 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenCAMO: Scene-Graph Contextual Decoupling for Environment-aware and Mask-free Camouflage Image-Dense Annotation Generation
Jan 03, 2026Conceal dense prediction (CDP), especially RGB-D camouflage object detection and open-vocabulary camouflage object segmentation, plays a crucial role in advancing the understanding and reasoning of complex camouflage scenes. However, high-quality and large-scale camouflage datasets with dense annotation remain scarce due to expensive data collection and labeling costs. To address this challenge, we explore leveraging generative models to synthesize realistic camouflage image-dense data for training CDP models with fine-grained representations, prior knowledge, and auxiliary reasoning. Concretely, our contributions are threefold: (i) we introduce GenCAMO-DB, a large-scale camouflage dataset with multi-modal annotations, including depth maps, scene graphs, attribute descriptions, and text prompts; (ii) we present GenCAMO, an environment-aware and mask-free generative framework that produces high-fidelity camouflage image-dense annotations; (iii) extensive experiments across multiple modalities demonstrate that GenCAMO significantly improves dense prediction performance on complex camouflage scenes by providing high-quality synthetic data. The code and datasets will be released after paper acceptance.
Raw Text is All you Need: Knowledge-intensive Multi-turn Instruction Tuning for Large Language Model
Jul 03, 2024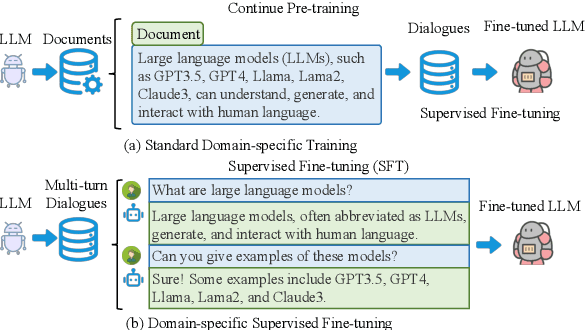



Instruction tuning as an effective technique aligns the outputs of large language models (LLMs) with human preference. But how to generate the seasonal multi-turn dialogues from raw documents for instruction tuning still requires further exploration. In this paper, we present a novel framework named R2S that leverages the CoD-Chain of Dialogue logic to guide large language models (LLMs) in generating knowledge-intensive multi-turn dialogues for instruction tuning. By integrating raw documents from both open-source datasets and domain-specific web-crawled documents into a benchmark K-BENCH, we cover diverse areas such as Wikipedia (English), Science (Chinese), and Artifacts (Chinese). Our approach first decides the logic flow of the current dialogue and then prompts LLMs to produce key phrases for sourcing relevant response content. This methodology enables the creation of the G I NSTRUCT instruction dataset, retaining raw document knowledge within dialoguestyle interactions. Utilizing this dataset, we fine-tune GLLM, a model designed to transform raw documents into structured multi-turn dialogues, thereby injecting comprehensive domain knowledge into the SFT model for enhanced instruction tuning. This work signifies a stride towards refining the adaptability and effectiveness of LLMs in processing and generating more accurate, contextually nuanced responses across various fields.
Rethinking Object Saliency Ranking: A Novel Whole-flow Processing Paradigm
Dec 06, 2023



Existing salient object detection methods are capable of predicting binary maps that highlight visually salient regions. However, these methods are limited in their ability to differentiate the relative importance of multiple objects and the relationships among them, which can lead to errors and reduced accuracy in downstream tasks that depend on the relative importance of multiple objects. To conquer, this paper proposes a new paradigm for saliency ranking, which aims to completely focus on ranking salient objects by their "importance order". While previous works have shown promising performance, they still face ill-posed problems. First, the saliency ranking ground truth (GT) orders generation methods are unreasonable since determining the correct ranking order is not well-defined, resulting in false alarms. Second, training a ranking model remains challenging because most saliency ranking methods follow the multi-task paradigm, leading to conflicts and trade-offs among different tasks. Third, existing regression-based saliency ranking methods are complex for saliency ranking models due to their reliance on instance mask-based saliency ranking orders. These methods require a significant amount of data to perform accurately and can be challenging to implement effectively. To solve these problems, this paper conducts an in-depth analysis of the causes and proposes a whole-flow processing paradigm of saliency ranking task from the perspective of "GT data generation", "network structure design" and "training protocol". The proposed approach outperforms existing state-of-the-art methods on the widely-used SALICON set, as demonstrated by extensive experiments with fair and reasonable comparisons. The saliency ranking task is still in its infancy, and our proposed unified framework can serve as a fundamental strategy to guide future work.
A Comprehensive Survey on Video Saliency Detection with Auditory Information: the Audio-visual Consistency Perceptual is the Key!
Jun 20, 2022
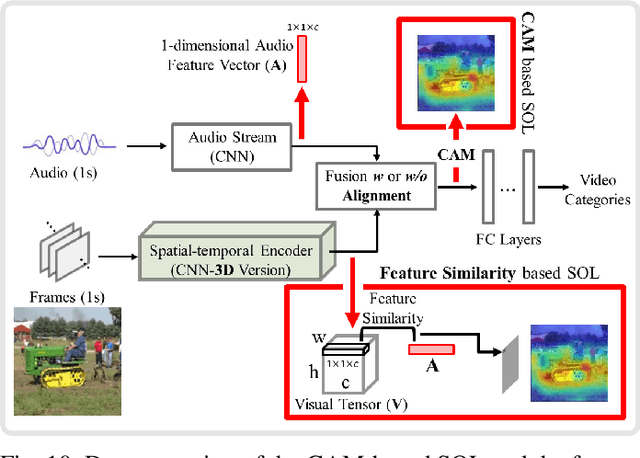
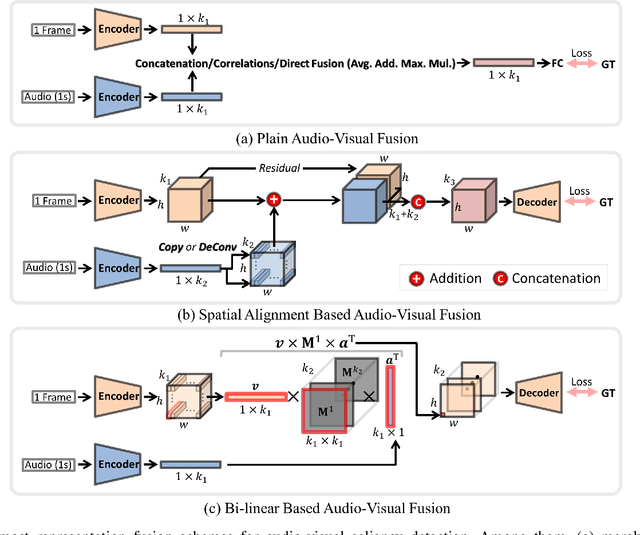
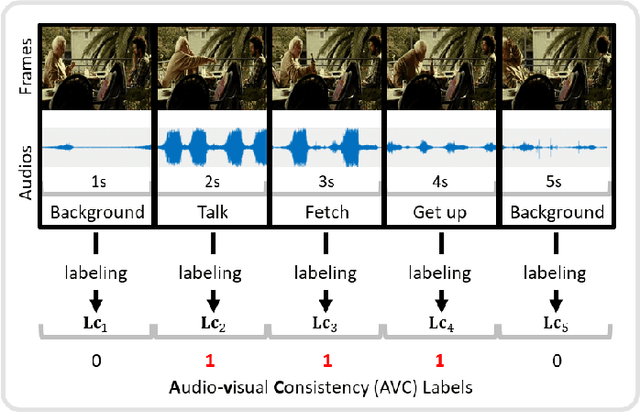
Video saliency detection (VSD) aims at fast locating the most attractive objects/things/patterns in a given video clip. Existing VSD-related works have mainly relied on the visual system but paid less attention to the audio aspect, while, actually, our audio system is the most vital complementary part to our visual system. Also, audio-visual saliency detection (AVSD), one of the most representative research topics for mimicking human perceptual mechanisms, is currently in its infancy, and none of the existing survey papers have touched on it, especially from the perspective of saliency detection. Thus, the ultimate goal of this paper is to provide an extensive review to bridge the gap between audio-visual fusion and saliency detection. In addition, as another highlight of this review, we have provided a deep insight into key factors which could directly determine the performances of AVSD deep models, and we claim that the audio-visual consistency degree (AVC) -- a long-overlooked issue, can directly influence the effectiveness of using audio to benefit its visual counterpart when performing saliency detection. Moreover, in order to make the AVC issue more practical and valuable for future followers, we have newly equipped almost all existing publicly available AVSD datasets with additional frame-wise AVC labels. Based on these upgraded datasets, we have conducted extensive quantitative evaluations to ground our claim on the importance of AVC in the AVSD task. In a word, both our ideas and new sets serve as a convenient platform with preliminaries and guidelines, all of which are very potential to facilitate future works in promoting state-of-the-art (SOTA) performance further.