 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceInsight: A Multimodal Large Language Model for Face Perception
Paper and Code
Apr 22, 2025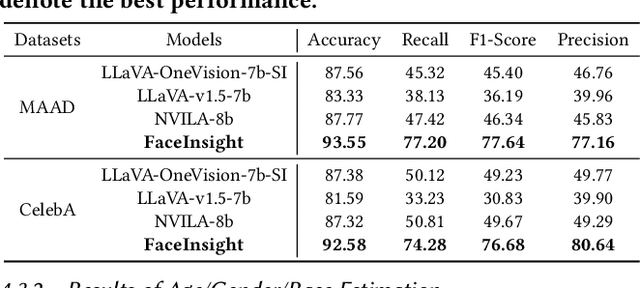
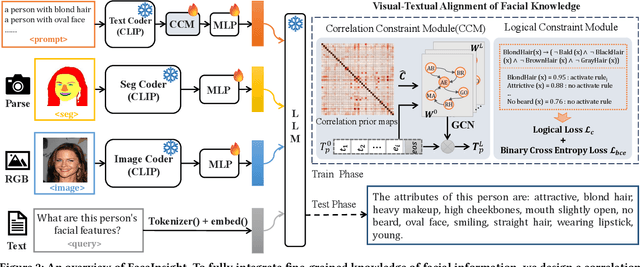
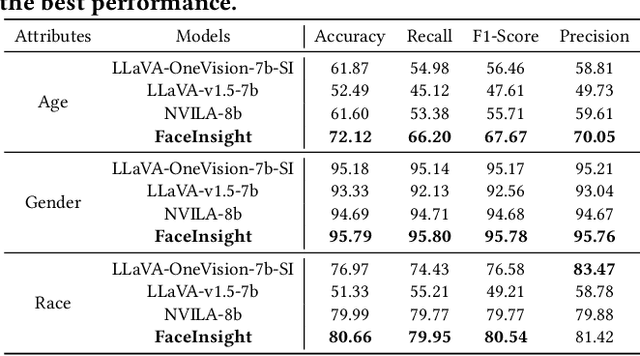
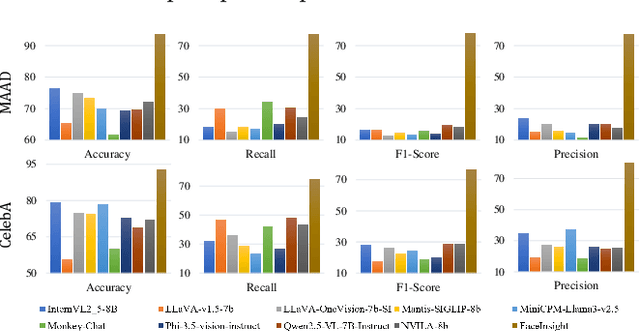
Recent advances in multimodal large language models (MLLMs) have demonstrated strong capabilities in understanding general visual content. However, these general-domain MLLMs perform poorly in face perception tasks, often producing inaccurate or misleading responses to face-specific queries. To address this gap, we propose FaceInsight, the versatile face perception MLLM that provides fine-grained facial information. Our approach introduces visual-textual alignment of facial knowledge to model both uncertain dependencies and deterministic relationships among facial information, mitigating the limitations of language-driven reasoning. Additionally, we incorporate face segmentation maps as an auxiliary perceptual modality, enriching the visual input with localized structural cues to enhance semantic understanding. Comprehensive experiments and analyses across three face perception tasks demonstrate that FaceInsight consistently outperforms nine compared MLLMs under both training-free and fine-tuned settings.