 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractal Pyramid Networks
Paper and Code
Jun 28, 2021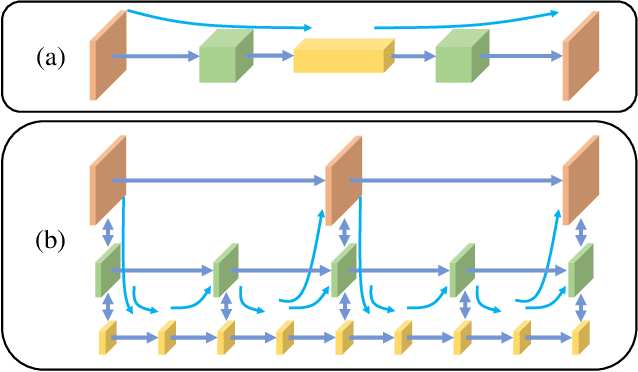
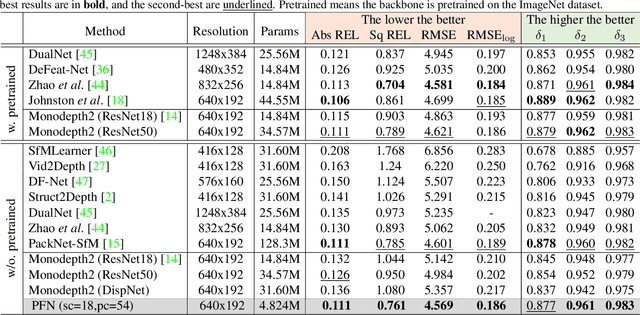
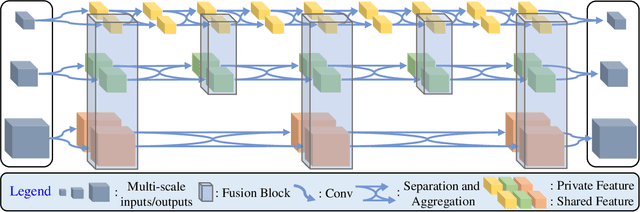
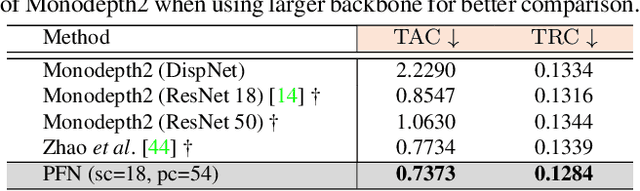
We propose a new network architecture, the Fractal Pyramid Networks (PFNs) for pixel-wise prediction tasks as an alternative to the widely used encoder-decoder structure. In the encoder-decoder structure, the input is processed by an encoding-decoding pipeline that tries to get a semantic large-channel feature. Different from that, our proposed PFNs hold multiple information processing pathways and encode the information to multiple separate small-channel features. On the task of self-supervised monocular depth estimation, even without ImageNet pretrained, our models can compete or outperform the state-of-the-art methods on the KITTI dataset with much fewer parameters. Moreover, the visual quality of the prediction is significantly improved. The experiment of semantic segmentation provides evidence that the PFNs can be applied to other pixel-wise prediction tasks, and demonstrates that our models can catch more global structure information.