 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
Paper and Code
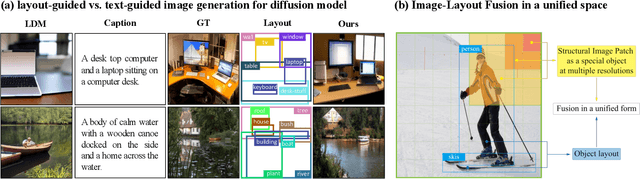
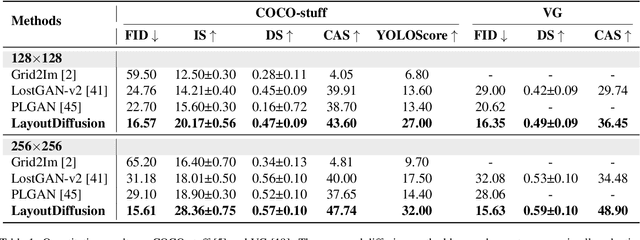
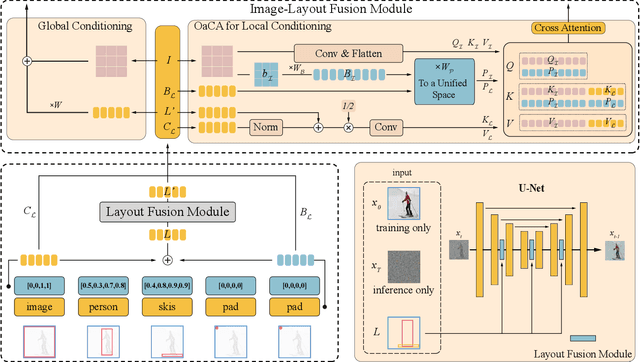

Recently, diffusion models have achieved great success in image synthesis. However, when it comes to the layout-to-image generation where an image often has a complex scene of multiple objects, how to make strong control over both the global layout map and each detailed object remains a challenging task. In this paper, we propose a diffusion model named LayoutDiffusion that can obtain higher generation quality and greater controllability than the previous works. To overcome the difficult multimodal fusion of image and layout, we propose to construct a structural image patch with region information and transform the patched image into a special layout to fuse with the normal layout in a unified form. Moreover, Layout Fusion Module (LFM) and Object-aware Cross Attention (OaCA) are proposed to model the relationship among multiple objects and designed to be object-aware and position-sensitive, allowing for precisely controlling the spatial related information. Extensive experiments show that our LayoutDiffusion outperforms the previous SOTA methods on FID, CAS by relatively 46.35%, 26.70% on COCO-stuff and 44.29%, 41.82% on VG. Code is available at https://github.com/ZGCTroy/LayoutDiffusion.