 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLT-Dedup: Efficient Large-Scale Online Video Deduplication via Multi-Level Representations and Spatial-Temporal Matching
Jun 10, 2026The explosive growth of user-generated video content on online platforms is accompanied by the emergence of numerous near-duplicate videos--videos that are identical or highly similar but differ by partial edits. These duplicates degrade user experience and increase storage and bandwidth costs, making large-scale video deduplication a critical task. Existing video deduplication frameworks face a fundamental challenge in retrieving sufficient high-quality candidates under a limited index budget, as well as trade-offs between efficiency and precision. To address these issues, we propose MLT-Dedup, an efficient large-scale online video deduplication framework with Multi-Level representations and spatial-Temporal matching. Our approach employs a Multi-Level Video Encoder (ML-VE) to extract both fine-grained frame-level and sparse clip-level embeddings: sparse embeddings support efficient candidate retrieval, while fine-grained embeddings are loaded for precise pairwise matching. During matching, we introduce DiF-SiM, a Differential Feature-enhanced Similarity Module capable of locating duplicated temporal segments and providing reliable similarity evidence to support policy-driven deduplication decisions. Extensive experiments on a real-world large-scale platform demonstrate that MLT-Dedup reduces online repetition rates by 91% at 90% precision. Furthermore, our sparse retrieval design achieves a 5x increase in indexing capacity, enabling broader candidate coverage in real-world deployment.
On-Policy Adversarial Flow Distillation for Autoregressive Video Generation
May 25, 2026Autoregressive video generators are attractive for streaming, long-horizon, and interactive applications, but distilling strong black-box teachers into causal students remains difficult. The student must learn under its own rollout distribution, whereas practical teachers may expose only prompt-conditioned completed videos and may differ in architecture, capacity, temporal design, and sampling schedule. This interface makes supervised fine-tuning off-policy, score-based distillation inapplicable, and direct adversarial imitation too sparse for denoising-time credit assignment. We propose Adversarial Flow Distillation (AFD), an on-policy framework for heterogeneous black-box video distillation. AFD queries the teacher and rolls out the current student on the same prompts, trains a prompt-paired Bradley-Terry discriminator to estimate clean-sample teacher-student discrepancy, and converts the resulting on-policy advantage into forward-process flow-matching updates on the student's own noised states. Thus, AFD provides dense velocity-field supervision while requiring no teacher scores, latents, denoising trajectories, step alignment, or reverse-chain reinforcement learning. Experiments across two causal AR student families show that AFD consistently improves motion- and physics-sensitive generation while preserving general video quality, and ablations validate the importance of adaptive on-policy feedback and forward-process credit assignment. The method requires only clean teacher videos and student rollouts, providing a practical route for distilling proprietary or heterogeneous video generators into efficient autoregressive students.
CAMEL: Confidence-Gated Reflection for Reward Modeling
Feb 24, 2026Reward models play a fundamental role in aligning large language models with human preferences. Existing methods predominantly follow two paradigms: scalar discriminative preference models, which are efficient but lack interpretability, and generative judging models, which offer richer reasoning at the cost of higher computational overhead. We observe that the log-probability margin between verdict tokens strongly correlates with prediction correctness, providing a reliable proxy for instance difficulty without additional inference cost. Building on this insight, we propose CAMEL, a confidence-gated reflection framework that performs a lightweight single-token preference decision first and selectively invokes reflection only for low-confidence instances. To induce effective self-correction, we train the model via reinforcement learning with counterfactual prefix augmentation, which exposes the model to diverse initial verdicts and encourages genuine revision. Empirically, CAMEL achieves state-of-the-art performance on three widely used reward-model benchmarks with 82.9% average accuracy, surpassing the best prior model by 3.2% and outperforming 70B-parameter models using only 14B parameters, while establishing a strictly better accuracy-efficiency Pareto frontier.
FOCUS: Efficient Keyframe Selection for Long Video Understanding
Oct 31, 2025Multimodal large language models (MLLMs) represent images and video frames as visual tokens. Scaling from single images to hour-long videos, however, inflates the token budget far beyond practical limits. Popular pipelines therefore either uniformly subsample or apply keyframe selection with retrieval-style scoring using smaller vision-language models. However, these keyframe selection methods still rely on pre-filtering before selection to reduce the inference cost and can miss the most informative moments. We propose FOCUS, Frame-Optimistic Confidence Upper-bound Selection, a training-free, model-agnostic keyframe selection module that selects query-relevant frames under a strict token budget. FOCUS formulates keyframe selection as a combinatorial pure-exploration (CPE) problem in multi-armed bandits: it treats short temporal clips as arms, and uses empirical means and Bernstein confidence radius to identify informative regions while preserving exploration of uncertain areas. The resulting two-stage exploration-exploitation procedure reduces from a sequential policy with theoretical guarantees, first identifying high-value temporal regions, then selecting top-scoring frames within each region On two long-video question-answering benchmarks, FOCUS delivers substantial accuracy improvements while processing less than 2% of video frames. For videos longer than 20 minutes, it achieves an 11.9% gain in accuracy on LongVideoBench, demonstrating its effectiveness as a keyframe selection method and providing a simple and general solution for scalable long-video understanding with MLLMs.
How Does the Textual Information Affect the Retrieval of Multimodal In-Context Learning?
Apr 19, 2024



The increase in parameter size of multimodal large language models (MLLMs) introduces significant capabilities, particularly in-context learning, where MLLMs enhance task performance without updating pre-trained parameters. This effectiveness, however, hinges on the appropriate selection of in-context examples, a process that is currently biased towards visual data, overlooking textual information. Furthermore, the area of supervised retrievers for MLLMs, crucial for optimal in-context example selection, continues to be uninvestigated. Our study offers an in-depth evaluation of the impact of textual information on the unsupervised selection of in-context examples in multimodal contexts, uncovering a notable sensitivity of retriever performance to the employed modalities. Responding to this, we introduce a novel supervised MLLM-retriever MSIER that employs a neural network to select examples that enhance multimodal in-context learning efficiency. This approach is validated through extensive testing across three distinct tasks, demonstrating the method's effectiveness. Additionally, we investigate the influence of modalities on our supervised retrieval method's training and pinpoint factors contributing to our model's success. This exploration paves the way for future advancements, highlighting the potential for refined in-context learning in MLLMs through the strategic use of multimodal data.
Sparse MeZO: Less Parameters for Better Performance in Zeroth-Order LLM Fine-Tuning
Feb 24, 2024



While fine-tuning large language models (LLMs) for specific tasks often yields impressive results, it comes at the cost of memory inefficiency due to back-propagation in gradient-based training. Memory-efficient Zeroth-order (MeZO) optimizers, recently proposed to address this issue, only require forward passes during training, making them more memory-friendly. However, the quality of gradient estimates in zeroth order optimization often depends on the data dimensionality, potentially explaining why MeZO still exhibits significant performance drops compared to standard fine-tuning across various tasks. Inspired by the success of Parameter-Efficient Fine-Tuning (PEFT), this paper introduces Sparse MeZO, a novel memory-efficient zeroth-order optimization approach that applies ZO only to a carefully chosen subset of parameters. We propose a simple yet effective parameter selection scheme that yields significant performance gains with Sparse-MeZO. Additionally, we develop a memory-optimized implementation for sparse masking, ensuring the algorithm requires only inference-level memory consumption, allowing Sparse-MeZO to fine-tune LLaMA-30b on a single A100 GPU. Experimental results illustrate that Sparse-MeZO consistently improves both performance and convergence speed over MeZO without any overhead. For example, it achieves a 9\% absolute accuracy improvement and 3.5x speedup over MeZO on the RTE task.
Helen: Optimizing CTR Prediction Models with Frequency-wise Hessian Eigenvalue Regularization
Feb 23, 2024



Click-Through Rate (CTR) prediction holds paramount significance in online advertising and recommendation scenarios. Despite the proliferation of recent CTR prediction models, the improvements in performance have remained limited, as evidenced by open-source benchmark assessments. Current researchers tend to focus on developing new models for various datasets and settings, often neglecting a crucial question: What is the key challenge that truly makes CTR prediction so demanding? In this paper, we approach the problem of CTR prediction from an optimization perspective. We explore the typical data characteristics and optimization statistics of CTR prediction, revealing a strong positive correlation between the top hessian eigenvalue and feature frequency. This correlation implies that frequently occurring features tend to converge towards sharp local minima, ultimately leading to suboptimal performance. Motivated by the recent advancements in sharpness-aware minimization (SAM), which considers the geometric aspects of the loss landscape during optimization, we present a dedicated optimizer crafted for CTR prediction, named Helen. Helen incorporates frequency-wise Hessian eigenvalue regularization, achieved through adaptive perturbations based on normalized feature frequencies. Empirical results under the open-source benchmark framework underscore Helen's effectiveness. It successfully constrains the top eigenvalue of the Hessian matrix and demonstrates a clear advantage over widely used optimization algorithms when applied to seven popular models across three public benchmark datasets on BARS. Our code locates at github.com/NUS-HPC-AI-Lab/Helen.
Grasp Stability Prediction with Sim-to-Real Transfer from Tactile Sensing
Aug 04, 2022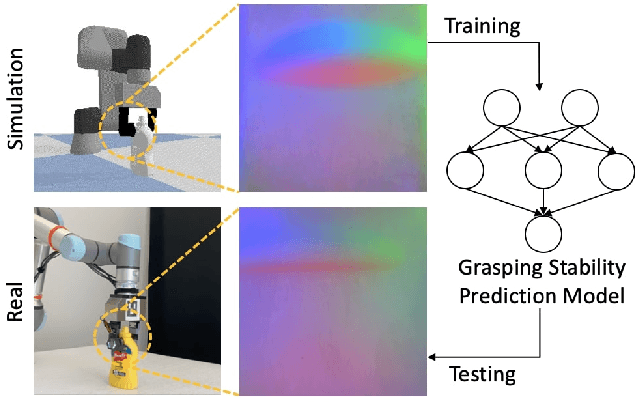
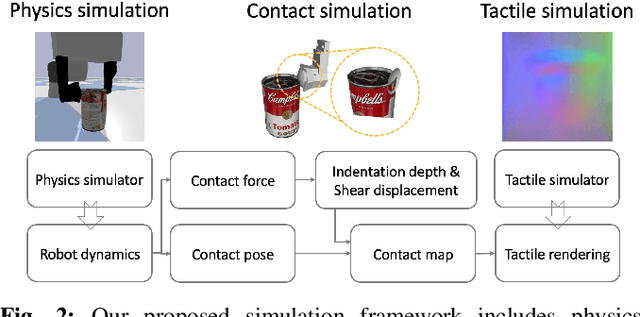
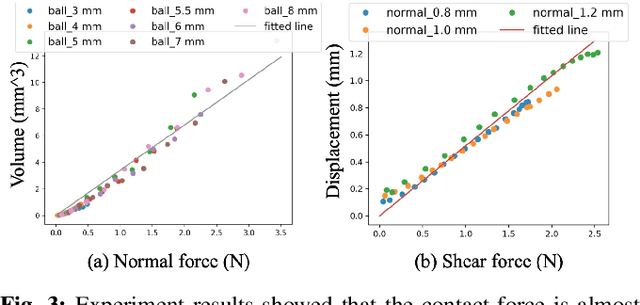
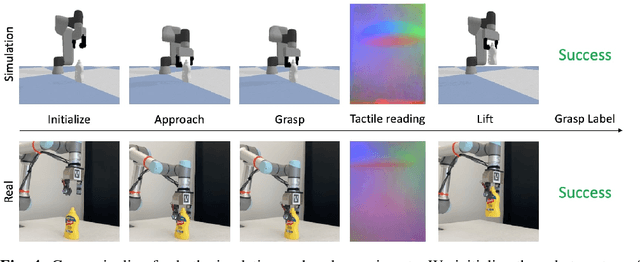
Robot simulation has been an essential tool for data-driven manipulation tasks. However, most existing simulation frameworks lack either efficient and accurate models of physical interactions with tactile sensors or realistic tactile simulation. This makes the sim-to-real transfer for tactile-based manipulation tasks still challenging. In this work, we integrate simulation of robot dynamics and vision-based tactile sensors by modeling the physics of contact. This contact model uses simulated contact forces at the robot's end-effector to inform the generation of realistic tactile outputs. To eliminate the sim-to-real transfer gap, we calibrate our physics simulator of robot dynamics, contact model, and tactile optical simulator with real-world data, and then we demonstrate the effectiveness of our system on a zero-shot sim-to-real grasp stability prediction task where we achieve an average accuracy of 90.7% on various objects. Experiments reveal the potential of applying our simulation framework to more complicated manipulation tasks. We open-source our simulation framework at https://github.com/CMURoboTouch/Taxim/tree/taxim-robot.
Inhomogeneous Social Recommendation with Hypergraph Convolutional Networks
Nov 05, 2021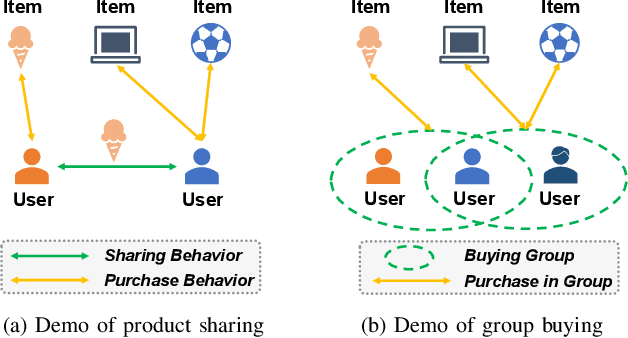
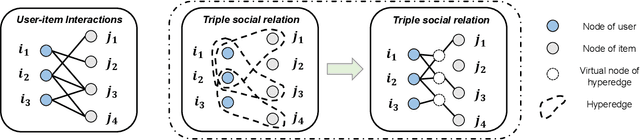
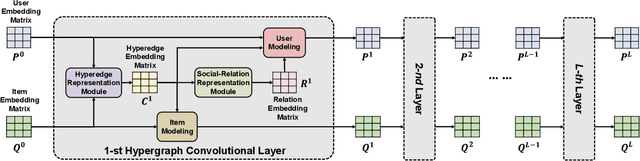
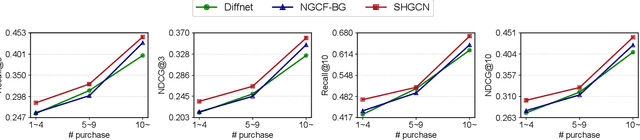
Incorporating social relations into the recommendation system, i.e. social recommendation, has been widely studied in academic and industrial communities. While many promising results have been achieved, existing methods mostly assume that the social relations can be homogeneously applied to all the items, which is not practical for users' actually diverse preferences. In this paper, we argue that the effect of the social relations should be inhomogeneous, that is, two socially-related users may only share the same preference on some specific items, while for the other products, their preferences can be inconsistent or even contradictory. Inspired by this idea, we build a novel social recommendation model, where the traditional pair-wise "user-user'' relation is extended to the triple relation of "user-item-user''. To well handle such high-order relations, we base our framework on the hypergraph. More specifically, each hyperedge connects a user-user-item triplet, representing that the two users share similar preferences on the item. We develop a Social HyperGraph Convolutional Network (short for SHGCN) to learn from the complex triplet social relations. With the hypergraph convolutional networks, the social relations can be modeled in a more fine-grained manner, which more accurately depicts real users' preferences, and benefits the recommendation performance. Extensive experiments on two real-world datasets demonstrate our model's effectiveness. Studies on data sparsity and hyper-parameter studies further validate our model's rationality. Our codes and dataset are available at https://github.com/ziruizhu/SHGCN.
Towards More Efficient Federated Learning with Better Optimization Objects
Aug 19, 2021



Federated Learning (FL) is a privacy-protected machine learning paradigm that allows model to be trained directly at the edge without uploading data. One of the biggest challenges faced by FL in practical applications is the heterogeneity of edge node data, which will slow down the convergence speed and degrade the performance of the model. For the above problems, a representative solution is to add additional constraints in the local training, such as FedProx, FedCurv and FedCL. However, the above algorithms still have room for improvement. We propose to use the aggregation of all models obtained in the past as new constraint target to further improve the performance of such algorithms. Experiments in various settings demonstrate that our method significantly improves the convergence speed and performance of the model.