 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARE: Aligning LLM Agents with the R Statistical Ecosystem via Distribution-Aware Retrieval
Mar 05, 2026Large Language Model (LLM) agents can automate data-science workflows, but many rigorous statistical methods implemented in R remain underused because LLMs struggle with statistical knowledge and tool retrieval. Existing retrieval-augmented approaches focus on function-level semantics and ignore data distribution, producing suboptimal matches. We propose DARE (Distribution-Aware Retrieval Embedding), a lightweight, plug-and-play retrieval model that incorporates data distribution information into function representations for R package retrieval. Our main contributions are: (i) RPKB, a curated R Package Knowledge Base derived from 8,191 high-quality CRAN packages; (ii) DARE, an embedding model that fuses distributional features with function metadata to improve retrieval relevance; and (iii) RCodingAgent, an R-oriented LLM agent for reliable R code generation and a suite of statistical analysis tasks for systematically evaluating LLM agents in realistic analytical scenarios. Empirically, DARE achieves an NDCG at 10 of 93.47%, outperforming state-of-the-art open-source embedding models by up to 17% on package retrieval while using substantially fewer parameters. Integrating DARE into RCodingAgent yields significant gains on downstream analysis tasks. This work helps narrow the gap between LLM automation and the mature R statistical ecosystem.
Standard Transformers Achieve the Minimax Rate in Nonparametric Regression with $C^{s,λ}$ Targets
Feb 24, 2026The tremendous success of Transformer models in fields such as large language models and computer vision necessitates a rigorous theoretical investigation. To the best of our knowledge, this paper is the first work proving that standard Transformers can approximate Hölder functions $ C^{s,λ}\left([0,1]^{d\times n}\right) $$ (s\in\mathbb{N}_{\geq0},0<λ\leq1) $ under the $L^t$ distance ($t \in [1, \infty]$) with arbitrary precision. Building upon this approximation result, we demonstrate that standard Transformers achieve the minimax optimal rate in nonparametric regression for Hölder target functions. It is worth mentioning that, by introducing two metrics: the size tuple and the dimension vector, we provide a fine-grained characterization of Transformer structures, which facilitates future research on the generalization and optimization errors of Transformers with different structures. As intermediate results, we also derive the upper bounds for the Lipschitz constant of standard Transformers and their memorization capacity, which may be of independent interest. These findings provide theoretical justification for the powerful capabilities of Transformer models.
DSAEval: Evaluating Data Science Agents on a Wide Range of Real-World Data Science Problems
Jan 20, 2026Recent LLM-based data agents aim to automate data science tasks ranging from data analysis to deep learning. However, the open-ended nature of real-world data science problems, which often span multiple taxonomies and lack standard answers, poses a significant challenge for evaluation. To address this, we introduce DSAEval, a benchmark comprising 641 real-world data science problems grounded in 285 diverse datasets, covering both structured and unstructured data (e.g., vision and text). DSAEval incorporates three distinctive features: (1) Multimodal Environment Perception, which enables agents to interpret observations from multiple modalities including text and vision; (2) Multi-Query Interactions, which mirror the iterative and cumulative nature of real-world data science projects; and (3) Multi-Dimensional Evaluation, which provides a holistic assessment across reasoning, code, and results. We systematically evaluate 11 advanced agentic LLMs using DSAEval. Our results show that Claude-Sonnet-4.5 achieves the strongest overall performance, GPT-5.2 is the most efficient, and MiMo-V2-Flash is the most cost-effective. We further demonstrate that multimodal perception consistently improves performance on vision-related tasks, with gains ranging from 2.04% to 11.30%. Overall, while current data science agents perform well on structured data and routine data anlysis workflows, substantial challenges remain in unstructured domains. Finally, we offer critical insights and outline future research directions to advance the development of data science agents.
Complexity of normalized stochastic first-order methods with momentum under heavy-tailed noise
Jun 12, 2025



In this paper, we propose practical normalized stochastic first-order methods with Polyak momentum, multi-extrapolated momentum, and recursive momentum for solving unconstrained optimization problems. These methods employ dynamically updated algorithmic parameters and do not require explicit knowledge of problem-dependent quantities such as the Lipschitz constant or noise bound. We establish first-order oracle complexity results for finding approximate stochastic stationary points under heavy-tailed noise and weakly average smoothness conditions -- both of which are weaker than the commonly used bounded variance and mean-squared smoothness assumptions. Our complexity bounds either improve upon or match the best-known results in the literature. Numerical experiments are presented to demonstrate the practical effectiveness of the proposed methods.
Approximation Bounds for Transformer Networks with Application to Regression
Apr 16, 2025We explore the approximation capabilities of Transformer networks for H\"older and Sobolev functions, and apply these results to address nonparametric regression estimation with dependent observations. First, we establish novel upper bounds for standard Transformer networks approximating sequence-to-sequence mappings whose component functions are H\"older continuous with smoothness index $\gamma \in (0,1]$. To achieve an approximation error $\varepsilon$ under the $L^p$-norm for $p \in [1, \infty]$, it suffices to use a fixed-depth Transformer network whose total number of parameters scales as $\varepsilon^{-d_x n / \gamma}$. This result not only extends existing findings to include the case $p = \infty$, but also matches the best known upper bounds on number of parameters previously obtained for fixed-depth FNNs and RNNs. Similar bounds are also derived for Sobolev functions. Second, we derive explicit convergence rates for the nonparametric regression problem under various $\beta$-mixing data assumptions, which allow the dependence between observations to weaken over time. Our bounds on the sample complexity impose no constraints on weight magnitudes. Lastly, we propose a novel proof strategy to establish approximation bounds, inspired by the Kolmogorov-Arnold representation theorem. We show that if the self-attention layer in a Transformer can perform column averaging, the network can approximate sequence-to-sequence H\"older functions, offering new insights into the interpretability of self-attention mechanisms.
Distribution Matching for Self-Supervised Transfer Learning
Feb 20, 2025In this paper, we propose a novel self-supervised transfer learning method called Distribution Matching (DM), which drives the representation distribution toward a predefined reference distribution while preserving augmentation invariance. The design of DM results in a learned representation space that is intuitively structured and offers easily interpretable hyperparameters. Experimental results across multiple real-world datasets and evaluation metrics demonstrate that DM performs competitively on target classification tasks compared to existing self-supervised transfer learning methods. Additionally, we provide robust theoretical guarantees for DM, including a population theorem and an end-to-end sample theorem. The population theorem bridges the gap between the self-supervised learning task and target classification accuracy, while the sample theorem shows that, even with a limited number of samples from the target domain, DM can deliver exceptional classification performance, provided the unlabeled sample size is sufficiently large.
A Survey on Large Language Model-based Agents for Statistics and Data Science
Dec 18, 2024



In recent years, data science agents powered by Large Language Models (LLMs), known as "data agents," have shown significant potential to transform the traditional data analysis paradigm. This survey provides an overview of the evolution, capabilities, and applications of LLM-based data agents, highlighting their role in simplifying complex data tasks and lowering the entry barrier for users without related expertise. We explore current trends in the design of LLM-based frameworks, detailing essential features such as planning, reasoning, reflection, multi-agent collaboration, user interface, knowledge integration, and system design, which enable agents to address data-centric problems with minimal human intervention. Furthermore, we analyze several case studies to demonstrate the practical applications of various data agents in real-world scenarios. Finally, we identify key challenges and propose future research directions to advance the development of data agents into intelligent statistical analysis software.
LAMBDA: A Large Model Based Data Agent
Jul 24, 2024



We introduce ``LAMBDA," a novel open-source, code-free multi-agent data analysis system that that harnesses the power of large models. LAMBDA is designed to address data analysis challenges in complex data-driven applications through the use of innovatively designed data agents that operate iteratively and generatively using natural language. At the core of LAMBDA are two key agent roles: the programmer and the inspector, which are engineered to work together seamlessly. Specifically, the programmer generates code based on the user's instructions and domain-specific knowledge, enhanced by advanced models. Meanwhile, the inspector debugs the code when necessary. To ensure robustness and handle adverse scenarios, LAMBDA features a user interface that allows direct user intervention in the operational loop. Additionally, LAMBDA can flexibly integrate external models and algorithms through our knowledge integration mechanism, catering to the needs of customized data analysis. LAMBDA has demonstrated strong performance on various machine learning datasets. It has the potential to enhance data science practice and analysis paradigm by seamlessly integrating human and artificial intelligence, making it more accessible, effective, and efficient for individuals from diverse backgrounds. The strong performance of LAMBDA in solving data science problems is demonstrated in several case studies, which are presented at \url{https://www.polyu.edu.hk/ama/cmfai/lambda.html}.
Machine Learning Insides OptVerse AI Solver: Design Principles and Applications
Jan 17, 2024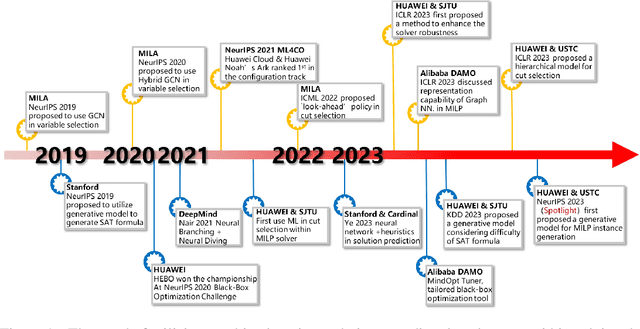
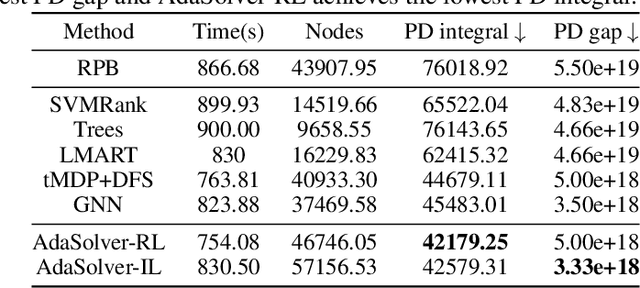

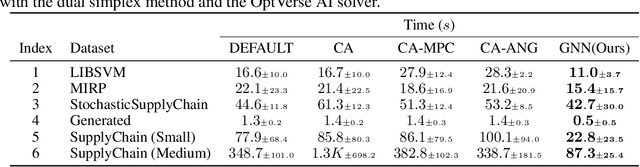
In an era of digital ubiquity, efficient resource management and decision-making are paramount across numerous industries. To this end, we present a comprehensive study on the integration of machine learning (ML) techniques into Huawei Cloud's OptVerse AI Solver, which aims to mitigate the scarcity of real-world mathematical programming instances, and to surpass the capabilities of traditional optimization techniques. We showcase our methods for generating complex SAT and MILP instances utilizing generative models that mirror multifaceted structures of real-world problem. Furthermore, we introduce a training framework leveraging augmentation policies to maintain solvers' utility in dynamic environments. Besides the data generation and augmentation, our proposed approaches also include novel ML-driven policies for personalized solver strategies, with an emphasis on applications like graph convolutional networks for initial basis selection and reinforcement learning for advanced presolving and cut selection. Additionally, we detail the incorporation of state-of-the-art parameter tuning algorithms which markedly elevate solver performance. Compared with traditional solvers such as Cplex and SCIP, our ML-augmented OptVerse AI Solver demonstrates superior speed and precision across both established benchmarks and real-world scenarios, reinforcing the practical imperative and effectiveness of machine learning techniques in mathematical programming solvers.
Randomly Projected Convex Clustering Model: Motivation, Realization, and Cluster Recovery Guarantees
Mar 29, 2023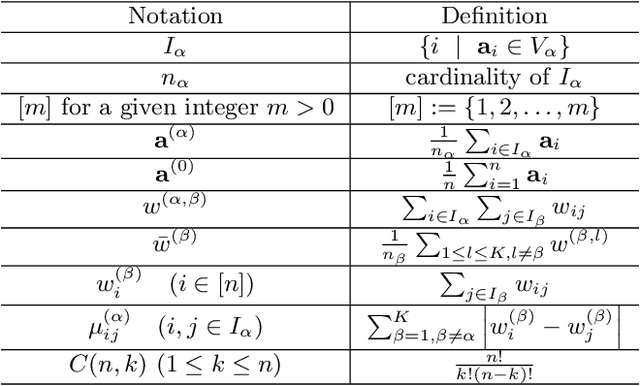
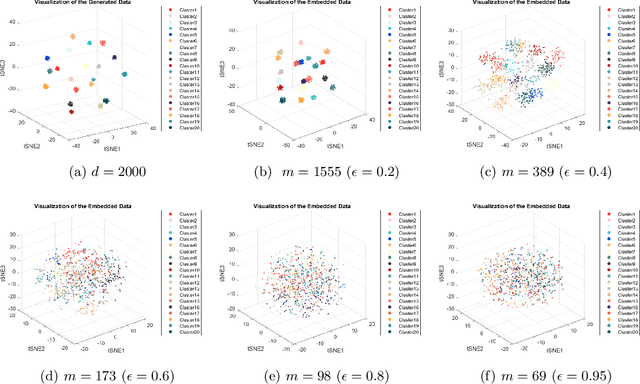

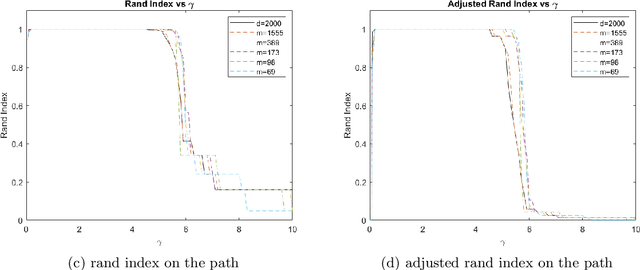
In this paper, we propose a randomly projected convex clustering model for clustering a collection of $n$ high dimensional data points in $\mathbb{R}^d$ with $K$ hidden clusters. Compared to the convex clustering model for clustering original data with dimension $d$, we prove that, under some mild conditions, the perfect recovery of the cluster membership assignments of the convex clustering model, if exists, can be preserved by the randomly projected convex clustering model with embedding dimension $m = O(\epsilon^{-2}\log(n))$, where $0 < \epsilon < 1$ is some given parameter. We further prove that the embedding dimension can be improved to be $O(\epsilon^{-2}\log(K))$, which is independent of the number of data points. Extensive numerical experiment results will be presented in this paper to demonstrate the robustness and superior performance of the randomly projected convex clustering model. The numerical results presented in this paper also demonstrate that the randomly projected convex clustering model can outperform the randomly projected K-means model in practice.