 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogical Reasoning for Visually Grounded Language Acquisition
Paper and Code
Jul 22, 2020
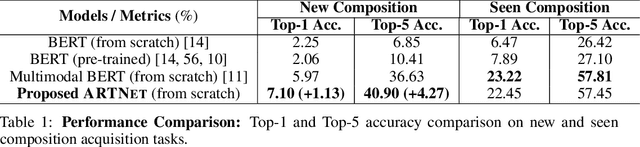
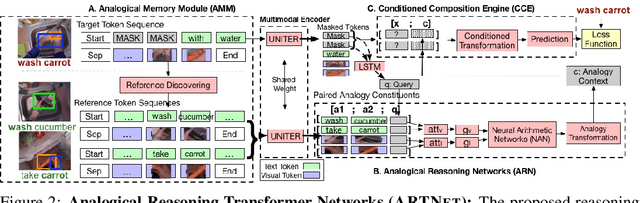

Children acquire language subconsciously by observing the surrounding world and listening to descriptions. They can discover the meaning of words even without explicit language knowledge, and generalize to novel compositions effortlessly. In this paper, we bring this ability to AI, by studying the task of Visually grounded Language Acquisition (VLA). We propose a multimodal transformer model augmented with a novel mechanism for analogical reasoning, which approximates novel compositions by learning semantic mapping and reasoning operations from previously seen compositions. Our proposed method, Analogical Reasoning Transformer Networks (ARTNet), is trained on raw multimedia data (video frames and transcripts), and after observing a set of compositions such as "washing apple" or "cutting carrot", it can generalize and recognize new compositions in new video frames, such as "washing carrot" or "cutting apple". To this end, ARTNet refers to relevant instances in the training data and uses their visual features and captions to establish analogies with the query image. Then it chooses the suitable verb and noun to create a new composition that describes the new image best. Extensive experiments on an instructional video dataset demonstrate that the proposed method achieves significantly better generalization capability and recognition accuracy compared to state-of-the-art transformer models.