 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Novel Clinical-Grade Prostate Cancer Detection and Grading Model: Development and Prospective Validation Using Real World Data, with Performance Assessment on IHC Requested Cases
Oct 31, 2024



Artificial intelligence may assist healthcare systems in meeting increasing demand for pathology services while maintaining diagnostic quality and reducing turnaround time and costs. We aimed to investigate the performance of an institutionally developed system for prostate cancer detection, grading, and workflow optimization and to contrast this with commercial alternatives. From August 2021 to March 2023, we scanned 21,396 slides from 1,147 patients with positive biopsies. We developed models for cancer detection, grading, and screening of equivocal cases for IHC ordering. We compared a task-specific model trained using the PANDA dataset of prostate cancer biopsies with one built using features extracted by the general-purpose histology foundation model, UNI and compare their performance in an unfiltered prospectively collected dataset that reflects our patient population (1737 slides,95 patients). We evaluated the contributions of a bespoke model designed to improve sensitivity in detecting small cancer foci and scoring of broader patterns observed at lower resolution. We found high concordance between the developed systems and pathologist reference in detection (AUC 98.5, sensitivity 95.0, and specificity 97.8), ISUP grading (quadratic Cohen's kappa 0.869), grade group 3 or higher (AUC 97.5, sensitivity 94.9, specificity 96.6) and comparable to published data from commercial systems. Screening could reduce IHC ordering for equivocal cases by 44.5% with an overall error rate of 1.8% (1.4% false positive, 0.4% false negative rates). Institutions like academic medical centers that have high scanning volumes and report abstraction capabilities can develop accurate computational pathology models for internal use. These models have the potential to aid in quality control role and to improve workflow in the pathology lab to help meet future challenges in prostate cancer diagnosis.
ELiTe: Efficient Image-to-LiDAR Knowledge Transfer for Semantic Segmentation
May 07, 2024Cross-modal knowledge transfer enhances point cloud representation learning in LiDAR semantic segmentation. Despite its potential, the \textit{weak teacher challenge} arises due to repetitive and non-diverse car camera images and sparse, inaccurate ground truth labels. To address this, we propose the Efficient Image-to-LiDAR Knowledge Transfer (ELiTe) paradigm. ELiTe introduces Patch-to-Point Multi-Stage Knowledge Distillation, transferring comprehensive knowledge from the Vision Foundation Model (VFM), extensively trained on diverse open-world images. This enables effective knowledge transfer to a lightweight student model across modalities. ELiTe employs Parameter-Efficient Fine-Tuning to strengthen the VFM teacher and expedite large-scale model training with minimal costs. Additionally, we introduce the Segment Anything Model based Pseudo-Label Generation approach to enhance low-quality image labels, facilitating robust semantic representations. Efficient knowledge transfer in ELiTe yields state-of-the-art results on the SemanticKITTI benchmark, outperforming real-time inference models. Our approach achieves this with significantly fewer parameters, confirming its effectiveness and efficiency.
Robust Fine-tuning for Pre-trained 3D Point Cloud Models
Apr 25, 2024This paper presents a robust fine-tuning method designed for pre-trained 3D point cloud models, to enhance feature robustness in downstream fine-tuned models. We highlight the limitations of current fine-tuning methods and the challenges of learning robust models. The proposed method, named Weight-Space Ensembles for Fine-Tuning then Linear Probing (WiSE-FT-LP), integrates the original pre-training and fine-tuning models through weight space integration followed by Linear Probing. This approach significantly enhances the performance of downstream fine-tuned models under distribution shifts, improving feature robustness while maintaining high performance on the target distribution. We apply this robust fine-tuning method to mainstream 3D point cloud pre-trained models and evaluate the quality of model parameters and the degradation of downstream task performance. Experimental results demonstrate the effectiveness of WiSE-FT-LP in enhancing model robustness, effectively balancing downstream task performance and model feature robustness without altering the model structures.
Point Cloud Part Editing: Segmentation, Generation, Assembly, and Selection
Dec 19, 2023Ideal part editing should guarantee the diversity of edited parts, the fidelity to the remaining parts, and the quality of the results. However, previous methods do not disentangle each part completely, which means the edited parts will affect the others, resulting in poor diversity and fidelity. In addition, some methods lack constraints between parts, which need manual selections of edited results to ensure quality. Therefore, we propose a four-stage process for point cloud part editing: Segmentation, Generation, Assembly, and Selection. Based on this process, we introduce SGAS, a model for part editing that employs two strategies: feature disentanglement and constraint. By independently fitting part-level feature distributions, we realize the feature disentanglement. By explicitly modeling the transformation from object-level distribution to part-level distributions, we realize the feature constraint. Considerable experiments on different datasets demonstrate the efficiency and effectiveness of SGAS on point cloud part editing. In addition, SGAS can be pruned to realize unsupervised part-aware point cloud generation and achieves state-of-the-art results.
SRPCN: Structure Retrieval based Point Completion Network
Feb 06, 2022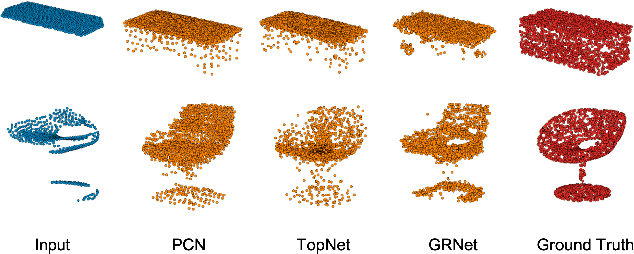
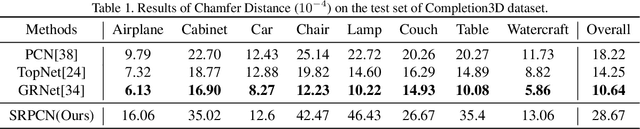
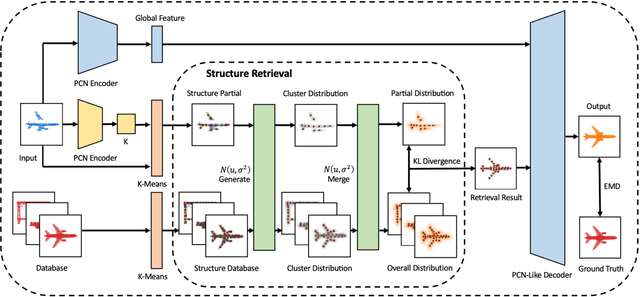
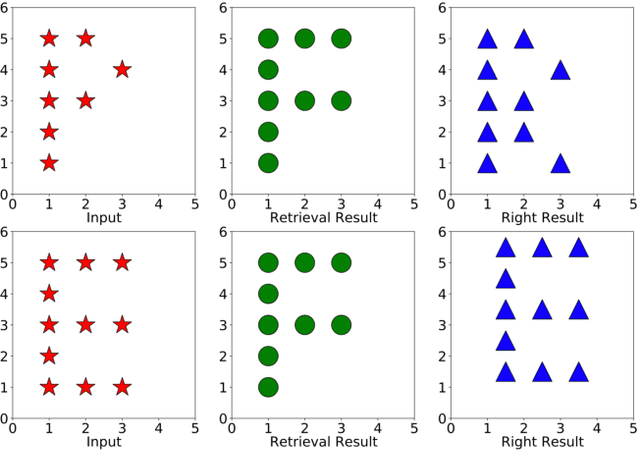
Given partial objects and some complete ones as references, point cloud completion aims to recover authentic shapes. However, existing methods pay little attention to general shapes, which leads to the poor authenticity of completion results. Besides, the missing patterns are diverse in reality, but existing methods can only handle fixed ones, which means a poor generalization ability. Considering that a partial point cloud is a subset of the corresponding complete one, we regard them as different samples of the same distribution and propose Structure Retrieval based Point Completion Network (SRPCN). It first uses k-means clustering to extract structure points and disperses them into distributions, and then KL Divergence is used as a metric to find the complete structure point cloud that best matches the input in a database. Finally, a PCN-like decoder network is adopted to generate the final results based on the retrieved structure point clouds. As structure plays an important role in describing the general shape of an object and the proposed structure retrieval method is robust to missing patterns, experiments show that our method can generate more authentic results and has a stronger generalization ability.
Generate Point Clouds with Multiscale Details from Graph-Represented Structures
Dec 13, 2021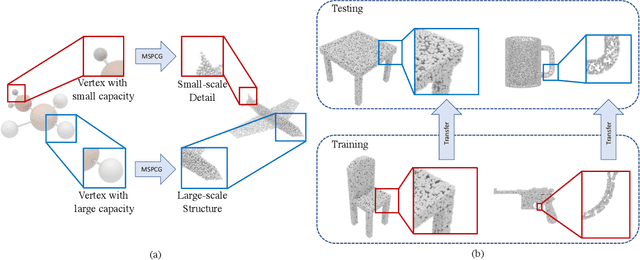
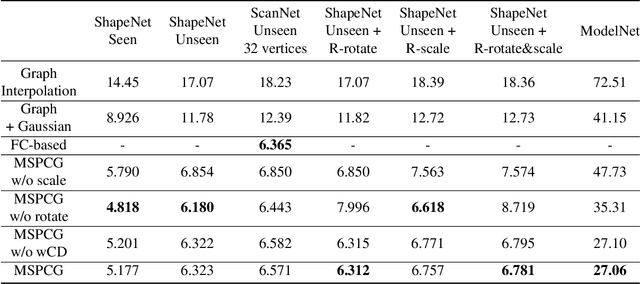
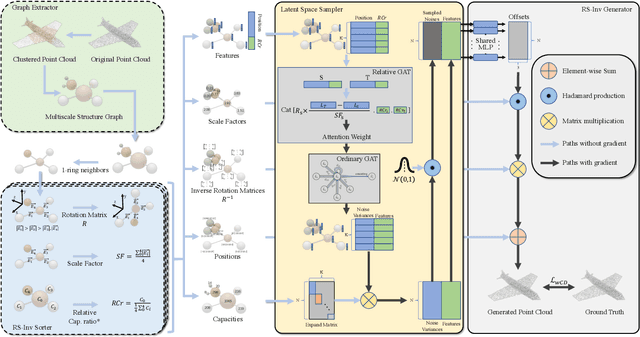

Generating point clouds from structures is a highly valued method to control the generation of point clouds.One of the major problems in structure-based controllable point cloud generation is the lack of controllability to details, as details are missing in most existing representations of structures.It can be observed that definitions of details and structures are subjective.Details can be treated as structures on small scale.To represent structures in different scales at the same time, we present a graph-based representation of structures called the Multiscale Structure Graph(MSG).By treating details as small-scale structures, similar patterns of local structures can be found at different scales, places, densities, and angles.The knowledge learned from a pattern can be transferred to similar patterns in other scales.An encoding and generation mechanism, namely the Multiscale Structure-based Point Cloud Generator(MSPCG), for generating dense point clouds from the MSG is proposed, which can simultaneously learn local patterns with miscellaneous spatial properties.Our MSPCG also has great generalization ability and scalability.An MSPCG trained on the ShapeNet dataset can enable multi-scale edition on point clouds, generate point clouds for unseen categories, and generate indoor scenes from a given structure. The experimental results show that our method significantly outperforms baseline methods.
Attention-based Transformation from Latent Features to Point Clouds
Dec 10, 2021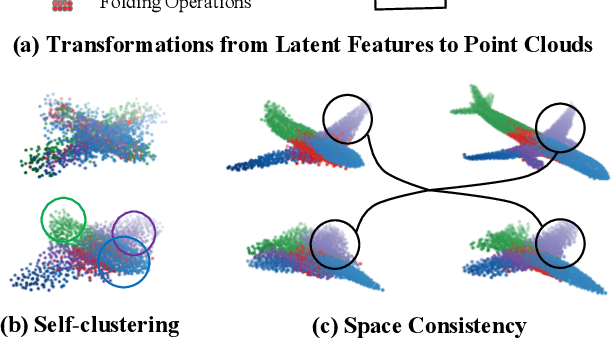
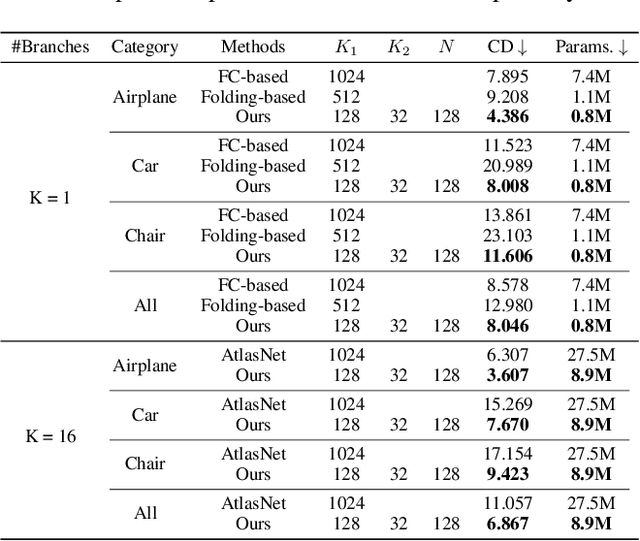
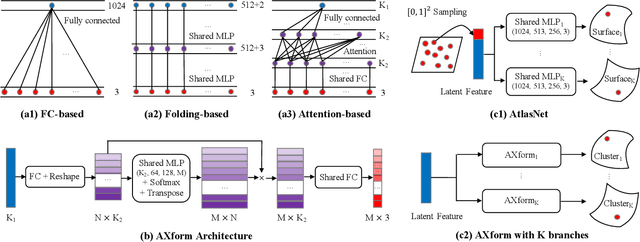
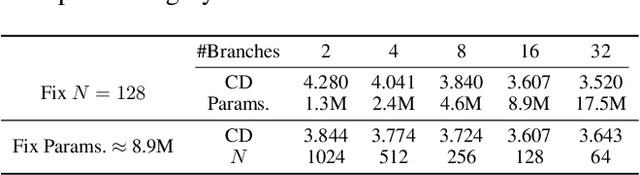
In point cloud generation and completion, previous methods for transforming latent features to point clouds are generally based on fully connected layers (FC-based) or folding operations (Folding-based). However, point clouds generated by FC-based methods are usually troubled by outliers and rough surfaces. For folding-based methods, their data flow is large, convergence speed is slow, and they are also hard to handle the generation of non-smooth surfaces. In this work, we propose AXform, an attention-based method to transform latent features to point clouds. AXform first generates points in an interim space, using a fully connected layer. These interim points are then aggregated to generate the target point cloud. AXform takes both parameter sharing and data flow into account, which makes it has fewer outliers, fewer network parameters, and a faster convergence speed. The points generated by AXform do not have the strong 2-manifold constraint, which improves the generation of non-smooth surfaces. When AXform is expanded to multiple branches for local generations, the centripetal constraint makes it has properties of self-clustering and space consistency, which further enables unsupervised semantic segmentation. We also adopt this scheme and design AXformNet for point cloud completion. Considerable experiments on different datasets show that our methods achieve state-of-the-art results.