 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColossal-Auto: Unified Automation of Parallelization and Activation Checkpoint for Large-scale Models
Paper and Code
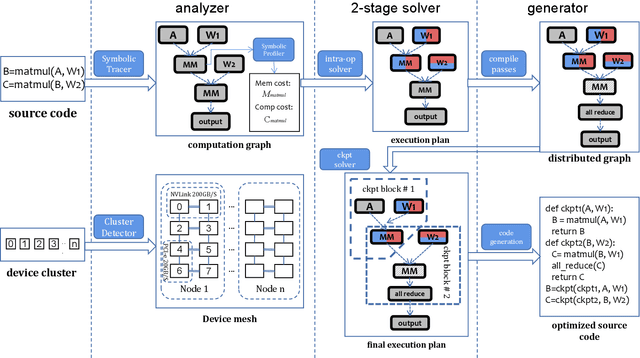
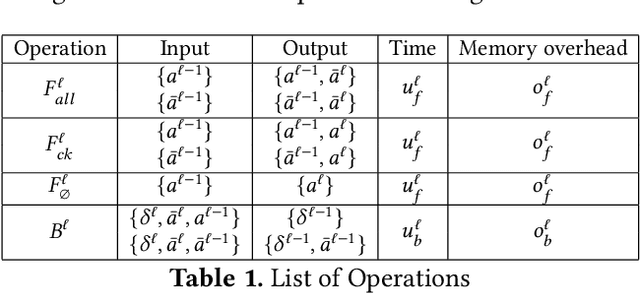
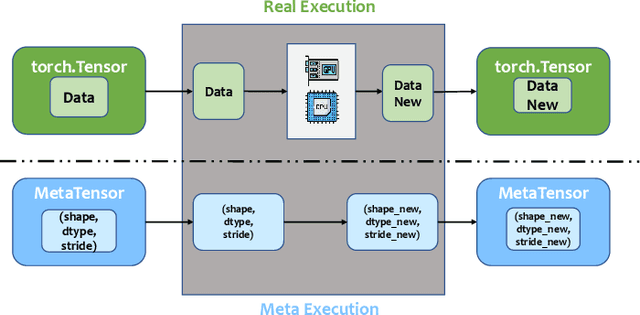

In recent years, large-scale models have demonstrated state-of-the-art performance across various domains. However, training such models requires various techniques to address the problem of limited computing power and memory on devices such as GPUs. Some commonly used techniques include pipeline parallelism, tensor parallelism, and activation checkpointing. While existing works have focused on finding efficient distributed execution plans (Zheng et al. 2022) and activation checkpoint scheduling (Herrmann et al. 2019, Beaumont et al. 2021}, there has been no method proposed to optimize these two plans jointly. Moreover, ahead-of-time compilation relies heavily on accurate memory and computing overhead estimation, which is often time-consuming and misleading. Existing training systems and machine learning pipelines either physically execute each operand or estimate memory usage with a scaled input tensor. To address these challenges, we introduce a system that can jointly optimize distributed execution and gradient checkpointing plans. Additionally, we provide an easy-to-use symbolic profiler that generates memory and computing statistics for any PyTorch model with a minimal time cost. Our approach allows users to parallelize their model training on the given hardware with minimum code change based. The source code is publicly available at Colossal-AI GitHub or https://github.com/hpcaitech/ColossalAI