 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a statistical theory of data selection under weak supervision
Sep 25, 2023
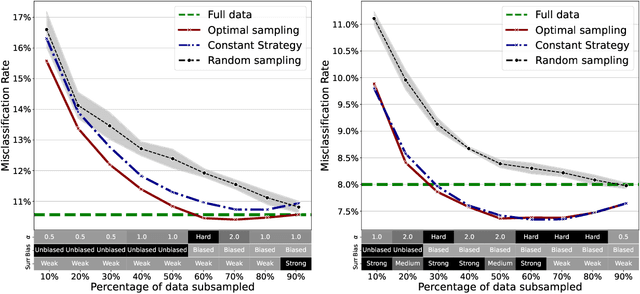
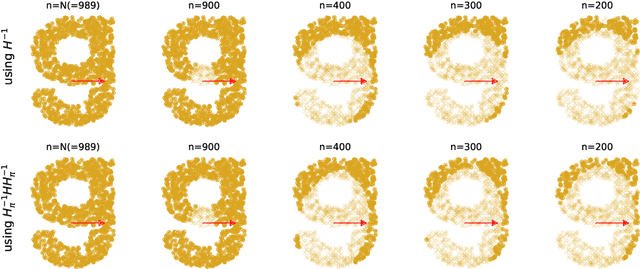

Given a sample of size $N$, it is often useful to select a subsample of smaller size $n<N$ to be used for statistical estimation or learning. Such a data selection step is useful to reduce the requirements of data labeling and the computational complexity of learning. We assume to be given $N$ unlabeled samples $\{{\boldsymbol x}_i\}_{i\le N}$, and to be given access to a `surrogate model' that can predict labels $y_i$ better than random guessing. Our goal is to select a subset of the samples, to be denoted by $\{{\boldsymbol x}_i\}_{i\in G}$, of size $|G|=n<N$. We then acquire labels for this set and we use them to train a model via regularized empirical risk minimization. By using a mixture of numerical experiments on real and synthetic data, and mathematical derivations under low- and high- dimensional asymptotics, we show that: $(i)$~Data selection can be very effective, in particular beating training on the full sample in some cases; $(ii)$~Certain popular choices in data selection methods (e.g. unbiased reweighted subsampling, or influence function-based subsampling) can be substantially suboptimal.