 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequentially Controlled Text Generation
Jan 05, 2023



While GPT-2 generates sentences that are remarkably human-like, longer documents can ramble and do not follow human-like writing structure. We study the problem of imposing structure on long-range text. We propose a novel controlled text generation task, sequentially controlled text generation, and identify a dataset, NewsDiscourse as a starting point for this task. We develop a sequential controlled text generation pipeline with generation and editing. We test different degrees of structural awareness and show that, in general, more structural awareness results in higher control-accuracy, grammaticality, coherency and topicality, approaching human-level writing performance.
* 19 pages. 10 pages main body, 3 pages references, 6 pages appendix
Efficient Argument Structure Extraction with Transfer Learning and Active Learning
Apr 01, 2022
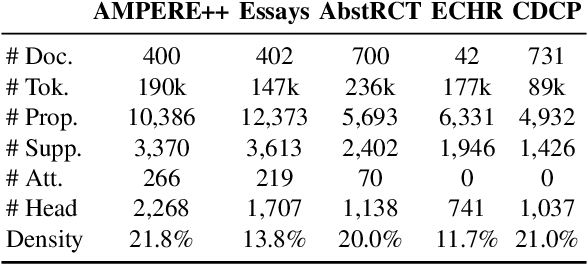
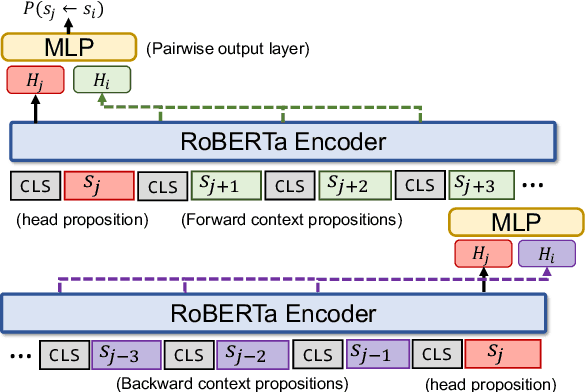
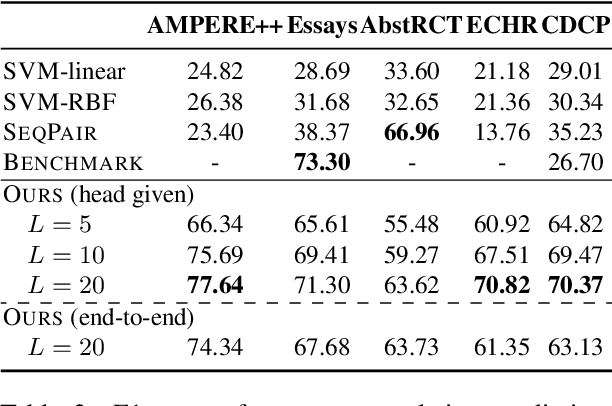
The automation of extracting argument structures faces a pair of challenges on (1) encoding long-term contexts to facilitate comprehensive understanding, and (2) improving data efficiency since constructing high-quality argument structures is time-consuming. In this work, we propose a novel context-aware Transformer-based argument structure prediction model which, on five different domains, significantly outperforms models that rely on features or only encode limited contexts. To tackle the difficulty of data annotation, we examine two complementary methods: (i) transfer learning to leverage existing annotated data to boost model performance in a new target domain, and (ii) active learning to strategically identify a small amount of samples for annotation. We further propose model-independent sample acquisition strategies, which can be generalized to diverse domains. With extensive experiments, we show that our simple-yet-effective acquisition strategies yield competitive results against three strong comparisons. Combined with transfer learning, substantial F1 score boost (5-25) can be further achieved during the early iterations of active learning across domains.
DYPLOC: Dynamic Planning of Content Using Mixed Language Models for Text Generation
Jun 01, 2021


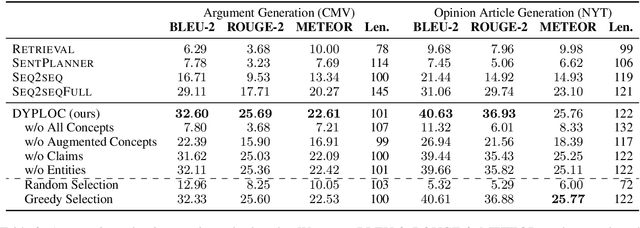
We study the task of long-form opinion text generation, which faces at least two distinct challenges. First, existing neural generation models fall short of coherence, thus requiring efficient content planning. Second, diverse types of information are needed to guide the generator to cover both subjective and objective content. To this end, we propose DYPLOC, a generation framework that conducts dynamic planning of content while generating the output based on a novel design of mixed language models. To enrich the generation with diverse content, we further propose to use large pre-trained models to predict relevant concepts and to generate claims. We experiment with two challenging tasks on newly collected datasets: (1) argument generation with Reddit ChangeMyView, and (2) writing articles using New York Times' Opinion section. Automatic evaluation shows that our model significantly outperforms competitive comparisons. Human judges further confirm that our generations are more coherent with richer content.
PAIR: Planning and Iterative Refinement in Pre-trained Transformers for Long Text Generation
Oct 05, 2020



Pre-trained Transformers have enabled impressive breakthroughs in generating long and fluent text, yet their outputs are often "rambling" without coherently arranged content. In this work, we present a novel content-controlled text generation framework, PAIR, with planning and iterative refinement, which is built upon a large model, BART. We first adapt the BERT model to automatically construct the content plans, consisting of keyphrase assignments and their corresponding sentence-level positions. The BART model is employed for generation without modifying its structure. We then propose a refinement algorithm to gradually enhance the generation quality within the sequence-to-sequence framework. Evaluation with automatic metrics shows that adding planning consistently improves the generation quality on three distinct domains, with an average of 20 BLEU points and 12 METEOR points improvements. In addition, human judges rate our system outputs to be more relevant and coherent than comparisons without planning.
XREF: Entity Linking for Chinese News Comments with Supplementary Article Reference
Jun 24, 2020
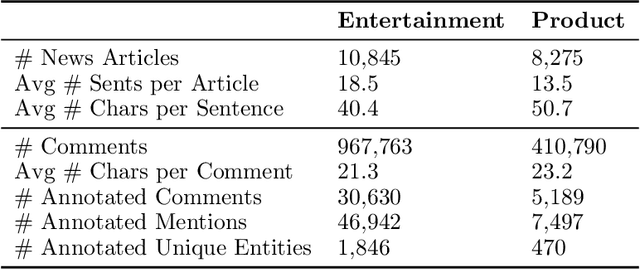
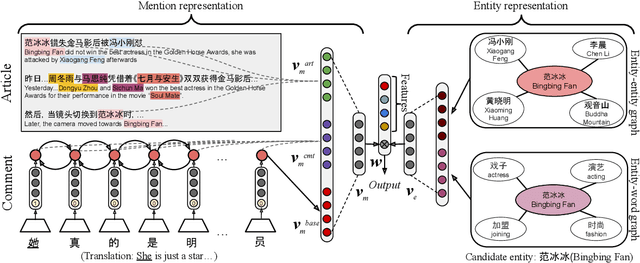

Automatic identification of mentioned entities in social media posts facilitates quick digestion of trending topics and popular opinions. Nonetheless, this remains a challenging task due to limited context and diverse name variations. In this paper, we study the problem of entity linking for Chinese news comments given mentions' spans. We hypothesize that comments often refer to entities in the corresponding news article, as well as topics involving the entities. We therefore propose a novel model, XREF, that leverages attention mechanisms to (1) pinpoint relevant context within comments, and (2) detect supporting entities from the news article. To improve training, we make two contributions: (a) we propose a supervised attention loss in addition to the standard cross entropy, and (b) we develop a weakly supervised training scheme to utilize the large-scale unlabeled corpus. Two new datasets in entertainment and product domains are collected and annotated for experiments. Our proposed method outperforms previous methods on both datasets.
Sentence-Level Content Planning and Style Specification for Neural Text Generation
Sep 02, 2019



Building effective text generation systems requires three critical components: content selection, text planning, and surface realization, and traditionally they are tackled as separate problems. Recent all-in-one style neural generation models have made impressive progress, yet they often produce outputs that are incoherent and unfaithful to the input. To address these issues, we present an end-to-end trained two-step generation model, where a sentence-level content planner first decides on the keyphrases to cover as well as a desired language style, followed by a surface realization decoder that generates relevant and coherent text. For experiments, we consider three tasks from domains with diverse topics and varying language styles: persuasive argument construction from Reddit, paragraph generation for normal and simple versions of Wikipedia, and abstract generation for scientific articles. Automatic evaluation shows that our system can significantly outperform competitive comparisons. Human judges further rate our system generated text as more fluent and correct, compared to the generations by its variants that do not consider language style.
Argument Generation with Retrieval, Planning, and Realization
Jun 09, 2019



Automatic argument generation is an appealing but challenging task. In this paper, we study the specific problem of counter-argument generation, and present a novel framework, CANDELA. It consists of a powerful retrieval system and a novel two-step generation model, where a text planning decoder first decides on the main talking points and a proper language style for each sentence, then a content realization decoder reflects the decisions and constructs an informative paragraph-level argument. Furthermore, our generation model is empowered by a retrieval system indexed with 12 million articles collected from Wikipedia and popular English news media, which provides access to high-quality content with diversity. Automatic evaluation on a large-scale dataset collected from Reddit shows that our model yields significantly higher BLEU, ROUGE, and METEOR scores than the state-of-the-art and non-trivial comparisons. Human evaluation further indicates that our system arguments are more appropriate for refutation and richer in content.
Argument Mining for Understanding Peer Reviews
Mar 25, 2019

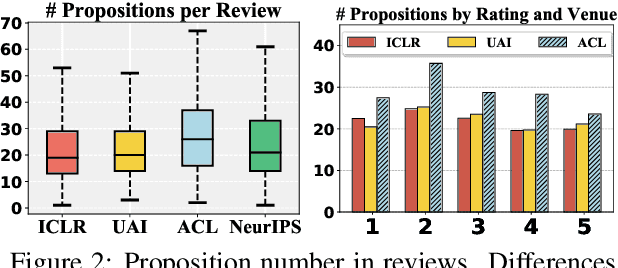

Peer-review plays a critical role in the scientific writing and publication ecosystem. To assess the efficiency and efficacy of the reviewing process, one essential element is to understand and evaluate the reviews themselves. In this work, we study the content and structure of peer reviews under the argument mining framework, through automatically detecting (1) argumentative propositions put forward by reviewers, and (2) their types (e.g., evaluating the work or making suggestions for improvement). We first collect 14.2K reviews from major machine learning and natural language processing venues. 400 reviews are annotated with 10,386 propositions and corresponding types of Evaluation, Request, Fact, Reference, or Quote. We then train state-of-the-art proposition segmentation and classification models on the data to evaluate their utilities and identify new challenges for this new domain, motivating future directions for argument mining. Further experiments show that proposition usage varies across venues in amount, type, and topic.
Neural Argument Generation Augmented with Externally Retrieved Evidence
May 25, 2018


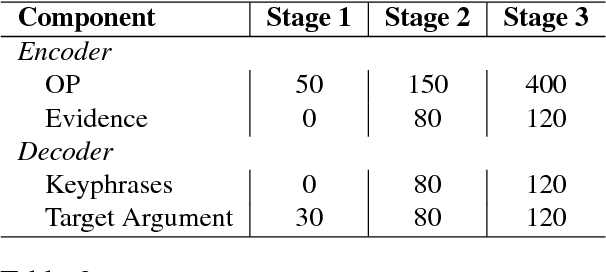
High quality arguments are essential elements for human reasoning and decision-making processes. However, effective argument construction is a challenging task for both human and machines. In this work, we study a novel task on automatically generating arguments of a different stance for a given statement. We propose an encoder-decoder style neural network-based argument generation model enriched with externally retrieved evidence from Wikipedia. Our model first generates a set of talking point phrases as intermediate representation, followed by a separate decoder producing the final argument based on both input and the keyphrases. Experiments on a large-scale dataset collected from Reddit show that our model constructs arguments with more topic-relevant content than a popular sequence-to-sequence generation model according to both automatic evaluation and human assessments.
A Pilot Study of Domain Adaptation Effect for Neural Abstractive Summarization
Jul 21, 2017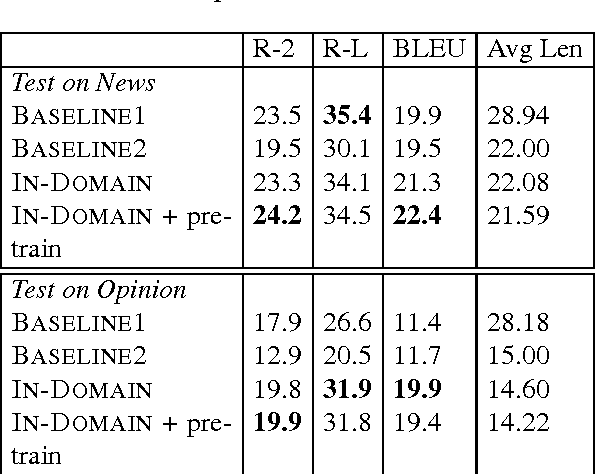


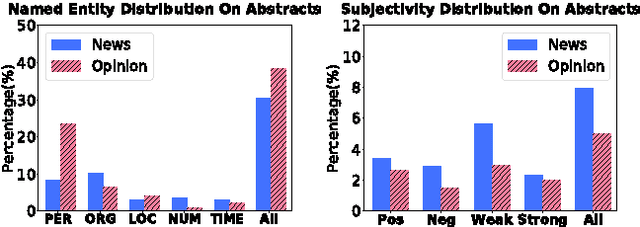
We study the problem of domain adaptation for neural abstractive summarization. We make initial efforts in investigating what information can be transferred to a new domain. Experimental results on news stories and opinion articles indicate that neural summarization model benefits from pre-training based on extractive summaries. We also find that the combination of in-domain and out-of-domain setup yields better summaries when in-domain data is insufficient. Further analysis shows that, the model is capable to select salient content even trained on out-of-domain data, but requires in-domain data to capture the style for a target domain.