 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Attacks Reveal Superficial Knowledge Removal in Unlearning Methods
Jun 11, 2025In this work, we show that some machine unlearning methods may fail when subjected to straightforward prompt attacks. We systematically evaluate eight unlearning techniques across three model families, and employ output-based, logit-based, and probe analysis to determine to what extent supposedly unlearned knowledge can be retrieved. While methods like RMU and TAR demonstrate robust unlearning, ELM remains vulnerable to specific prompt attacks (e.g., Hindi filler text in original prompt recovering 57.3% accuracy). Our logit analysis also confirms that unlearned models are generally not hiding knowledge by modifying the way the answer is formatted, as the correlation between output and logit accuracy is strong. These results challenge prevailing assumptions about unlearning effectiveness and highlight the need for evaluation frameworks that can reliably distinguish between true knowledge removal and superficial output suppression. We also publicly make available our evaluation framework to easily evaluate prompting techniques to retrieve unlearning knowledge.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
DYPLOC: Dynamic Planning of Content Using Mixed Language Models for Text Generation
Jun 01, 2021


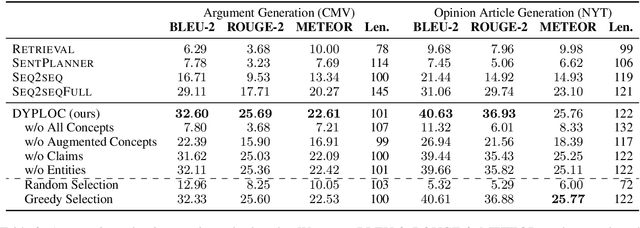
We study the task of long-form opinion text generation, which faces at least two distinct challenges. First, existing neural generation models fall short of coherence, thus requiring efficient content planning. Second, diverse types of information are needed to guide the generator to cover both subjective and objective content. To this end, we propose DYPLOC, a generation framework that conducts dynamic planning of content while generating the output based on a novel design of mixed language models. To enrich the generation with diverse content, we further propose to use large pre-trained models to predict relevant concepts and to generate claims. We experiment with two challenging tasks on newly collected datasets: (1) argument generation with Reddit ChangeMyView, and (2) writing articles using New York Times' Opinion section. Automatic evaluation shows that our model significantly outperforms competitive comparisons. Human judges further confirm that our generations are more coherent with richer content.