 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelTA: Discriminative Token Credit Assignment for Reinforcement Learning from Verifiable Rewards
May 20, 2026Reinforcement learning from verifiable rewards (RLVR) has emerged as a central technique for improving the reasoning capabilities of large language models. Despite its effectiveness, how response-level rewards translate into token-level probability changes remains poorly understood. We introduce a discriminator view of RLVR updates, showing that the policy-gradient update direction implicitly acts as a linear discriminator over token-gradient vectors and thereby determines which token probabilities are increased or decreased during learning. Under standard sequence-level RLVR, this discriminator is constructed from positive- and negative-side centroids formed by advantage-weighted averaging of token-gradient vectors. However, such centroid construction can be dominated by shared high-frequency patterns, such as formatting tokens, diluting sparse yet discriminative directions that better distinguish high-reward responses from low-reward ones. To address this limitation, we propose $\textbf{DelTA}$, a discriminative token credit assignment method that estimates token coefficients to amplify side-specific token-gradient directions and downweight shared or weakly discriminative ones. These coefficients reweight a self-normalized RLVR surrogate, making the effective side-wise centroids more contrastive and thereby reshaping the RLVR update direction. On seven mathematical benchmarks, DelTA outperforms the strongest same-scale baselines by 3.26 and 2.62 average points on Qwen3-8B-Base and Qwen3-14B-Base, respectively. Additional results on code generation, a different backbone, and out-of-domain evaluations further demonstrate the generalization ability of DelTA.
Multi-view Crowd Tracking Transformer with View-Ground Interactions Under Large Real-World Scenes
Apr 21, 2026Multi-view crowd tracking estimates each person's tracking trajectories on the ground of the scene. Recent research works mainly rely on CNNs-based multi-view crowd tracking architectures, and most of them are evaluated and compared on relatively small datasets, such as Wildtrack and MultiviewX. Since these two datasets are collected in small scenes and only contain tens of frames in the evaluation stage, it is difficult for the current methods to be applied to real-world applications where scene size and occlusion are more complicated. In this paper, we propose a Transformer-based multi-view crowd tracking model, \textit{MVTrackTrans}, which adopts interactions between camera views and the ground plane for enhanced multi-view tracking performance. Besides, for better evaluation, we collect and label two large real-world multi-view tracking datasets, MVCrowdTrack and CityTrack, which contain a much larger scene size over a longer time period. Compared with existing methods on the two large and new datasets, the proposed MVTrackTrans model achieves better performance, demonstrating the advantages of the model design in dealing with large scenes. We believe the proposed datasets and model will push the frontiers of the task to more practical scenarios, and the datasets and code are available at: https://github.com/zqyq/MVTrackTrans.
UltraShape 1.0: High-Fidelity 3D Shape Generation via Scalable Geometric Refinement
Dec 24, 2025In this report, we introduce UltraShape 1.0, a scalable 3D diffusion framework for high-fidelity 3D geometry generation. The proposed approach adopts a two-stage generation pipeline: a coarse global structure is first synthesized and then refined to produce detailed, high-quality geometry. To support reliable 3D generation, we develop a comprehensive data processing pipeline that includes a novel watertight processing method and high-quality data filtering. This pipeline improves the geometric quality of publicly available 3D datasets by removing low-quality samples, filling holes, and thickening thin structures, while preserving fine-grained geometric details. To enable fine-grained geometry refinement, we decouple spatial localization from geometric detail synthesis in the diffusion process. We achieve this by performing voxel-based refinement at fixed spatial locations, where voxel queries derived from coarse geometry provide explicit positional anchors encoded via RoPE, allowing the diffusion model to focus on synthesizing local geometric details within a reduced, structured solution space. Our model is trained exclusively on publicly available 3D datasets, achieving strong geometric quality despite limited training resources. Extensive evaluations demonstrate that UltraShape 1.0 performs competitively with existing open-source methods in both data processing quality and geometry generation. All code and trained models will be released to support future research.
StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason
Jul 03, 2025Reinforcement learning with verifiable rewards (RLVR) is a promising approach for improving the complex reasoning abilities of large language models (LLMs). However, current RLVR methods face two significant challenges: the near-miss reward problem, where a small mistake can invalidate an otherwise correct reasoning process, greatly hindering training efficiency; and exploration stagnation, where models tend to focus on solutions within their ``comfort zone,'' lacking the motivation to explore potentially more effective alternatives. To address these challenges, we propose StepHint, a novel RLVR algorithm that utilizes multi-level stepwise hints to help models explore the solution space more effectively. StepHint generates valid reasoning chains from stronger models and partitions these chains into reasoning steps using our proposed adaptive partitioning method. The initial few steps are used as hints, and simultaneously, multiple-level hints (each comprising a different number of steps) are provided to the model. This approach directs the model's exploration toward a promising solution subspace while preserving its flexibility for independent exploration. By providing hints, StepHint mitigates the near-miss reward problem, thereby improving training efficiency. Additionally, the external reasoning pathways help the model develop better reasoning abilities, enabling it to move beyond its ``comfort zone'' and mitigate exploration stagnation. StepHint outperforms competitive RLVR enhancement methods across six mathematical benchmarks, while also demonstrating superior generalization and excelling over baselines on out-of-domain benchmarks.
Mahalanobis Distance-based Multi-view Optimal Transport for Multi-view Crowd Localization
Sep 03, 2024



Multi-view crowd localization predicts the ground locations of all people in the scene. Typical methods usually estimate the crowd density maps on the ground plane first, and then obtain the crowd locations. However, the performance of existing methods is limited by the ambiguity of the density maps in crowded areas, where local peaks can be smoothed away. To mitigate the weakness of density map supervision, optimal transport-based point supervision methods have been proposed in the single-image crowd localization tasks, but have not been explored for multi-view crowd localization yet. Thus, in this paper, we propose a novel Mahalanobis distance-based multi-view optimal transport (M-MVOT) loss specifically designed for multi-view crowd localization. First, we replace the Euclidean-based transport cost with the Mahalanobis distance, which defines elliptical iso-contours in the cost function whose long-axis and short-axis directions are guided by the view ray direction. Second, the object-to-camera distance in each view is used to adjust the optimal transport cost of each location further, where the wrong predictions far away from the camera are more heavily penalized. Finally, we propose a strategy to consider all the input camera views in the model loss (M-MVOT) by computing the optimal transport cost for each ground-truth point based on its closest camera. Experiments demonstrate the advantage of the proposed method over density map-based or common Euclidean distance-based optimal transport loss on several multi-view crowd localization datasets. Project page: https://vcc.tech/research/2024/MVOT.
A New Robust Partial $p$-Wasserstein-Based Metric for Comparing Distributions
May 06, 2024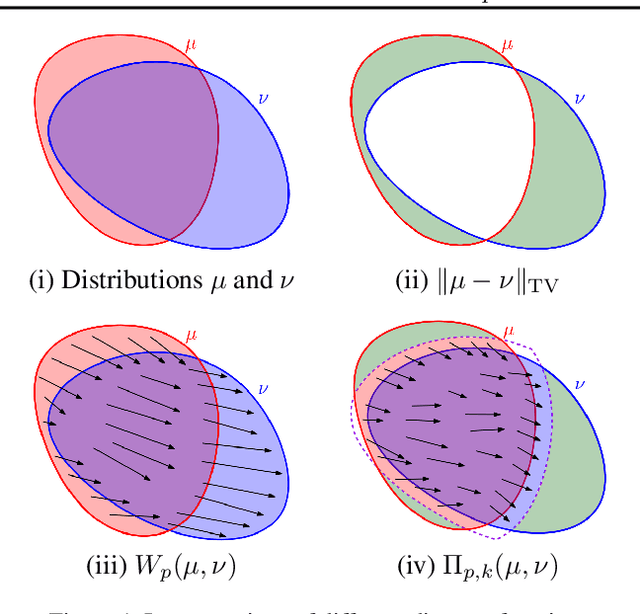
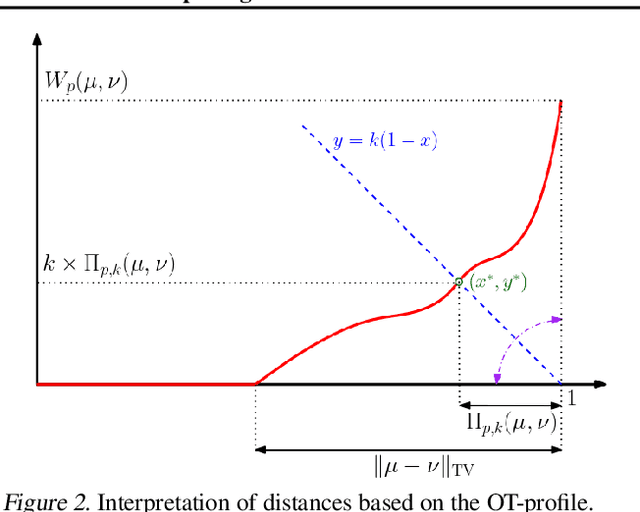
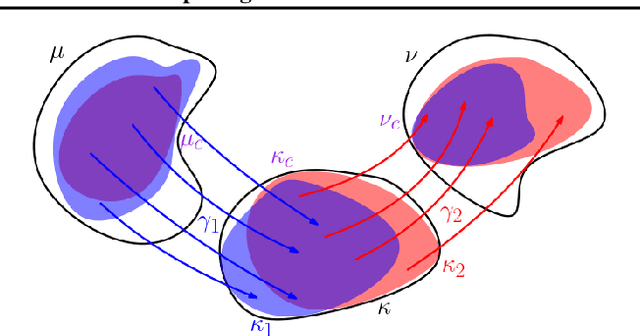
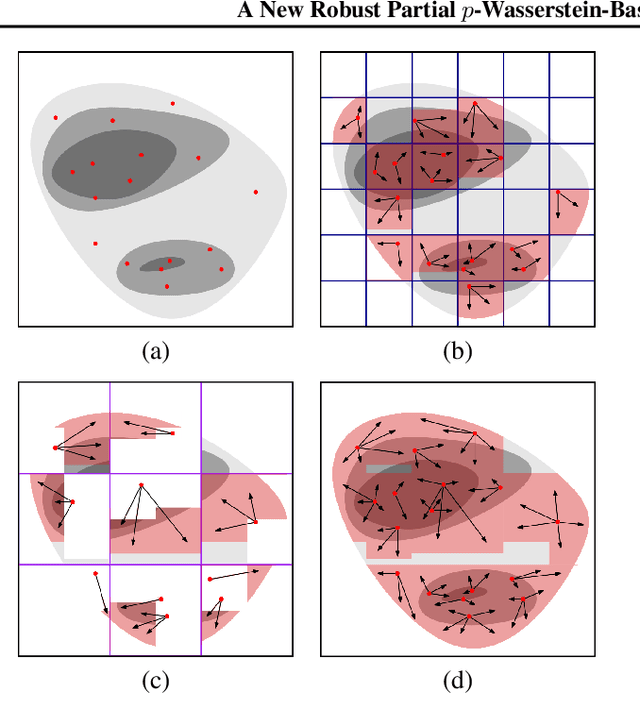
The $2$-Wasserstein distance is sensitive to minor geometric differences between distributions, making it a very powerful dissimilarity metric. However, due to this sensitivity, a small outlier mass can also cause a significant increase in the $2$-Wasserstein distance between two similar distributions. Similarly, sampling discrepancy can cause the empirical $2$-Wasserstein distance on $n$ samples in $\mathbb{R}^2$ to converge to the true distance at a rate of $n^{-1/4}$, which is significantly slower than the rate of $n^{-1/2}$ for $1$-Wasserstein distance. We introduce a new family of distances parameterized by $k \ge 0$, called $k$-RPW, that is based on computing the partial $2$-Wasserstein distance. We show that (1) $k$-RPW satisfies the metric properties, (2) $k$-RPW is robust to small outlier mass while retaining the sensitivity of $2$-Wasserstein distance to minor geometric differences, and (3) when $k$ is a constant, $k$-RPW distance between empirical distributions on $n$ samples in $\mathbb{R}^2$ converges to the true distance at a rate of $n^{-1/3}$, which is faster than the convergence rate of $n^{-1/4}$ for the $2$-Wasserstein distance. Using the partial $p$-Wasserstein distance, we extend our distance to any $p \in [1,\infty]$. By setting parameters $k$ or $p$ appropriately, we can reduce our distance to the total variation, $p$-Wasserstein, and the L\'evy-Prokhorov distances. Experiments show that our distance function achieves higher accuracy in comparison to the $1$-Wasserstein, $2$-Wasserstein, and TV distances for image retrieval tasks on noisy real-world data sets.
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
Apr 09, 2024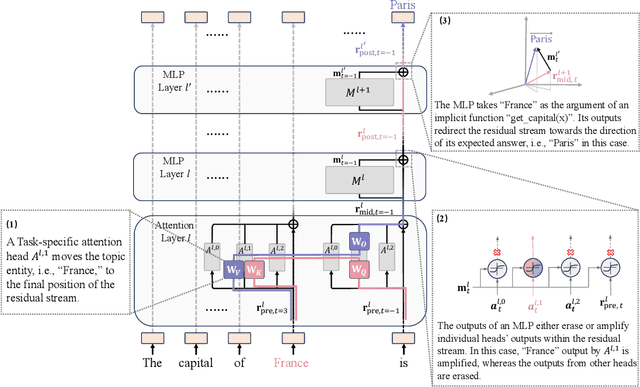


In this paper, we deeply explore the mechanisms employed by Transformer-based language models in factual recall tasks. In zero-shot scenarios, given a prompt like "The capital of France is," task-specific attention heads extract the topic entity, such as "France," from the context and pass it to subsequent MLPs to recall the required answer such as "Paris." We introduce a novel analysis method aimed at decomposing the outputs of the MLP into components understandable by humans. Through this method, we quantify the function of the MLP layer following these task-specific heads. In the residual stream, it either erases or amplifies the information originating from individual heads. Moreover, it generates a component that redirects the residual stream towards the direction of its expected answer. These zero-shot mechanisms are also employed in few-shot scenarios. Additionally, we observed a widely existent anti-overconfidence mechanism in the final layer of models, which suppresses correct predictions. We mitigate this suppression by leveraging our interpretation to improve factual recall performance. Our interpretations have been evaluated across various language models, from the GPT-2 families to 1.3B OPT, and across tasks covering different domains of factual knowledge.
Batch-ICL: Effective, Efficient, and Order-Agnostic In-Context Learning
Jan 12, 2024In this paper, by treating in-context learning (ICL) as a meta-optimization process, we explain why LLMs are sensitive to the order of ICL examples. This understanding leads us to the development of Batch-ICL, an effective, efficient, and order-agnostic inference algorithm for ICL. Differing from the standard N-shot learning approach, Batch-ICL employs $N$ separate 1-shot forward computations and aggregates the resulting meta-gradients. These aggregated meta-gradients are then applied to a zero-shot learning to generate the final prediction. This batch processing approach renders the LLM agnostic to the order of ICL examples. Through extensive experiments and analysis, we demonstrate that Batch-ICL consistently outperforms most permutations of example sequences. In some cases, it even exceeds the performance of the optimal order for standard ICL, all while reducing the computational resources required. Furthermore, we develop a novel variant of Batch-ICL featuring multiple "epochs" of meta-optimization. This variant implicitly explores permutations of ICL examples, further enhancing ICL performance.
Point Cloud Part Editing: Segmentation, Generation, Assembly, and Selection
Dec 19, 2023Ideal part editing should guarantee the diversity of edited parts, the fidelity to the remaining parts, and the quality of the results. However, previous methods do not disentangle each part completely, which means the edited parts will affect the others, resulting in poor diversity and fidelity. In addition, some methods lack constraints between parts, which need manual selections of edited results to ensure quality. Therefore, we propose a four-stage process for point cloud part editing: Segmentation, Generation, Assembly, and Selection. Based on this process, we introduce SGAS, a model for part editing that employs two strategies: feature disentanglement and constraint. By independently fitting part-level feature distributions, we realize the feature disentanglement. By explicitly modeling the transformation from object-level distribution to part-level distributions, we realize the feature constraint. Considerable experiments on different datasets demonstrate the efficiency and effectiveness of SGAS on point cloud part editing. In addition, SGAS can be pruned to realize unsupervised part-aware point cloud generation and achieves state-of-the-art results.
Are We Falling in a Middle-Intelligence Trap? An Analysis and Mitigation of the Reversal Curse
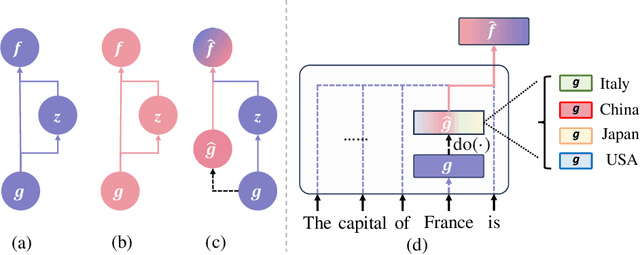
Nov 16, 2023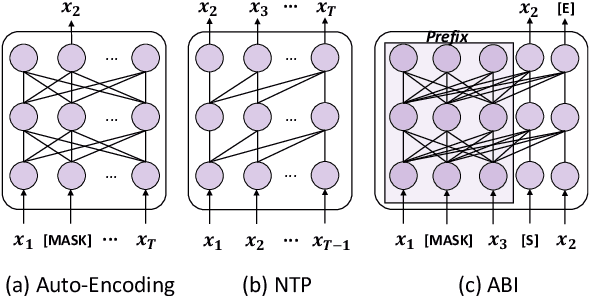
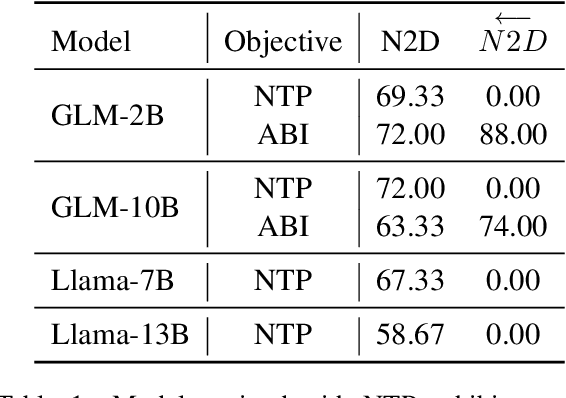

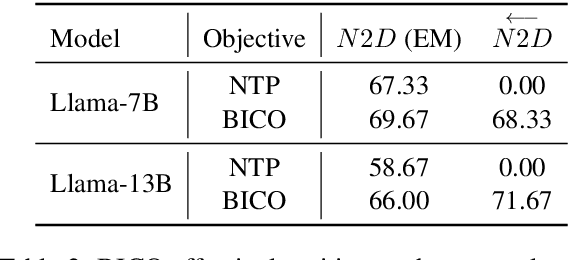
Recent studies have highlighted a phenomenon in large language models (LLMs) known as "the reversal curse," in which the order of knowledge entities in the training data biases the models' comprehension. For example, if a model is trained on sentences where entity A consistently appears before entity B, it can respond to queries about A by providing B as the answer. However, it may encounter confusion when presented with questions concerning B. We contend that the reversal curse is partially a result of specific model training objectives, particularly evident in the prevalent use of the next-token prediction within most causal language models. For the next-token prediction, models solely focus on a token's preceding context, resulting in a restricted comprehension of the input. In contrast, we illustrate that the GLM, trained using the autoregressive blank infilling objective where tokens to be predicted have access to the entire context, exhibits better resilience against the reversal curse. We propose a novel training method, BIdirectional Casual language modeling Optimization (BICO), designed to mitigate the reversal curse when fine-tuning pretrained causal language models on new data. BICO modifies the causal attention mechanism to function bidirectionally and employs a mask denoising optimization. In the task designed to assess the reversal curse, our approach improves Llama's accuracy from the original 0% to around 70%. We hope that more attention can be focused on exploring and addressing these inherent weaknesses of the current LLMs, in order to achieve a higher level of intelligence.