 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroup Shift Pointwise Convolution for Volumetric Medical Image Segmentation
Sep 26, 2021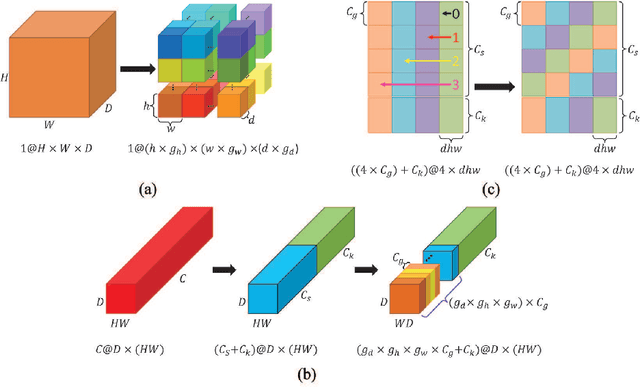
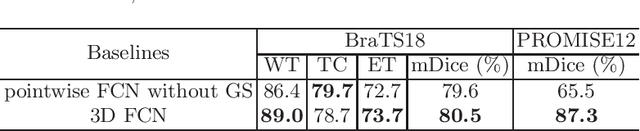

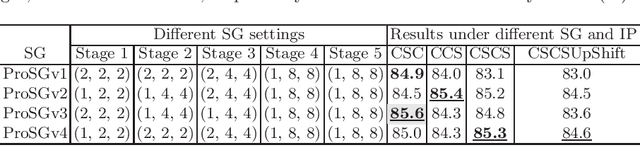
Recent studies have witnessed the effectiveness of 3D convolutions on segmenting volumetric medical images. Compared with the 2D counterparts, 3D convolutions can capture the spatial context in three dimensions. Nevertheless, models employing 3D convolutions introduce more trainable parameters and are more computationally complex, which may lead easily to model overfitting especially for medical applications with limited available training data. This paper aims to improve the effectiveness and efficiency of 3D convolutions by introducing a novel Group Shift Pointwise Convolution (GSP-Conv). GSP-Conv simplifies 3D convolutions into pointwise ones with 1x1x1 kernels, which dramatically reduces the number of model parameters and FLOPs (e.g. 27x fewer than 3D convolutions with 3x3x3 kernels). Na\"ive pointwise convolutions with limited receptive fields cannot make full use of the spatial image context. To address this problem, we propose a parameter-free operation, Group Shift (GS), which shifts the feature maps along with different spatial directions in an elegant way. With GS, pointwise convolutions can access features from different spatial locations, and the limited receptive fields of pointwise convolutions can be compensated. We evaluate the proposed methods on two datasets, PROMISE12 and BraTS18. Results show that our method, with substantially decreased model complexity, achieves comparable or even better performance than models employing 3D convolutions.
Tensor Low-Rank Reconstruction for Semantic Segmentation
Aug 02, 2020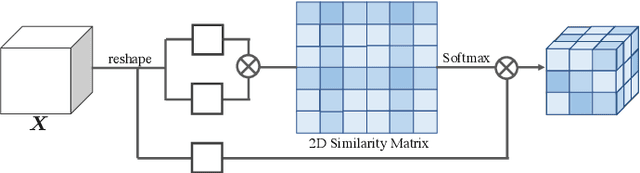
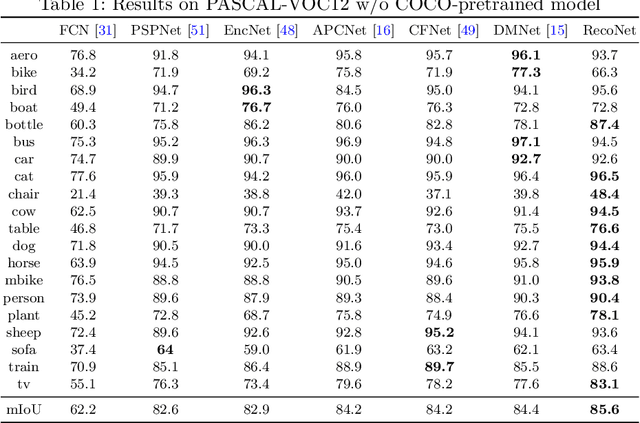
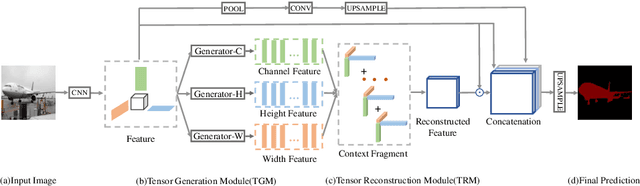
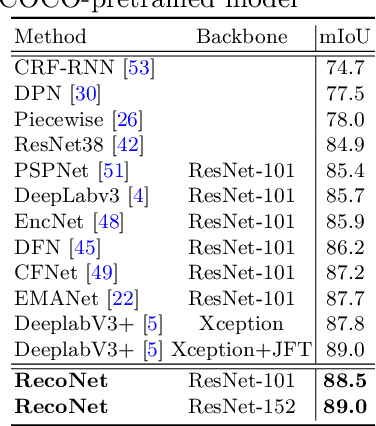
Context information plays an indispensable role in the success of semantic segmentation. Recently, non-local self-attention based methods are proved to be effective for context information collection. Since the desired context consists of spatial-wise and channel-wise attentions, 3D representation is an appropriate formulation. However, these non-local methods describe 3D context information based on a 2D similarity matrix, where space compression may lead to channel-wise attention missing. An alternative is to model the contextual information directly without compression. However, this effort confronts a fundamental difficulty, namely the high-rank property of context information. In this paper, we propose a new approach to model the 3D context representations, which not only avoids the space compression but also tackles the high-rank difficulty. Here, inspired by tensor canonical-polyadic decomposition theory (i.e, a high-rank tensor can be expressed as a combination of rank-1 tensors.), we design a low-rank-to-high-rank context reconstruction framework (i.e, RecoNet). Specifically, we first introduce the tensor generation module (TGM), which generates a number of rank-1 tensors to capture fragments of context feature. Then we use these rank-1 tensors to recover the high-rank context features through our proposed tensor reconstruction module (TRM). Extensive experiments show that our method achieves state-of-the-art on various public datasets. Additionally, our proposed method has more than 100 times less computational cost compared with conventional non-local-based methods.
VLSI Mask Optimization: From Shallow To Deep Learning
Dec 16, 2019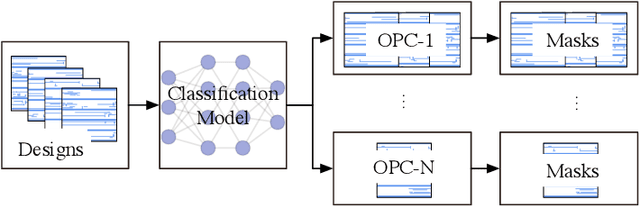
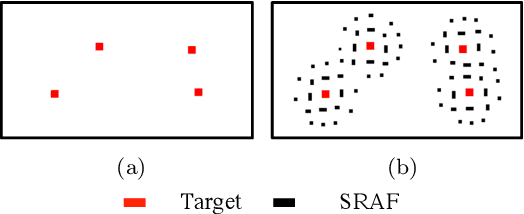
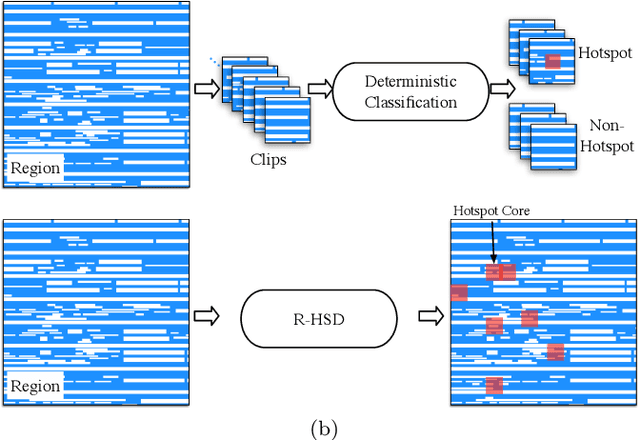
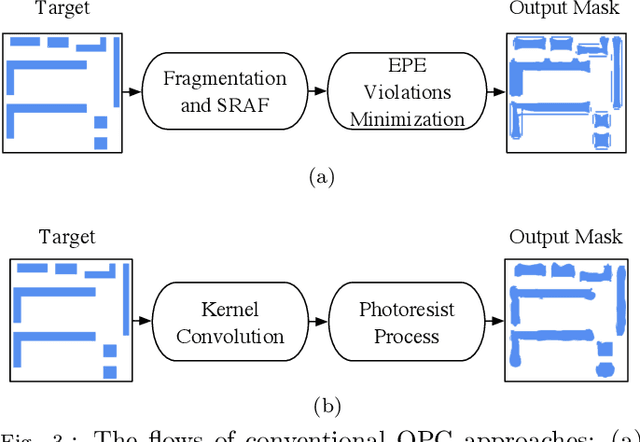
VLSI mask optimization is one of the most critical stages in manufacturability aware design, which is costly due to the complicated mask optimization and lithography simulation. Recent researches have shown prominent advantages of machine learning techniques dealing with complicated and big data problems, which bring potential of dedicated machine learning solution for DFM problems and facilitate the VLSI design cycle. In this paper, we focus on a heterogeneous OPC framework that assists mask layout optimization. Preliminary results show the efficiency and effectiveness of proposed frameworks that have the potential to be alternatives to existing EDA solutions.
Prostate Segmentation using 2D Bridged U-net
Oct 16, 2018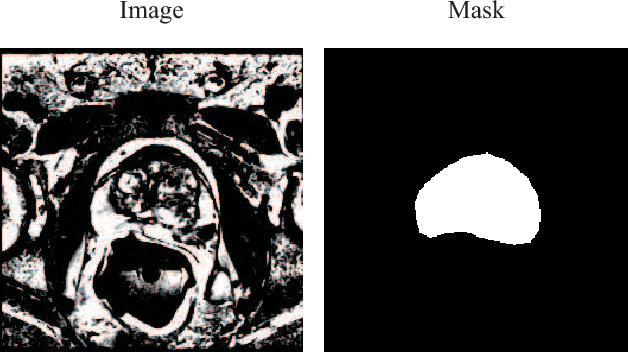



In this paper, we focus on three problems in deep learning based medical image segmentation. Firstly, U-net, as a popular model for medical image segmentation, is difficult to train when convolutional layers increase even though a deeper network usually has a better generalization ability because of more learnable parameters. Secondly, the exponential ReLU (ELU), as an alternative of ReLU, is not much different from ReLU when the network of interest gets deep. Thirdly, the Dice loss, as one of the pervasive loss functions for medical image segmentation, is not effective when the prediction is close to ground truth and will cause oscillation during training. To address the aforementioned three problems, we propose and validate a deeper network that can fit medical image datasets that are usually small in the sample size. Meanwhile, we propose a new loss function to accelerate the learning process and a combination of different activation functions to improve the network performance. Our experimental results suggest that our network is comparable or superior to state-of-the-art methods.
A post-processing method to improve the white matter hyperintensity segmentation accuracy for randomly-initialized U-net
Jul 21, 2018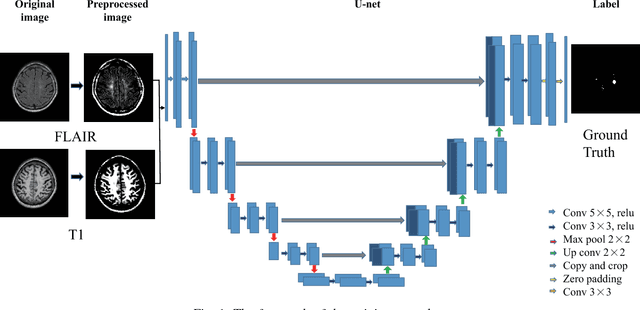

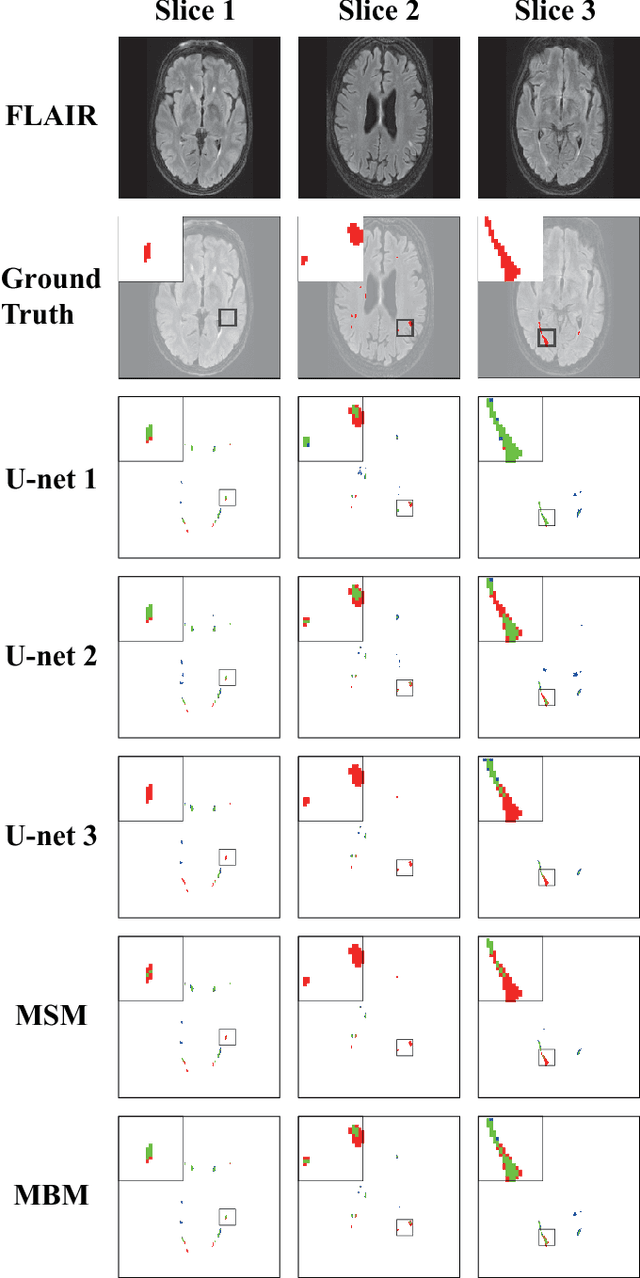
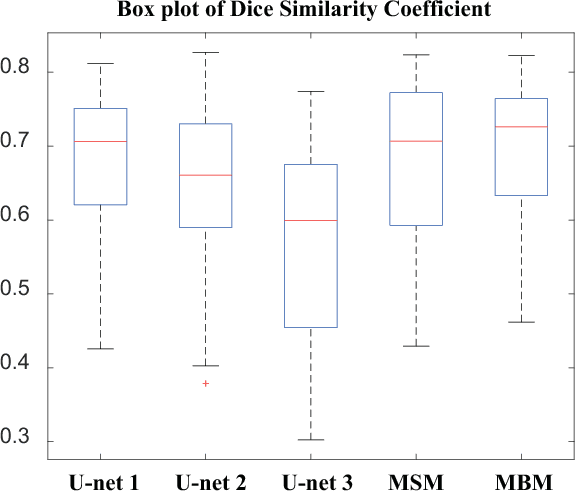
White matter hyperintensity (WMH) is commonly found in elder individuals and appears to be associated with brain diseases. U-net is a convolutional network that has been widely used for biomedical image segmentation. Recently, U-net has been successfully applied to WMH segmentation. Random initialization is usally used to initialize the model weights in the U-net. However, the model may coverage to different local optima with different randomly initialized weights. We find a combination of thresholding and averaging the outputs of U-nets with different random initializations can largely improve the WMH segmentation accuracy. Based on this observation, we propose a post-processing technique concerning the way how averaging and thresholding are conducted. Specifically, we first transfer the score maps from three U-nets to binary masks via thresholding and then average those binary masks to obtain the final WMH segmentation. Both quantitative analysis (via the Dice similarity coefficient) and qualitative analysis (via visual examinations) reveal the superior performance of the proposed method. This post-processing technique is independent of the model used. As such, it can also be applied to situations where other deep learning models are employed, especially when random initialization is adopted and pre-training is unavailable.
Head Mounted Pupil Tracking Using Convolutional Neural Network
Jul 17, 2018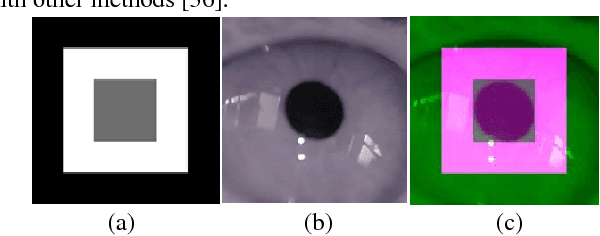
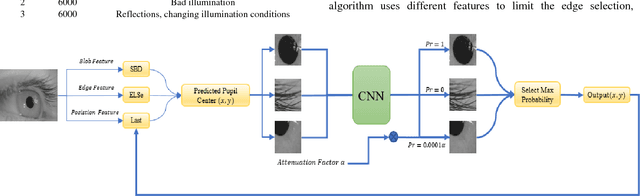

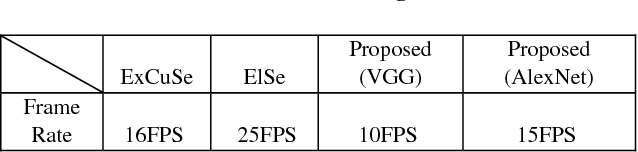
Pupil tracking is an important branch of object tracking which require high precision. We investigate head mounted pupil tracking which is often more convenient and precise than remote pupil tracking, but also more challenging. When pupil tracking suffers from noise like bad illumination, detection precision dramatically decreases. Due to the appearance of head mounted recording device and public benchmark image datasets, head mounted tracking algorithms have become easier to design and evaluate. In this paper, we propose a robust head mounted pupil detection algorithm which uses a Convolutional Neural Network (CNN) to combine different features of pupil. Here we consider three features of pupil. Firstly, we use three pupil feature-based algorithms to find pupil center independently. Secondly, we use a CNN to evaluate the quality of each result. Finally, we select the best result as output. The experimental results show that our proposed algorithm performs better than the present state-of-art.