 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwitchable Token-Specific Codebook Quantization For Face Image Compression
Oct 27, 2025With the ever-increasing volume of visual data, the efficient and lossless transmission, along with its subsequent interpretation and understanding, has become a critical bottleneck in modern information systems. The emerged codebook-based solution utilize a globally shared codebook to quantize and dequantize each token, controlling the bpp by adjusting the number of tokens or the codebook size. However, for facial images, which are rich in attributes, such global codebook strategies overlook both the category-specific correlations within images and the semantic differences among tokens, resulting in suboptimal performance, especially at low bpp. Motivated by these observations, we propose a Switchable Token-Specific Codebook Quantization for face image compression, which learns distinct codebook groups for different image categories and assigns an independent codebook to each token. By recording the codebook group to which each token belongs with a small number of bits, our method can reduce the loss incurred when decreasing the size of each codebook group. This enables a larger total number of codebooks under a lower overall bpp, thereby enhancing the expressive capability and improving reconstruction performance. Owing to its generalizable design, our method can be integrated into any existing codebook-based representation learning approach and has demonstrated its effectiveness on face recognition datasets, achieving an average accuracy of 93.51% for reconstructed images at 0.05 bpp.
StepHint: Multi-level Stepwise Hints Enhance Reinforcement Learning to Reason
Jul 03, 2025Reinforcement learning with verifiable rewards (RLVR) is a promising approach for improving the complex reasoning abilities of large language models (LLMs). However, current RLVR methods face two significant challenges: the near-miss reward problem, where a small mistake can invalidate an otherwise correct reasoning process, greatly hindering training efficiency; and exploration stagnation, where models tend to focus on solutions within their ``comfort zone,'' lacking the motivation to explore potentially more effective alternatives. To address these challenges, we propose StepHint, a novel RLVR algorithm that utilizes multi-level stepwise hints to help models explore the solution space more effectively. StepHint generates valid reasoning chains from stronger models and partitions these chains into reasoning steps using our proposed adaptive partitioning method. The initial few steps are used as hints, and simultaneously, multiple-level hints (each comprising a different number of steps) are provided to the model. This approach directs the model's exploration toward a promising solution subspace while preserving its flexibility for independent exploration. By providing hints, StepHint mitigates the near-miss reward problem, thereby improving training efficiency. Additionally, the external reasoning pathways help the model develop better reasoning abilities, enabling it to move beyond its ``comfort zone'' and mitigate exploration stagnation. StepHint outperforms competitive RLVR enhancement methods across six mathematical benchmarks, while also demonstrating superior generalization and excelling over baselines on out-of-domain benchmarks.
PEAR: Position-Embedding-Agnostic Attention Re-weighting Enhances Retrieval-Augmented Generation with Zero Inference Overhead
Sep 29, 2024
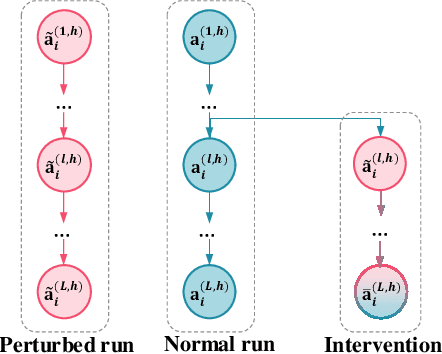
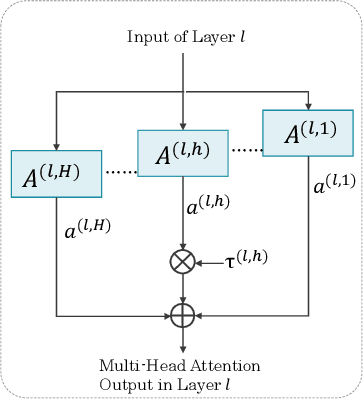

Large language models (LLMs) enhanced with retrieval-augmented generation (RAG) have introduced a new paradigm for web search. However, the limited context awareness of LLMs degrades their performance on RAG tasks. Existing methods to enhance context awareness are often inefficient, incurring time or memory overhead during inference, and many are tailored to specific position embeddings. In this paper, we propose Position-Embedding-Agnostic attention Re-weighting (PEAR), which enhances the context awareness of LLMs with zero inference overhead. Specifically, on a proxy task focused on context copying, we first detect heads which suppress the models' context awareness thereby diminishing RAG performance. To weaken the impact of these heads, we re-weight their outputs with learnable coefficients. The LLM (with frozen parameters) is optimized by adjusting these coefficients to minimize loss on the proxy task. As a result, the coefficients are optimized to values less than one, thereby reducing their tendency to suppress RAG performance. During inference, the optimized coefficients are fixed to re-weight these heads, regardless of the specific task at hand. Our proposed PEAR offers two major advantages over previous approaches: (1) It introduces zero additional inference overhead in terms of memory usage or inference time, while outperforming competitive baselines in accuracy and efficiency across various RAG tasks. (2) It is independent of position embedding algorithms, ensuring broader applicability.
Relation Aware Semi-autoregressive Semantic Parsing for NL2SQL
Aug 02, 2021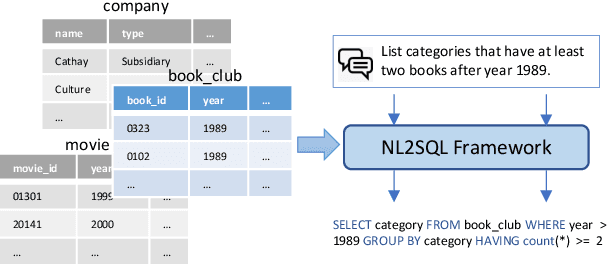
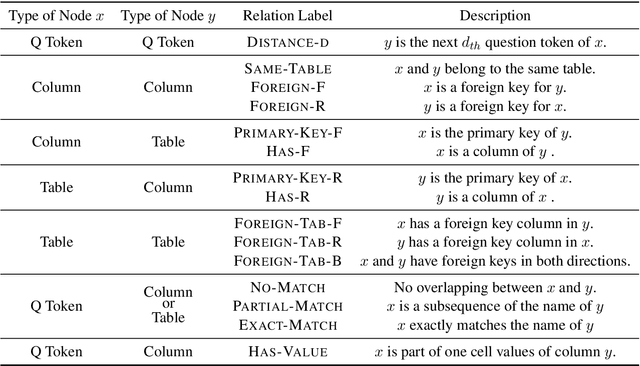
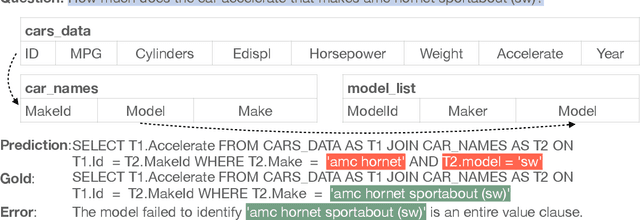
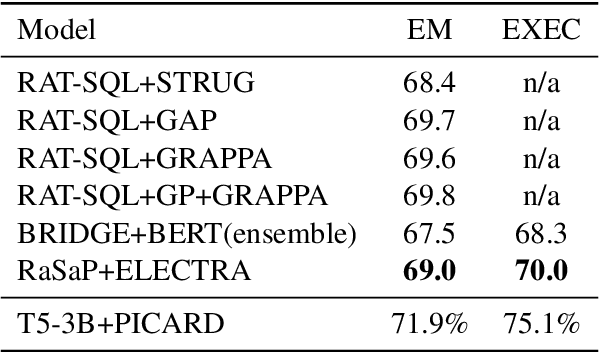
Natural language to SQL (NL2SQL) aims to parse a natural language with a given database into a SQL query, which widely appears in practical Internet applications. Jointly encode database schema and question utterance is a difficult but important task in NL2SQL. One solution is to treat the input as a heterogeneous graph. However, it failed to learn good word representation in question utterance. Learning better word representation is important for constructing a well-designed NL2SQL system. To solve the challenging task, we present a Relation aware Semi-autogressive Semantic Parsing (\MODN) ~framework, which is more adaptable for NL2SQL. It first learns relation embedding over the schema entities and question words with predefined schema relations with ELECTRA and relation aware transformer layer as backbone. Then we decode the query SQL with a semi-autoregressive parser and predefined SQL syntax. From empirical results and case study, our model shows its effectiveness in learning better word representation in NL2SQL.
SeaD: End-to-end Text-to-SQL Generation with Schema-aware Denoising
May 17, 2021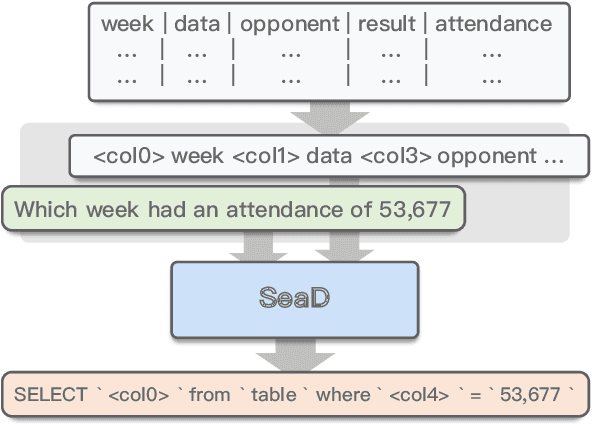
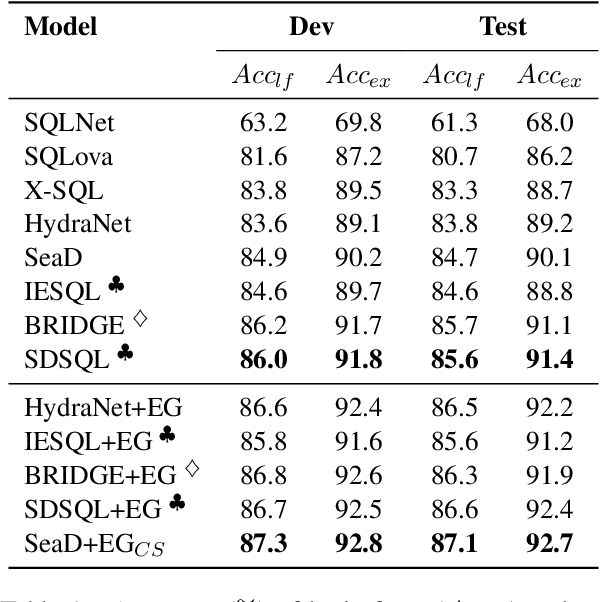

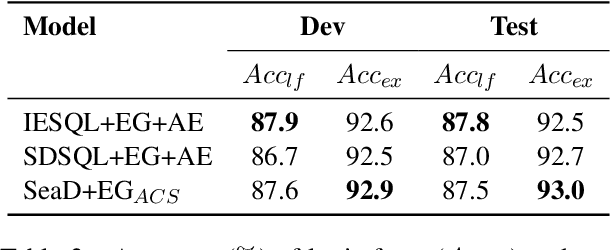
In text-to-SQL task, seq-to-seq models often lead to sub-optimal performance due to limitations in their architecture. In this paper, we present a simple yet effective approach that adapts transformer-based seq-to-seq model to robust text-to-SQL generation. Instead of inducing constraint to decoder or reformat the task as slot-filling, we propose to train seq-to-seq model with Schema aware Denoising (SeaD), which consists of two denoising objectives that train model to either recover input or predict output from two novel erosion and shuffle noises. These denoising objectives acts as the auxiliary tasks for better modeling the structural data in S2S generation. In addition, we improve and propose a clause-sensitive execution guided (EG) decoding strategy to overcome the limitation of EG decoding for generative model. The experiments show that the proposed method improves the performance of seq-to-seq model in both schema linking and grammar correctness and establishes new state-of-the-art on WikiSQL benchmark. The results indicate that the capacity of vanilla seq-to-seq architecture for text-to-SQL may have been under-estimated.
NAIRS: A Neural Attentive Interpretable Recommendation System
Feb 20, 2019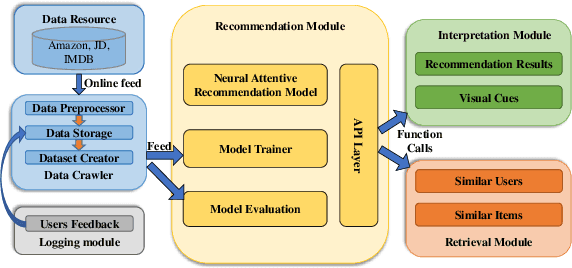


In this paper, we develop a neural attentive interpretable recommendation system, named NAIRS. A self-attention network, as a key component of the system, is designed to assign attention weights to interacted items of a user. This attention mechanism can distinguish the importance of the various interacted items in contributing to a user profile. Based on the user profiles obtained by the self-attention network, NAIRS offers personalized high-quality recommendation. Moreover, it develops visual cues to interpret recommendations. This demo application with the implementation of NAIRS enables users to interact with a recommendation system, and it persistently collects training data to improve the system. The demonstration and experimental results show the effectiveness of NAIRS.