 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetMamba: Regional Weather Forecasting with Spatial-Temporal Mamba Model
Aug 14, 2024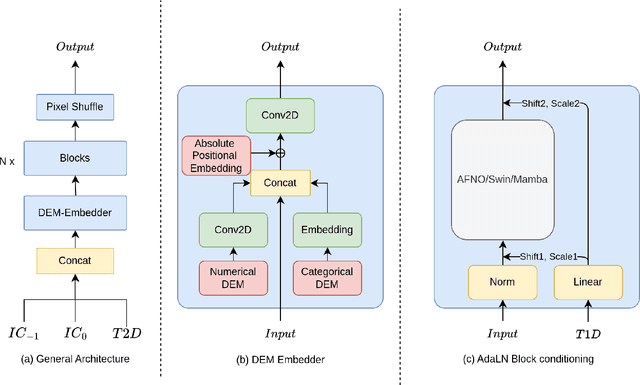
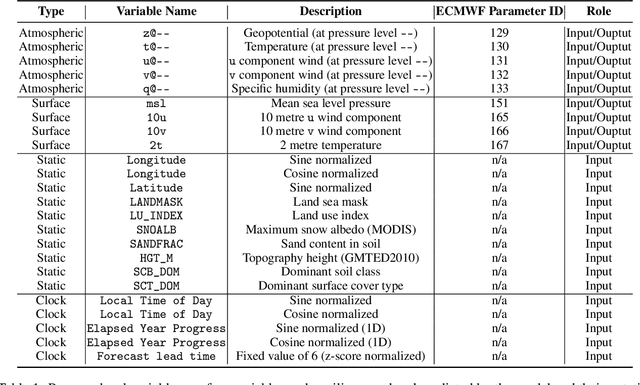
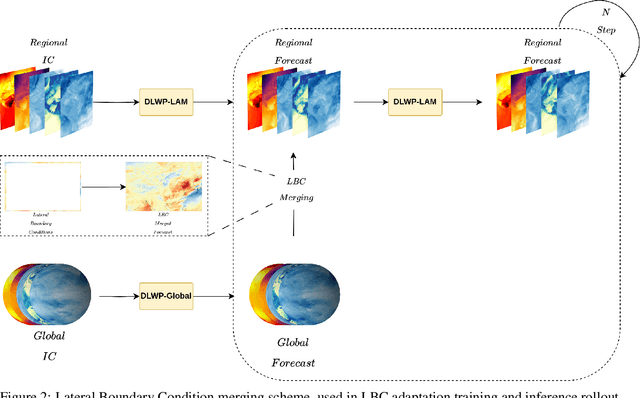
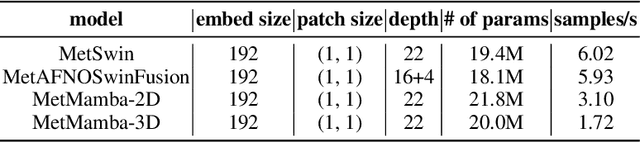
Deep Learning based Weather Prediction (DLWP) models have been improving rapidly over the last few years, surpassing state of the art numerical weather forecasts by significant margins. While much of the optimization effort is focused on training curriculum to extend forecast range in the global context, two aspects remains less explored: limited area modeling and better backbones for weather forecasting. We show in this paper that MetMamba, a DLWP model built on a state-of-the-art state-space model, Mamba, offers notable performance gains and unique advantages over other popular backbones using traditional attention mechanisms and neural operators. We also demonstrate the feasibility of deep learning based limited area modeling via coupled training with a global host model.
CoupleFace: Relation Matters for Face Recognition Distillation
Apr 12, 2022Knowledge distillation is an effective method to improve the performance of a lightweight neural network (i.e., student model) by transferring the knowledge of a well-performed neural network (i.e., teacher model), which has been widely applied in many computer vision tasks, including face recognition. Nevertheless, the current face recognition distillation methods usually utilize the Feature Consistency Distillation (FCD) (e.g., L2 distance) on the learned embeddings extracted by the teacher and student models for each sample, which is not able to fully transfer the knowledge from the teacher to the student for face recognition. In this work, we observe that mutual relation knowledge between samples is also important to improve the discriminative ability of the learned representation of the student model, and propose an effective face recognition distillation method called CoupleFace by additionally introducing the Mutual Relation Distillation (MRD) into existing distillation framework. Specifically, in MRD, we first propose to mine the informative mutual relations, and then introduce the Relation-Aware Distillation (RAD) loss to transfer the mutual relation knowledge of the teacher model to the student model. Extensive experimental results on multiple benchmark datasets demonstrate the effectiveness of our proposed CoupleFace for face recognition. Moreover, based on our proposed CoupleFace, we have won the first place in the ICCV21 Masked Face Recognition Challenge (MS1M track).
GLPanoDepth: Global-to-Local Panoramic Depth Estimation
Feb 08, 2022



In this paper, we propose a learning-based method for predicting dense depth values of a scene from a monocular omnidirectional image. An omnidirectional image has a full field-of-view, providing much more complete descriptions of the scene than perspective images. However, fully-convolutional networks that most current solutions rely on fail to capture rich global contexts from the panorama. To address this issue and also the distortion of equirectangular projection in the panorama, we propose Cubemap Vision Transformers (CViT), a new transformer-based architecture that can model long-range dependencies and extract distortion-free global features from the panorama. We show that cubemap vision transformers have a global receptive field at every stage and can provide globally coherent predictions for spherical signals. To preserve important local features, we further design a convolution-based branch in our pipeline (dubbed GLPanoDepth) and fuse global features from cubemap vision transformers at multiple scales. This global-to-local strategy allows us to fully exploit useful global and local features in the panorama, achieving state-of-the-art performance in panoramic depth estimation.
Analogical Reasoning for Visually Grounded Language Acquisition
Jul 22, 2020
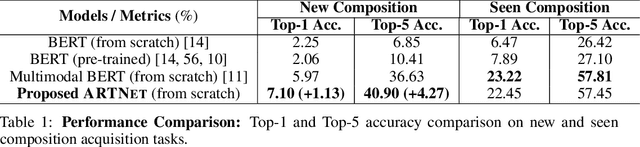
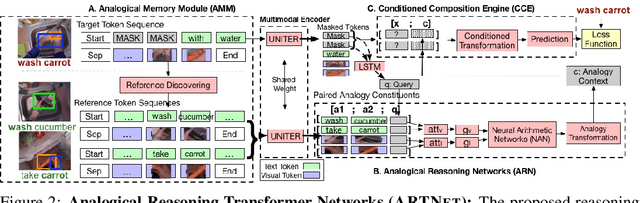

Children acquire language subconsciously by observing the surrounding world and listening to descriptions. They can discover the meaning of words even without explicit language knowledge, and generalize to novel compositions effortlessly. In this paper, we bring this ability to AI, by studying the task of Visually grounded Language Acquisition (VLA). We propose a multimodal transformer model augmented with a novel mechanism for analogical reasoning, which approximates novel compositions by learning semantic mapping and reasoning operations from previously seen compositions. Our proposed method, Analogical Reasoning Transformer Networks (ARTNet), is trained on raw multimedia data (video frames and transcripts), and after observing a set of compositions such as "washing apple" or "cutting carrot", it can generalize and recognize new compositions in new video frames, such as "washing carrot" or "cutting apple". To this end, ARTNet refers to relevant instances in the training data and uses their visual features and captions to establish analogies with the query image. Then it chooses the suitable verb and noun to create a new composition that describes the new image best. Extensive experiments on an instructional video dataset demonstrate that the proposed method achieves significantly better generalization capability and recognition accuracy compared to state-of-the-art transformer models.
Asymmetric Rejection Loss for Fairer Face Recognition
Feb 09, 2020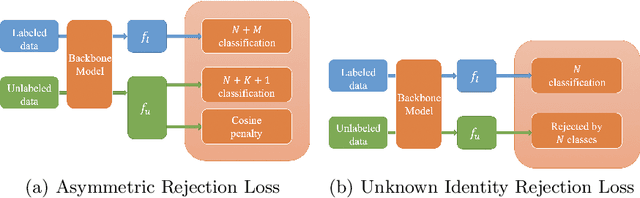
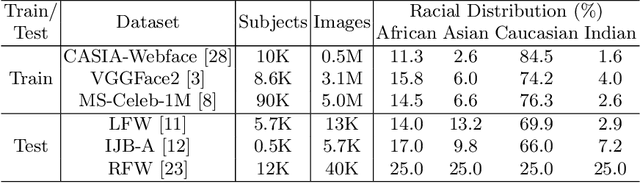
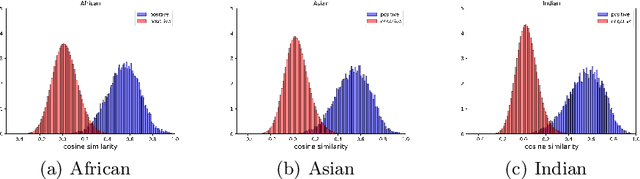
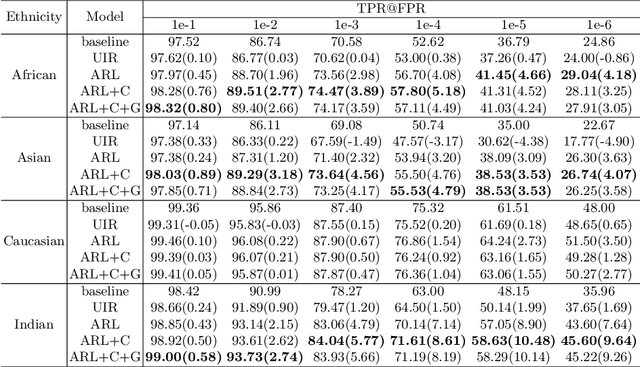
Face recognition performance has seen a tremendous gain in recent years, mostly due to the availability of large-scale face images dataset that can be exploited by deep neural networks to learn powerful face representations. However, recent research has shown differences in face recognition performance across different ethnic groups mostly due to the racial imbalance in the training datasets where Caucasian identities largely dominate other ethnicities. This is actually symptomatic of the under-representation of non-Caucasian ethnic groups in the celebdom from which face datasets are usually gathered, rendering the acquisition of labeled data of the under-represented groups challenging. In this paper, we propose an Asymmetric Rejection Loss, which aims at making full use of unlabeled images of those under-represented groups, to reduce the racial bias of face recognition models. We view each unlabeled image as a unique class, however as we cannot guarantee that two unlabeled samples are from a distinct class we exploit both labeled and unlabeled data in an asymmetric manner in our loss formalism. Extensive experiments show our method's strength in mitigating racial bias, outperforming state-of-the-art semi-supervision methods. Performance on the under-represented ethnicity groups increases while that on the well-represented group is nearly unchanged.