 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Recommendation with User Evolving Preference Decomposition
Mar 31, 2022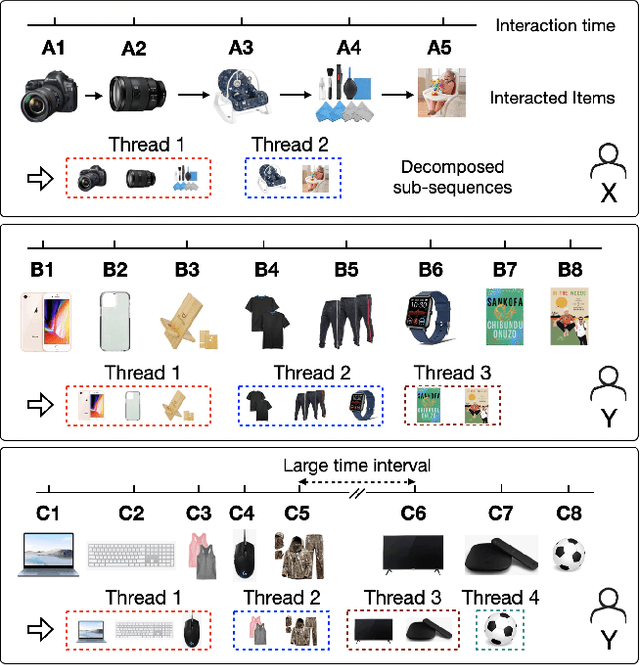
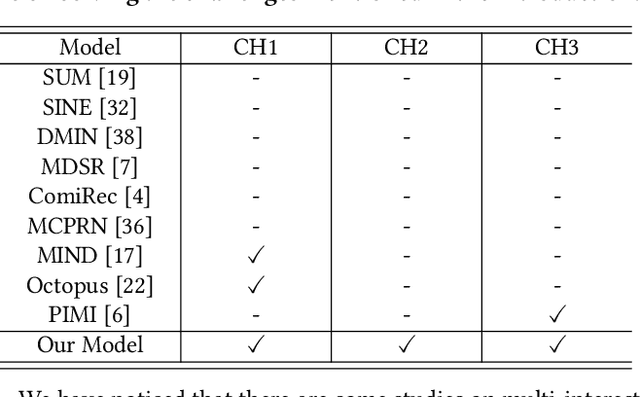
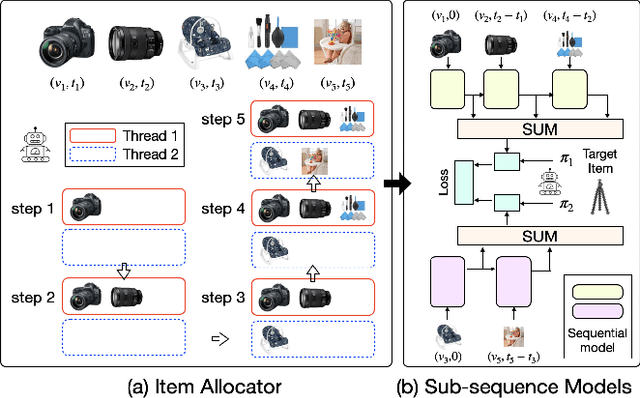
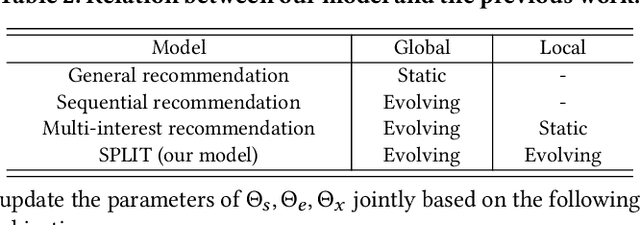
Modeling user sequential behaviors has recently attracted increasing attention in the recommendation domain. Existing methods mostly assume coherent preference in the same sequence. However, user personalities are volatile and easily changed, and there can be multiple mixed preferences underlying user behaviors. To solve this problem, in this paper, we propose a novel sequential recommender model via decomposing and modeling user independent preferences. To achieve this goal, we highlight three practical challenges considering the inconsistent, evolving and uneven nature of the user behavior, which are seldom noticed by the previous work. For overcoming these challenges in a unified framework, we introduce a reinforcement learning module to simulate the evolution of user preference. More specifically, the action aims to allocate each item into a sub-sequence or create a new one according to how the previous items are decomposed as well as the time interval between successive behaviors. The reward is associated with the final loss of the learning objective, aiming to generate sub-sequences which can better fit the training data. We conduct extensive experiments based on six real-world datasets across different domains. Compared with the state-of-the-art methods, empirical studies manifest that our model can on average improve the performance by about 8.21%, 10.08%, 10.32%, and 9.82% on the metrics of Precision, Recall, NDCG and MRR, respectively.
Sequential Recommendation with Adaptive Preference Disentanglement
Dec 06, 2021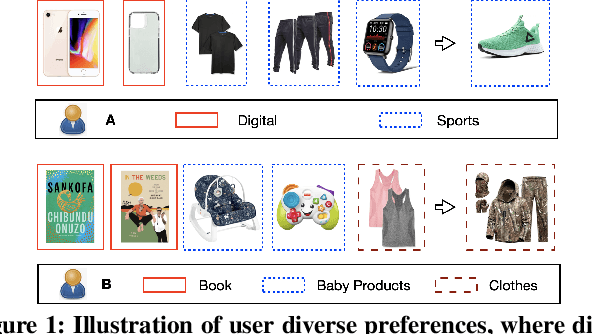
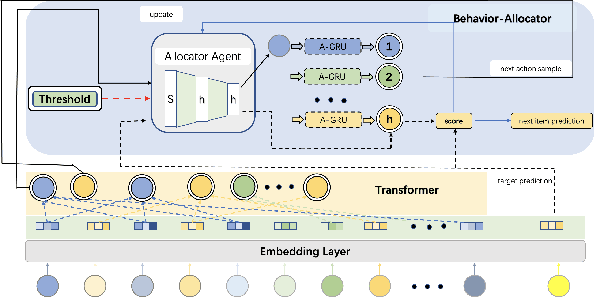
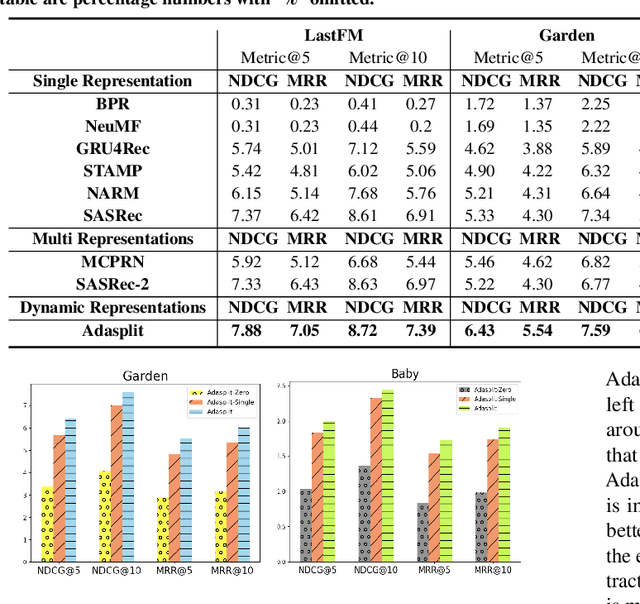
Sequential recommendation holds the promise of being able to infer user preference from the history information. Existing methods mostly assume coherent user preference in the history information, and deploy a unified model to predict the next behavior. However, user preferences are naturally diverse, and different users may enjoy their own personalities, which makes the history information mixed of heterogeneous user preferences. Inspired by this practical consideration, in this paper, we proposed a novel sequential recommender model by disentangling different user preferences. The main building block of our idea is a behavior allocator, which determines how many sub-sequences the history information should be decomposed into, and how to allocate each item into these sub-sequences. In particular, we regard the disentanglement of user preference as a Markov decision process, and design a reinforcement learning method to implement the behavior allocator. The reward in our model is designed to assign the target item to the nearest sub-sequence, and simultaneously encourage orthogonality between the generated sub-sequences. To make the disentangled sub-sequences not too sparse, we introduce a curriculum reward, which adaptively penalizes the action of creating a new sub-sequence. We conduct extensive experiments based on real-world datasets, and compare with many state-of-the-art models to verify the effectiveness of our model. Empirical studies manifest that our model can on average improve the performance by about 7.42$\%$ and 11.98$\%$ on metrics NDCG and MRR, respectively.
Learning Reinforced Dynamic Representations for Sequential Recommendation
Dec 06, 2021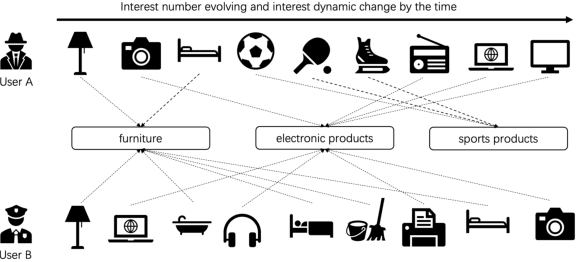
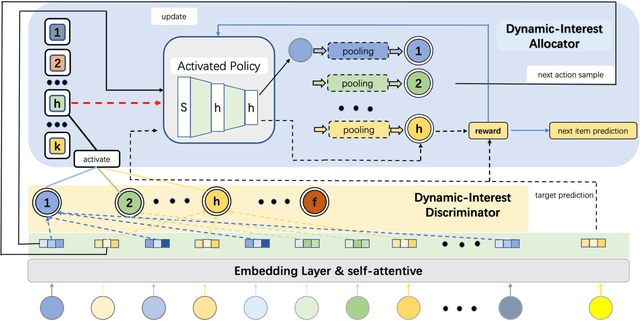

Recently, sequential recommendation systems are important in solving the information overload in many online services. Current methods in sequential recommendation focus on learning a fixed number of representations for each user at any time, with a single representation or multi-interest representations for the user. However, when a user is exploring items on an e-commerce recommendation system, the number of this user's interests may change overtime (e.g. increase/reduce one interest), affected by the user's evolving self needs. Moreover, different users may have various number of interests. In this paper, we argue that it is meaningful to explore a personalized dynamic number of user interests, and learn a dynamic group of user interest representations accordingly. We propose a Reinforced sequential model with dynamic number of interest representations for recommendation systems (RDRSR). Specifically, RDRSR is composed of a dynamic interest discriminator (DID) module and a dynamic interest allocator (DIA) module. The DID module explores the number of a user's interests by learning the overall sequential characteristics with bi-directional self-attention and Gumbel-Softmax. The DIA module allocates the historical clicked items into a group of sub-sequences and constructs user's dynamic interest representations. We formalize the allocation problem in the form of Markov Decision Process(MDP), and sample an action from policy pi for each item to determine which sub-sequence it belongs to. Additionally, experiments on the real-world datasets demonstrates our model's effectiveness.