 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoG3D: Ultra-High-Resolution 3D Shape Modeling via Local-to-Global Partitioning
Nov 18, 2025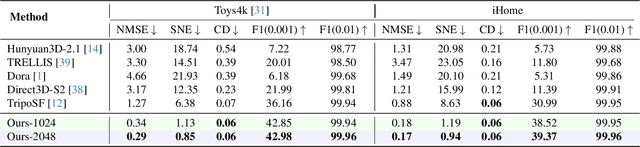
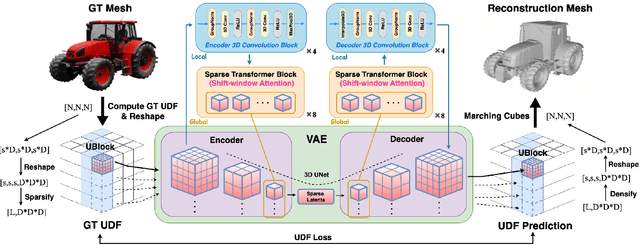
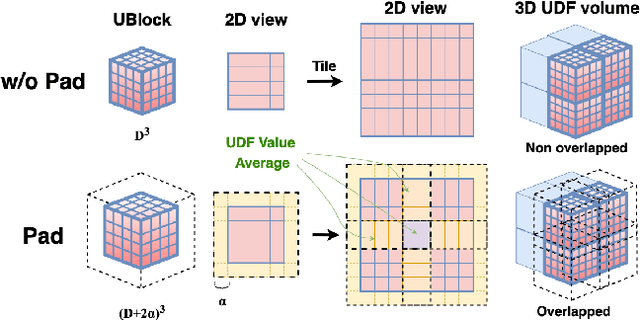
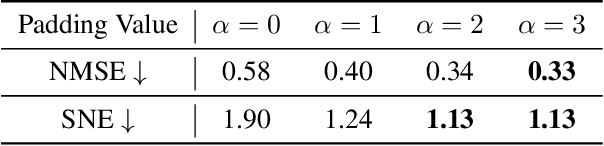
Generating high-fidelity 3D contents remains a fundamental challenge due to the complexity of representing arbitrary topologies-such as open surfaces and intricate internal structures-while preserving geometric details. Prevailing methods based on signed distance fields (SDFs) are hampered by costly watertight preprocessing and struggle with non-manifold geometries, while point-cloud representations often suffer from sampling artifacts and surface discontinuities. To overcome these limitations, we propose a novel 3D variational autoencoder (VAE) framework built upon unsigned distance fields (UDFs)-a more robust and computationally efficient representation that naturally handles complex and incomplete shapes. Our core innovation is a local-to-global (LoG) architecture that processes the UDF by partitioning it into uniform subvolumes, termed UBlocks. This architecture couples 3D convolutions for capturing local detail with sparse transformers for enforcing global coherence. A Pad-Average strategy further ensures smooth transitions at subvolume boundaries during reconstruction. This modular design enables seamless scaling to ultra-high resolutions up to $2048^3$-a regime previously unattainable for 3D VAEs. Experiments demonstrate state-of-the-art performance in both reconstruction accuracy and generative quality, yielding superior surface smoothness and geometric flexibility.
GlossyGS: Inverse Rendering of Glossy Objects with 3D Gaussian Splatting
Oct 17, 2024

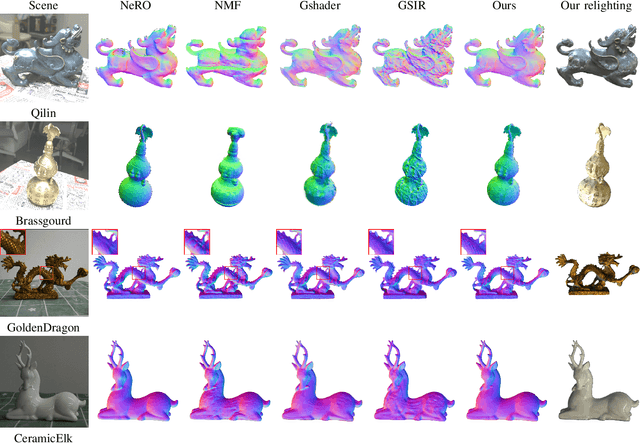
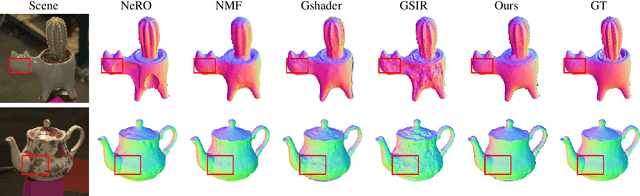
Reconstructing objects from posed images is a crucial and complex task in computer graphics and computer vision. While NeRF-based neural reconstruction methods have exhibited impressive reconstruction ability, they tend to be time-comsuming. Recent strategies have adopted 3D Gaussian Splatting (3D-GS) for inverse rendering, which have led to quick and effective outcomes. However, these techniques generally have difficulty in producing believable geometries and materials for glossy objects, a challenge that stems from the inherent ambiguities of inverse rendering. To address this, we introduce GlossyGS, an innovative 3D-GS-based inverse rendering framework that aims to precisely reconstruct the geometry and materials of glossy objects by integrating material priors. The key idea is the use of micro-facet geometry segmentation prior, which helps to reduce the intrinsic ambiguities and improve the decomposition of geometries and materials. Additionally, we introduce a normal map prefiltering strategy to more accurately simulate the normal distribution of reflective surfaces. These strategies are integrated into a hybrid geometry and material representation that employs both explicit and implicit methods to depict glossy objects. We demonstrate through quantitative analysis and qualitative visualization that the proposed method is effective to reconstruct high-fidelity geometries and materials of glossy objects, and performs favorably against state-of-the-arts.
GLPanoDepth: Global-to-Local Panoramic Depth Estimation
Feb 08, 2022



In this paper, we propose a learning-based method for predicting dense depth values of a scene from a monocular omnidirectional image. An omnidirectional image has a full field-of-view, providing much more complete descriptions of the scene than perspective images. However, fully-convolutional networks that most current solutions rely on fail to capture rich global contexts from the panorama. To address this issue and also the distortion of equirectangular projection in the panorama, we propose Cubemap Vision Transformers (CViT), a new transformer-based architecture that can model long-range dependencies and extract distortion-free global features from the panorama. We show that cubemap vision transformers have a global receptive field at every stage and can provide globally coherent predictions for spherical signals. To preserve important local features, we further design a convolution-based branch in our pipeline (dubbed GLPanoDepth) and fuse global features from cubemap vision transformers at multiple scales. This global-to-local strategy allows us to fully exploit useful global and local features in the panorama, achieving state-of-the-art performance in panoramic depth estimation.