 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePEAR: Position-Embedding-Agnostic Attention Re-weighting Enhances Retrieval-Augmented Generation with Zero Inference Overhead
Sep 29, 2024
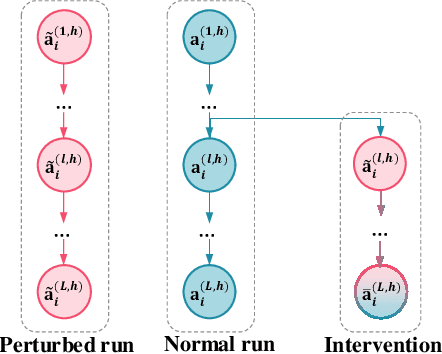
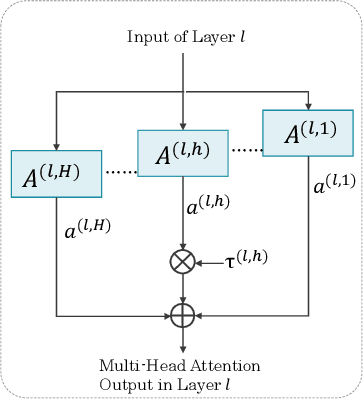

Large language models (LLMs) enhanced with retrieval-augmented generation (RAG) have introduced a new paradigm for web search. However, the limited context awareness of LLMs degrades their performance on RAG tasks. Existing methods to enhance context awareness are often inefficient, incurring time or memory overhead during inference, and many are tailored to specific position embeddings. In this paper, we propose Position-Embedding-Agnostic attention Re-weighting (PEAR), which enhances the context awareness of LLMs with zero inference overhead. Specifically, on a proxy task focused on context copying, we first detect heads which suppress the models' context awareness thereby diminishing RAG performance. To weaken the impact of these heads, we re-weight their outputs with learnable coefficients. The LLM (with frozen parameters) is optimized by adjusting these coefficients to minimize loss on the proxy task. As a result, the coefficients are optimized to values less than one, thereby reducing their tendency to suppress RAG performance. During inference, the optimized coefficients are fixed to re-weight these heads, regardless of the specific task at hand. Our proposed PEAR offers two major advantages over previous approaches: (1) It introduces zero additional inference overhead in terms of memory usage or inference time, while outperforming competitive baselines in accuracy and efficiency across various RAG tasks. (2) It is independent of position embedding algorithms, ensuring broader applicability.
Factor Representation and Decision Making in Stock Markets Using Deep Reinforcement Learning
Aug 03, 2021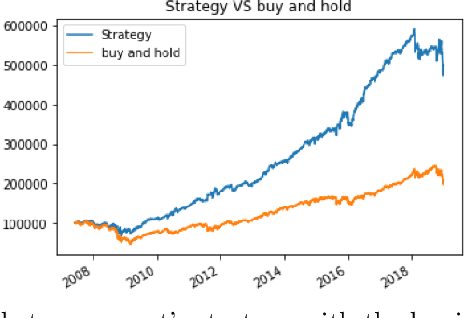



Deep Reinforcement learning is a branch of unsupervised learning in which an agent learns to act based on environment state in order to maximize its total reward. Deep reinforcement learning provides good opportunity to model the complexity of portfolio choice in high-dimensional and data-driven environment by leveraging the powerful representation of deep neural networks. In this paper, we build a portfolio management system using direct deep reinforcement learning to make optimal portfolio choice periodically among S\&P500 underlying stocks by learning a good factor representation (as input). The result shows that an effective learning of market conditions and optimal portfolio allocations can significantly outperform the average market.