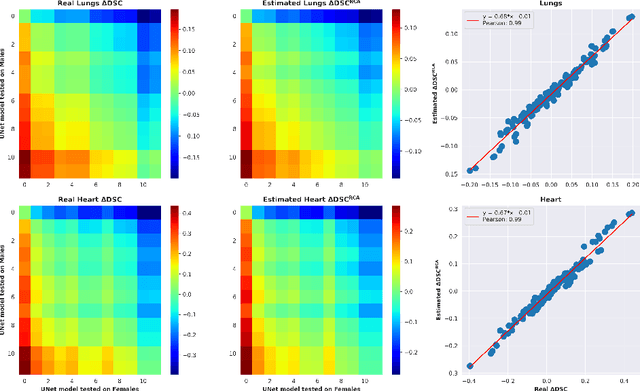
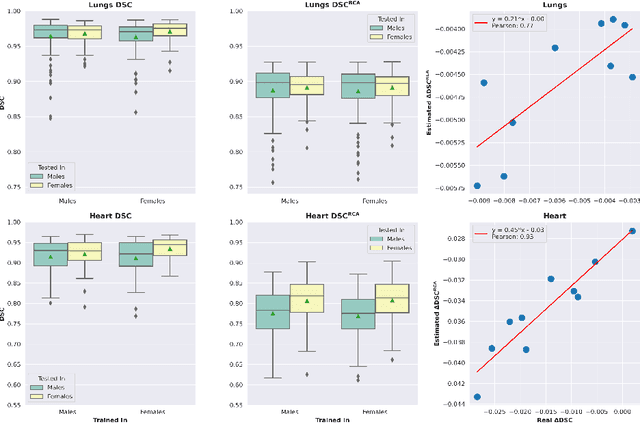
It has recently been shown that deep learning models for anatomical segmentation in medical images can exhibit biases against certain sub-populations defined in terms of protected attributes like sex or ethnicity. In this context, auditing fairness of deep segmentation models becomes crucial. However, such audit process generally requires access to ground-truth segmentation masks for the target population, which may not always be available, especially when going from development to deployment. Here we propose a new method to anticipate model biases in biomedical image segmentation in the absence of ground-truth annotations. Our unsupervised bias discovery method leverages the reverse classification accuracy framework to estimate segmentation quality. Through numerical experiments in synthetic and realistic scenarios we show how our method is able to successfully anticipate fairness issues in the absence of ground-truth labels, constituting a novel and valuable tool in this field.
Towards unraveling calibration biases in medical image analysis
May 09, 2023


In recent years the development of artificial intelligence (AI) systems for automated medical image analysis has gained enormous momentum. At the same time, a large body of work has shown that AI systems can systematically and unfairly discriminate against certain populations in various application scenarios. These two facts have motivated the emergence of algorithmic fairness studies in this field. Most research on healthcare algorithmic fairness to date has focused on the assessment of biases in terms of classical discrimination metrics such as AUC and accuracy. Potential biases in terms of model calibration, however, have only recently begun to be evaluated. This is especially important when working with clinical decision support systems, as predictive uncertainty is key for health professionals to optimally evaluate and combine multiple sources of information. In this work we study discrimination and calibration biases in models trained for automatic detection of malignant dermatological conditions from skin lesions images. Importantly, we show how several typically employed calibration metrics are systematically biased with respect to sample sizes, and how this can lead to erroneous fairness analysis if not taken into consideration. This is of particular relevance to fairness studies, where data imbalance results in drastic sample size differences between demographic sub-groups, which, if not taken into account, can act as confounders.
Domain Generalization via Gradient Surgery
Aug 03, 2021
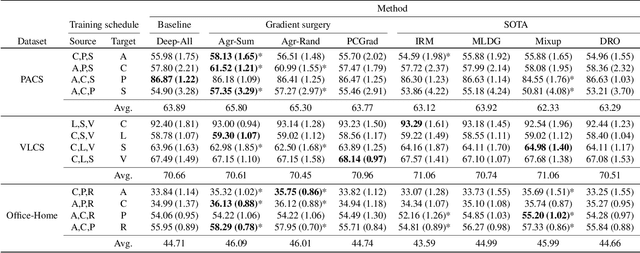
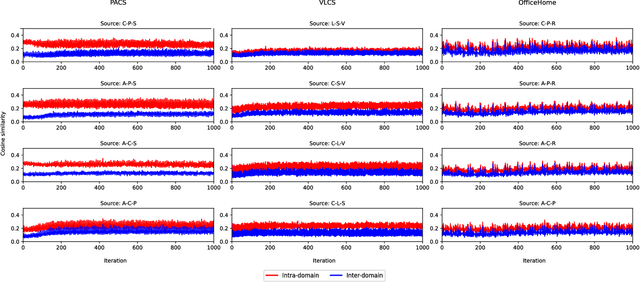
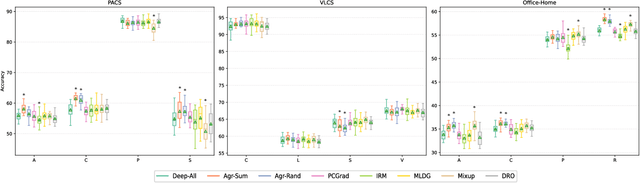
In real-life applications, machine learning models often face scenarios where there is a change in data distribution between training and test domains. When the aim is to make predictions on distributions different from those seen at training, we incur in a domain generalization problem. Methods to address this issue learn a model using data from multiple source domains, and then apply this model to the unseen target domain. Our hypothesis is that when training with multiple domains, conflicting gradients within each mini-batch contain information specific to the individual domains which is irrelevant to the others, including the test domain. If left untouched, such disagreement may degrade generalization performance. In this work, we characterize the conflicting gradients emerging in domain shift scenarios and devise novel gradient agreement strategies based on gradient surgery to alleviate their effect. We validate our approach in image classification tasks with three multi-domain datasets, showing the value of the proposed agreement strategy in enhancing the generalization capability of deep learning models in domain shift scenarios.
Generating functionals for computational intelligence: the Fisher information as an objective function for self-limiting Hebbian learning rules
Oct 02, 2014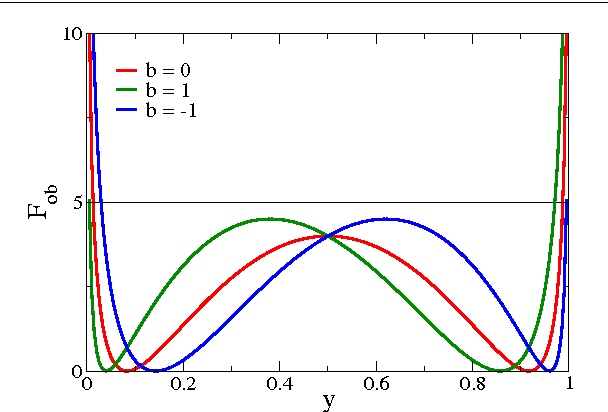
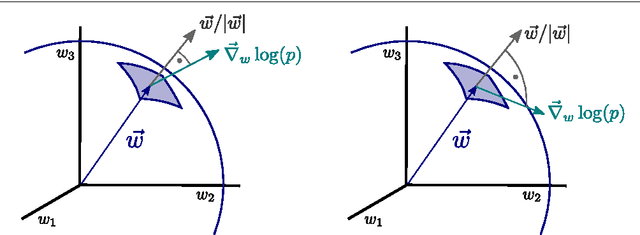
Generating functionals may guide the evolution of a dynamical system and constitute a possible route for handling the complexity of neural networks as relevant for computational intelligence. We propose and explore a new objective function, which allows to obtain plasticity rules for the afferent synaptic weights. The adaption rules are Hebbian, self-limiting, and result from the minimization of the Fisher information with respect to the synaptic flux. We perform a series of simulations examining the behavior of the new learning rules in various circumstances. The vector of synaptic weights aligns with the principal direction of input activities, whenever one is present. A linear discrimination is performed when there are two or more principal directions; directions having bimodal firing-rate distributions, being characterized by a negative excess kurtosis, are preferred. We find robust performance and full homeostatic adaption of the synaptic weights results as a by-product of the synaptic flux minimization. This self-limiting behavior allows for stable online learning for arbitrary durations. The neuron acquires new information when the statistics of input activities is changed at a certain point of the simulation, showing however, a distinct resilience to unlearn previously acquired knowledge. Learning is fast when starting with randomly drawn synaptic weights and substantially slower when the synaptic weights are already fully adapted.