 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal contrastive learning adapts to intrinsic dimensions of shared latent variables
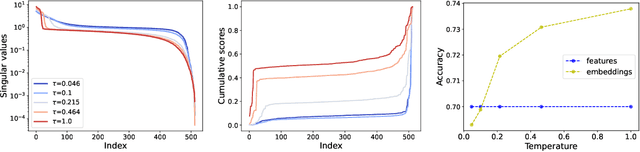
May 18, 2025Multi-modal contrastive learning as a self-supervised representation learning technique has achieved great success in foundation model training, such as CLIP~\citep{radford2021learning}. In this paper, we study the theoretical properties of the learned representations from multi-modal contrastive learning beyond linear representations and specific data distributions. Our analysis reveals that, enabled by temperature optimization, multi-modal contrastive learning not only maximizes mutual information between modalities but also adapts to intrinsic dimensions of data, which can be much lower than user-specified dimensions for representation vectors. Experiments on both synthetic and real-world datasets demonstrate the ability of contrastive learning to learn low-dimensional and informative representations, bridging theoretical insights and practical performance.
Conformal Prediction: A Data Perspective
Oct 09, 2024
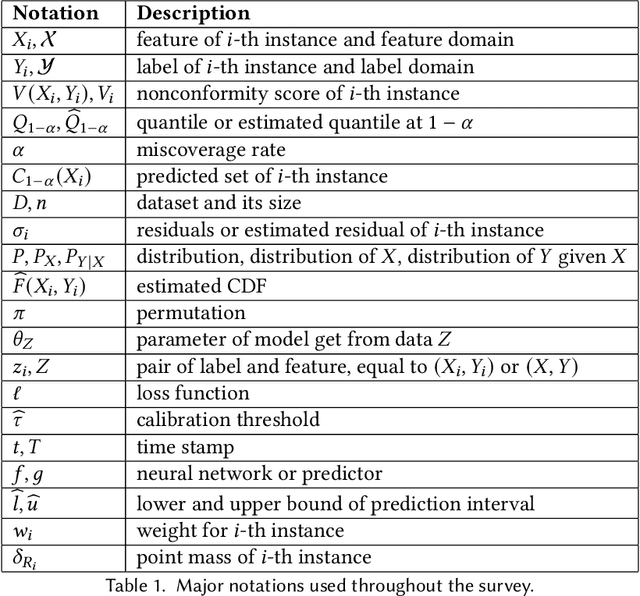
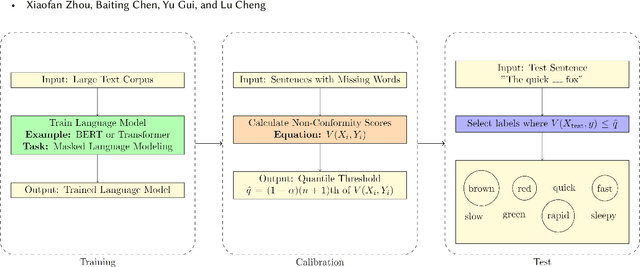

Conformal prediction (CP), a distribution-free uncertainty quantification (UQ) framework, reliably provides valid predictive inference for black-box models. CP constructs prediction sets that contain the true output with a specified probability. However, modern data science diverse modalities, along with increasing data and model complexity, challenge traditional CP methods. These developments have spurred novel approaches to address evolving scenarios. This survey reviews the foundational concepts of CP and recent advancements from a data-centric perspective, including applications to structured, unstructured, and dynamic data. We also discuss the challenges and opportunities CP faces in large-scale data and models.
Conformal Alignment: Knowing When to Trust Foundation Models with Guarantees
May 16, 2024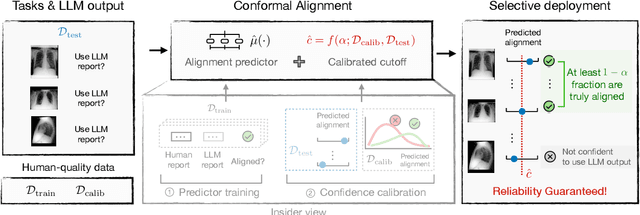
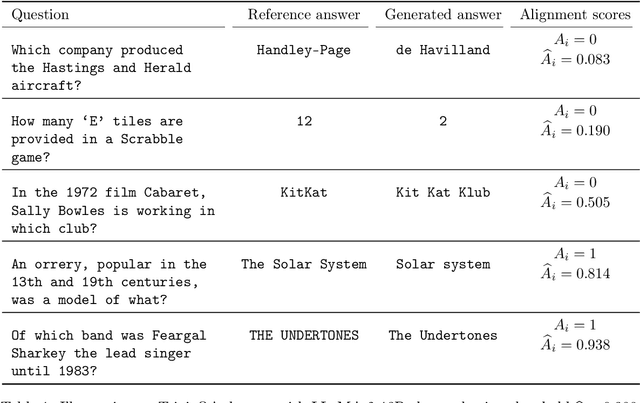
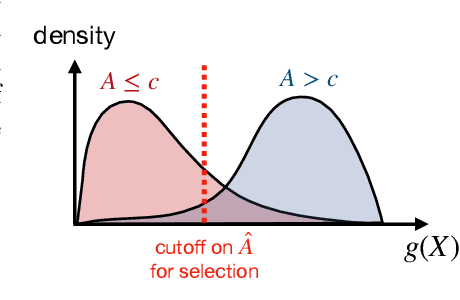
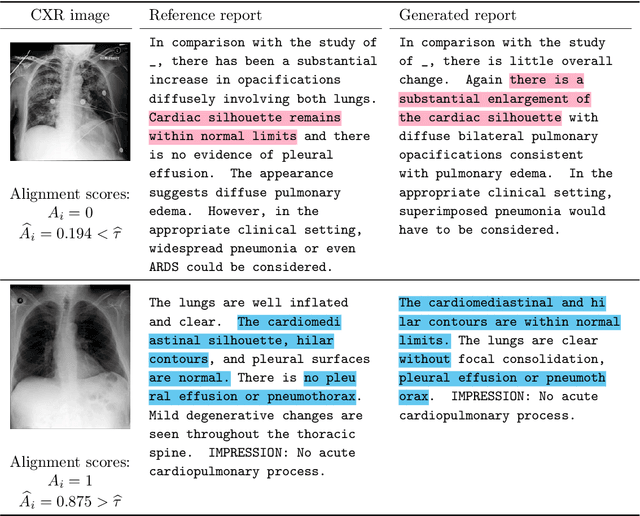
Before deploying outputs from foundation models in high-stakes tasks, it is imperative to ensure that they align with human values. For instance, in radiology report generation, reports generated by a vision-language model must align with human evaluations before their use in medical decision-making. This paper presents Conformal Alignment, a general framework for identifying units whose outputs meet a user-specified alignment criterion. It is guaranteed that on average, a prescribed fraction of selected units indeed meet the alignment criterion, regardless of the foundation model or the data distribution. Given any pre-trained model and new units with model-generated outputs, Conformal Alignment leverages a set of reference data with ground-truth alignment status to train an alignment predictor. It then selects new units whose predicted alignment scores surpass a data-dependent threshold, certifying their corresponding outputs as trustworthy. Through applications to question answering and radiology report generation, we demonstrate that our method is able to accurately identify units with trustworthy outputs via lightweight training over a moderate amount of reference data. En route, we investigate the informativeness of various features in alignment prediction and combine them with standard models to construct the alignment predictor.
Unraveling Projection Heads in Contrastive Learning: Insights from Expansion and Shrinkage
Jun 06, 2023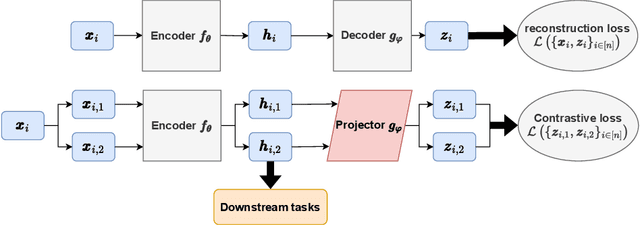

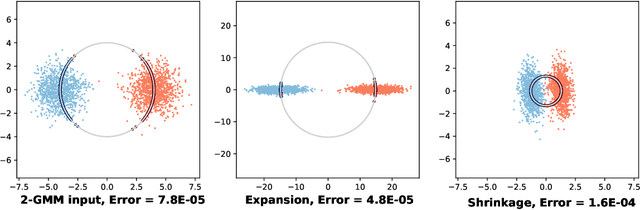
We investigate the role of projection heads, also known as projectors, within the encoder-projector framework (e.g., SimCLR) used in contrastive learning. We aim to demystify the observed phenomenon where representations learned before projectors outperform those learned after -- measured using the downstream linear classification accuracy, even when the projectors themselves are linear. In this paper, we make two significant contributions towards this aim. Firstly, through empirical and theoretical analysis, we identify two crucial effects -- expansion and shrinkage -- induced by the contrastive loss on the projectors. In essence, contrastive loss either expands or shrinks the signal direction in the representations learned by an encoder, depending on factors such as the augmentation strength, the temperature used in contrastive loss, etc. Secondly, drawing inspiration from the expansion and shrinkage phenomenon, we propose a family of linear transformations to accurately model the projector's behavior. This enables us to precisely characterize the downstream linear classification accuracy in the high-dimensional asymptotic limit. Our findings reveal that linear projectors operating in the shrinkage (or expansion) regime hinder (or improve) the downstream classification accuracy. This provides the first theoretical explanation as to why (linear) projectors impact the downstream performance of learned representations. Our theoretical findings are further corroborated by extensive experiments on both synthetic data and real image data.
Neural Gaussian Mirror for Controlled Feature Selection in Neural Networks
Oct 13, 2020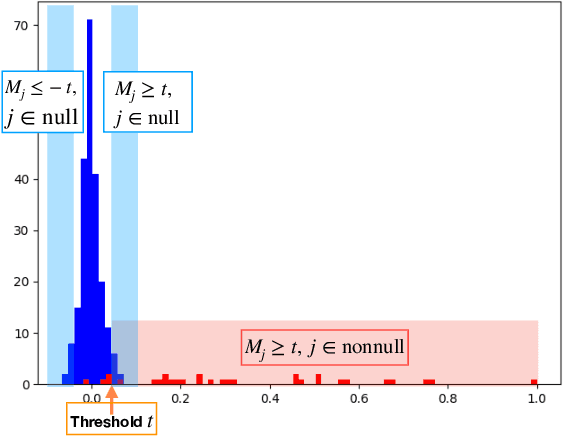
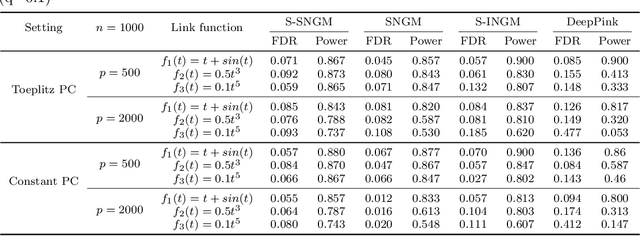
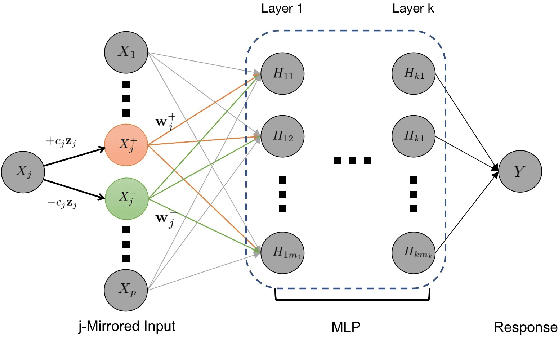
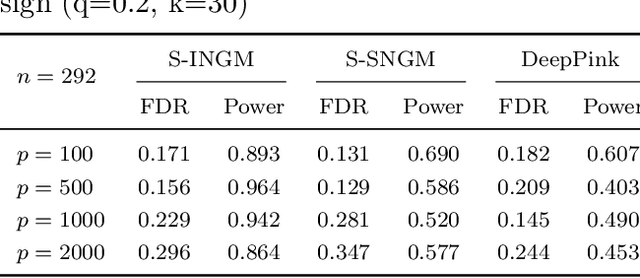
Deep neural networks (DNNs) have become increasingly popular and achieved outstanding performance in predictive tasks. However, the DNN framework itself cannot inform the user which features are more or less relevant for making the prediction, which limits its applicability in many scientific fields. We introduce neural Gaussian mirrors (NGMs), in which mirrored features are created, via a structured perturbation based on a kernel-based conditional dependence measure, to help evaluate feature importance. We design two modifications of the DNN architecture for incorporating mirrored features and providing mirror statistics to measure feature importance. As shown in simulated and real data examples, the proposed method controls the feature selection error rate at a predefined level and maintains a high selection power even with the presence of highly correlated features.