 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Grammatical Compositional Model for Video Action Detection
Paper and Code
Oct 04, 2023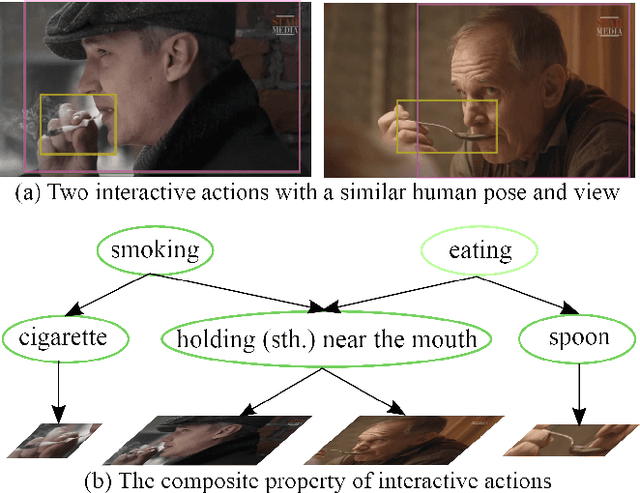

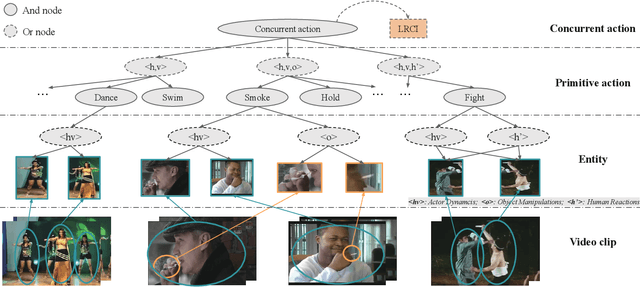

Analysis of human actions in videos demands understanding complex human dynamics, as well as the interaction between actors and context. However, these interaction relationships usually exhibit large intra-class variations from diverse human poses or object manipulations, and fine-grained inter-class differences between similar actions. Thus the performance of existing methods is severely limited. Motivated by the observation that interactive actions can be decomposed into actor dynamics and participating objects or humans, we propose to investigate the composite property of them. In this paper, we present a novel Grammatical Compositional Model (GCM) for action detection based on typical And-Or graphs. Our model exploits the intrinsic structures and latent relationships of actions in a hierarchical manner to harness both the compositionality of grammar models and the capability of expressing rich features of DNNs. The proposed model can be readily embodied into a neural network module for efficient optimization in an end-to-end manner. Extensive experiments are conducted on the AVA dataset and the Something-Else task to demonstrate the superiority of our model, meanwhile the interpretability is enhanced through an inference parsing procedure.