 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaSeg: Content-Aware Meta-Net for Omni-Supervised Semantic Segmentation
Jan 22, 2024



Noisy labels, inevitably existing in pseudo segmentation labels generated from weak object-level annotations, severely hampers model optimization for semantic segmentation. Previous works often rely on massive hand-crafted losses and carefully-tuned hyper-parameters to resist noise, suffering poor generalization capability and high model complexity. Inspired by recent advances in meta learning, we argue that rather than struggling to tolerate noise hidden behind clean labels passively, a more feasible solution would be to find out the noisy regions actively, so as to simply ignore them during model optimization. With this in mind, this work presents a novel meta learning based semantic segmentation method, MetaSeg, that comprises a primary content-aware meta-net (CAM-Net) to sever as a noise indicator for an arbitrary segmentation model counterpart. Specifically, CAM-Net learns to generate pixel-wise weights to suppress noisy regions with incorrect pseudo labels while highlighting clean ones by exploiting hybrid strengthened features from image content, providing straightforward and reliable guidance for optimizing the segmentation model. Moreover, to break the barrier of time-consuming training when applying meta learning to common large segmentation models, we further present a new decoupled training strategy that optimizes different model layers in a divide-and-conquer manner. Extensive experiments on object, medical, remote sensing and human segmentation shows that our method achieves superior performance, approaching that of fully supervised settings, which paves a new promising way for omni-supervised semantic segmentation.
Automated Optical Inspection of FAST's Reflector Surface using Drones and Computer Vision
Dec 18, 2022The Five-hundred-meter Aperture Spherical radio Telescope (FAST) is the world's largest single-dish radio telescope. Its large reflecting surface achieves unprecedented sensitivity but is prone to damage, such as dents and holes, caused by naturally-occurring falling objects. Hence, the timely and accurate detection of surface defects is crucial for FAST's stable operation. Conventional manual inspection involves human inspectors climbing up and examining the large surface visually, a time-consuming and potentially unreliable process. To accelerate the inspection process and increase its accuracy, this work makes the first step towards automating the inspection of FAST by integrating deep-learning techniques with drone technology. First, a drone flies over the surface along a predetermined route. Since surface defects significantly vary in scale and show high inter-class similarity, directly applying existing deep detectors to detect defects on the drone imagery is highly prone to missing and misidentifying defects. As a remedy, we introduce cross-fusion, a dedicated plug-in operation for deep detectors that enables the adaptive fusion of multi-level features in a point-wise selective fashion, depending on local defect patterns. Consequently, strong semantics and fine-grained details are dynamically fused at different positions to support the accurate detection of defects of various scales and types. Our AI-powered drone-based automated inspection is time-efficient, reliable, and has good accessibility, which guarantees the long-term and stable operation of FAST.
Dynamic Loss For Robust Learning
Nov 22, 2022



Label noise and class imbalance commonly coexist in real-world data. Previous works for robust learning, however, usually address either one type of the data biases and underperform when facing them both. To mitigate this gap, this work presents a novel meta-learning based dynamic loss that automatically adjusts the objective functions with the training process to robustly learn a classifier from long-tailed noisy data. Concretely, our dynamic loss comprises a label corrector and a margin generator, which respectively correct noisy labels and generate additive per-class classification margins by perceiving the underlying data distribution as well as the learning state of the classifier. Equipped with a new hierarchical sampling strategy that enriches a small amount of unbiased metadata with diverse and hard samples, the two components in the dynamic loss are optimized jointly through meta-learning and cultivate the classifier to well adapt to clean and balanced test data. Extensive experiments show our method achieves state-of-the-art accuracy on multiple real-world and synthetic datasets with various types of data biases, including CIFAR-10/100, Animal-10N, ImageNet-LT, and Webvision. Code will soon be publicly available.
Delving into Sample Loss Curve to Embrace Noisy and Imbalanced Data
Dec 30, 2021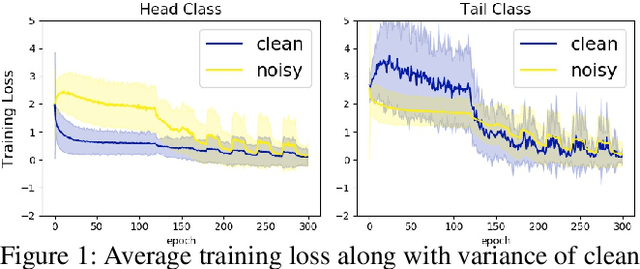
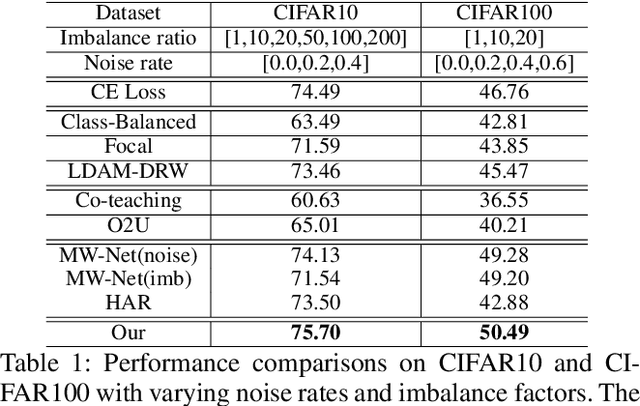
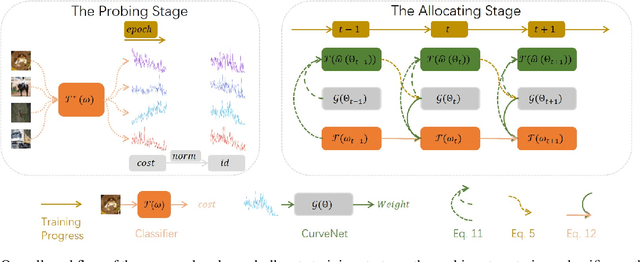
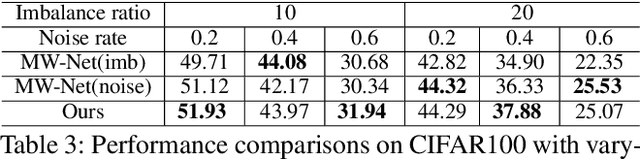
Corrupted labels and class imbalance are commonly encountered in practically collected training data, which easily leads to over-fitting of deep neural networks (DNNs). Existing approaches alleviate these issues by adopting a sample re-weighting strategy, which is to re-weight sample by designing weighting function. However, it is only applicable for training data containing only either one type of data biases. In practice, however, biased samples with corrupted labels and of tailed classes commonly co-exist in training data. How to handle them simultaneously is a key but under-explored problem. In this paper, we find that these two types of biased samples, though have similar transient loss, have distinguishable trend and characteristics in loss curves, which could provide valuable priors for sample weight assignment. Motivated by this, we delve into the loss curves and propose a novel probe-and-allocate training strategy: In the probing stage, we train the network on the whole biased training data without intervention, and record the loss curve of each sample as an additional attribute; In the allocating stage, we feed the resulting attribute to a newly designed curve-perception network, named CurveNet, to learn to identify the bias type of each sample and assign proper weights through meta-learning adaptively. The training speed of meta learning also blocks its application. To solve it, we propose a method named skip layer meta optimization (SLMO) to accelerate training speed by skipping the bottom layers. Extensive synthetic and real experiments well validate the proposed method, which achieves state-of-the-art performance on multiple challenging benchmarks.
Pyramid Correlation based Deep Hough Voting for Visual Object Tracking
Oct 15, 2021

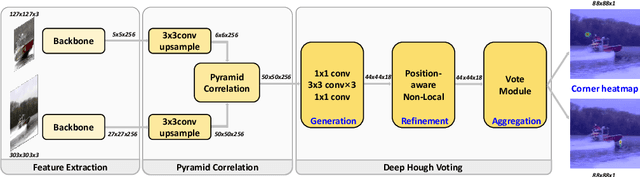

Most of the existing Siamese-based trackers treat tracking problem as a parallel task of classification and regression. However, some studies show that the sibling head structure could lead to suboptimal solutions during the network training. Through experiments we find that, without regression, the performance could be equally promising as long as we delicately design the network to suit the training objective. We introduce a novel voting-based classification-only tracking algorithm named Pyramid Correlation based Deep Hough Voting (short for PCDHV), to jointly locate the top-left and bottom-right corners of the target. Specifically we innovatively construct a Pyramid Correlation module to equip the embedded feature with fine-grained local structures and global spatial contexts; The elaborately designed Deep Hough Voting module further take over, integrating long-range dependencies of pixels to perceive corners; In addition, the prevalent discretization gap is simply yet effectively alleviated by increasing the spatial resolution of the feature maps while exploiting channel-space relationships. The algorithm is general, robust and simple. We demonstrate the effectiveness of the module through a series of ablation experiments. Without bells and whistles, our tracker achieves better or comparable performance to the SOTA algorithms on three challenging benchmarks (TrackingNet, GOT-10k and LaSOT) while running at a real-time speed of 80 FPS. Codes and models will be released.
Stochastic Channel Decorrelation Network and Its Application to Visual Tracking
Aug 20, 2018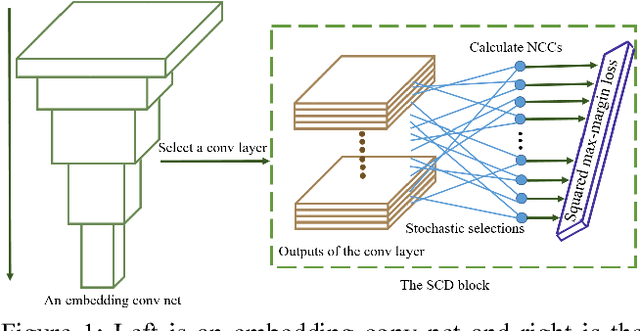
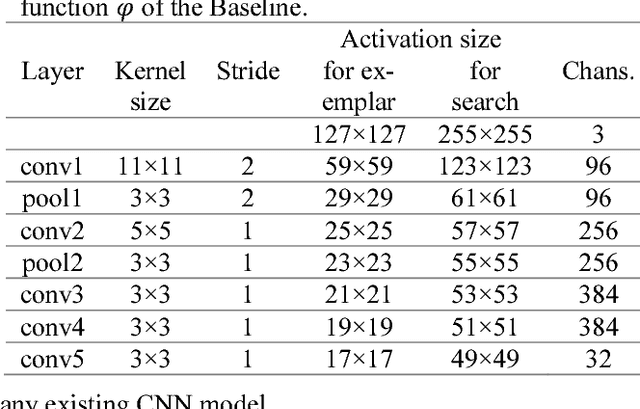
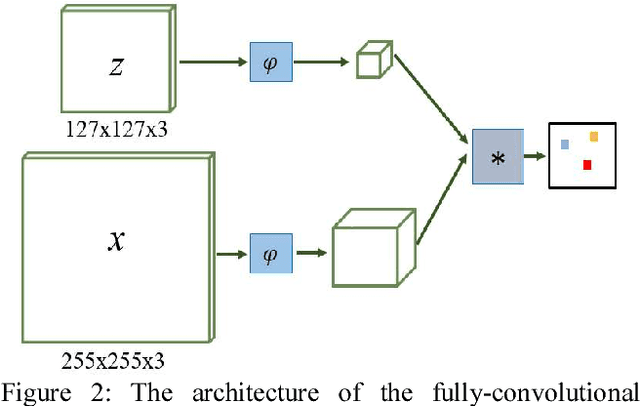

Deep convolutional neural networks (CNNs) have dominated many computer vision domains because of their great power to extract good features automatically. However, many deep CNNs-based computer vison tasks suffer from lack of training data while there are millions of parameters in the deep models. Obviously, these two biphase violation facts will result in parameter redundancy of many poorly designed deep CNNs. Therefore, we look deep into the existing CNNs and find that the redundancy of network parameters comes from the correlation between features in different channels within a convolutional layer. To solve this problem, we propose the stochastic channel decorrelation (SCD) block which, in every iteration, randomly selects multiple pairs of channels within a convolutional layer and calculates their normalized cross correlation (NCC). Then a squared max-margin loss is proposed as the objective of SCD to suppress correlation and keep diversity between channels explicitly. The proposed SCD is very flexible and can be applied to any current existing CNN models simply. Based on the SCD and the Fully-Convolutional Siamese Networks, we proposed a visual tracking algorithm to verify the effectiveness of SCD.