 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
Paper and Code
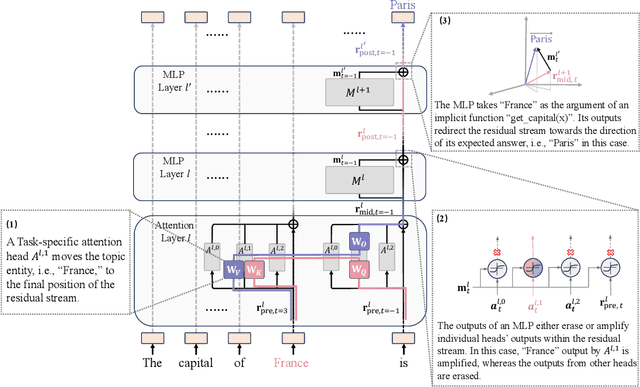

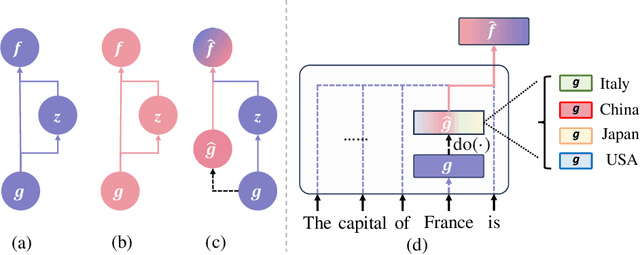

In this paper, we deeply explore the mechanisms employed by Transformer-based language models in factual recall tasks. In zero-shot scenarios, given a prompt like "The capital of France is," task-specific attention heads extract the topic entity, such as "France," from the context and pass it to subsequent MLPs to recall the required answer such as "Paris." We introduce a novel analysis method aimed at decomposing the outputs of the MLP into components understandable by humans. Through this method, we quantify the function of the MLP layer following these task-specific heads. In the residual stream, it either erases or amplifies the information originating from individual heads. Moreover, it generates a component that redirects the residual stream towards the direction of its expected answer. These zero-shot mechanisms are also employed in few-shot scenarios. Additionally, we observed a widely existent anti-overconfidence mechanism in the final layer of models, which suppresses correct predictions. We mitigate this suppression by leveraging our interpretation to improve factual recall performance. Our interpretations have been evaluated across various language models, from the GPT-2 families to 1.3B OPT, and across tasks covering different domains of factual knowledge.