 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2.5-dimensional distributed model training
Paper and Code
May 30, 2021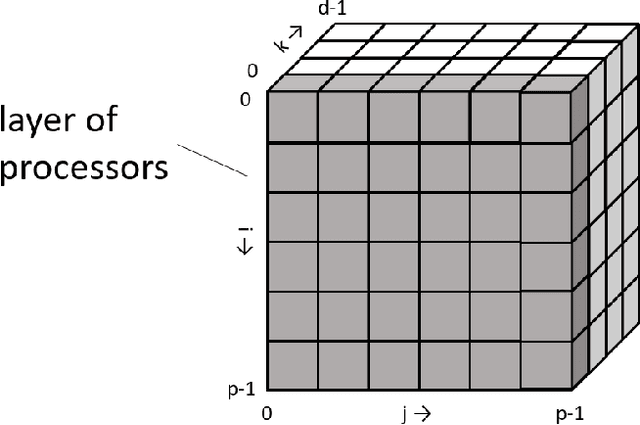
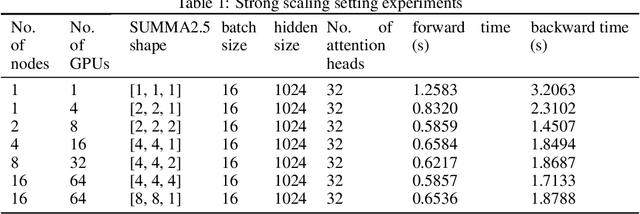
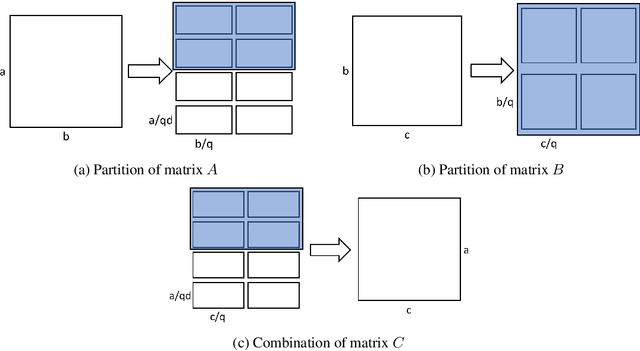
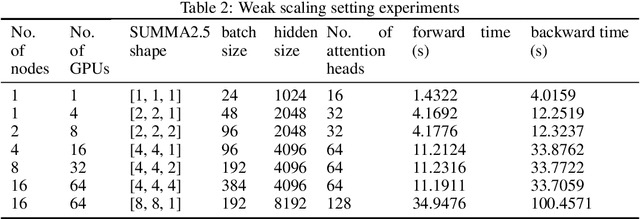
Data parallelism does a good job in speeding up the training. However, when it comes to the case when the memory of a single device can not host a whole model, data parallelism would not have the chance to do anything. Another option is to split the model by operator, or horizontally. Megatron-LM introduced a 1-Dimensional distributed method to use GPUs to speed up the training process. Optimus is a 2D solution for distributed tensor parallelism. However, these methods have a high communication overhead and a low scaling efficiency on large-scale computing clusters. To solve this problem, we investigate the 2.5-Dimensional distributed tensor parallelism.Introduced by Solomonik et al., 2.5-Dimensional Matrix Multiplication developed an effective method to perform multiple Cannon's algorithm at the same time to increase the efficiency. With many restrictions of Cannon's Algorithm and a huge amount of shift operation, we need to invent a new method of 2.5-dimensional matrix multiplication to enhance the performance. Absorbing the essence from both SUMMA and 2.5-Dimensional Matrix Multiplication, we introduced SUMMA2.5-LM for language models to overcome the abundance of unnecessary transmission loss result from the increasing size of language model parallelism. Compared to previous 1D and 2D model parallelization of language models, our SUMMA2.5-LM managed to reduce the transmission cost on each layer, which could get a 1.45X efficiency according to our weak scaling result between 2.5-D [4,4,4] arrangement and 2-D [8,8,1] arrangement.