 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Recommendation with Adaptive Preference Disentanglement
Paper and Code
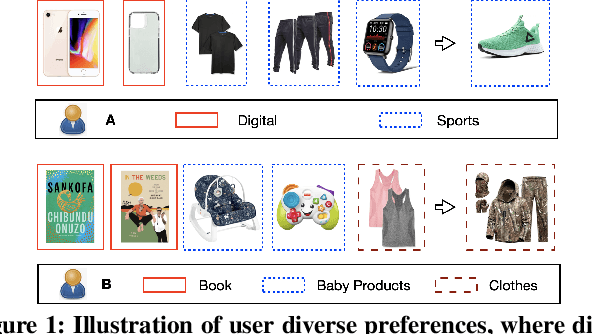
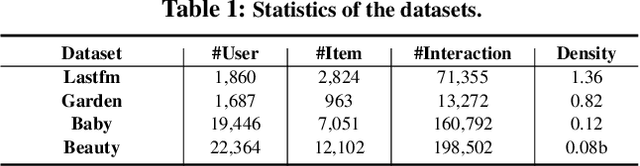
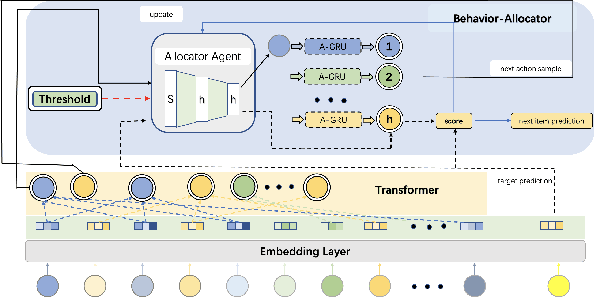
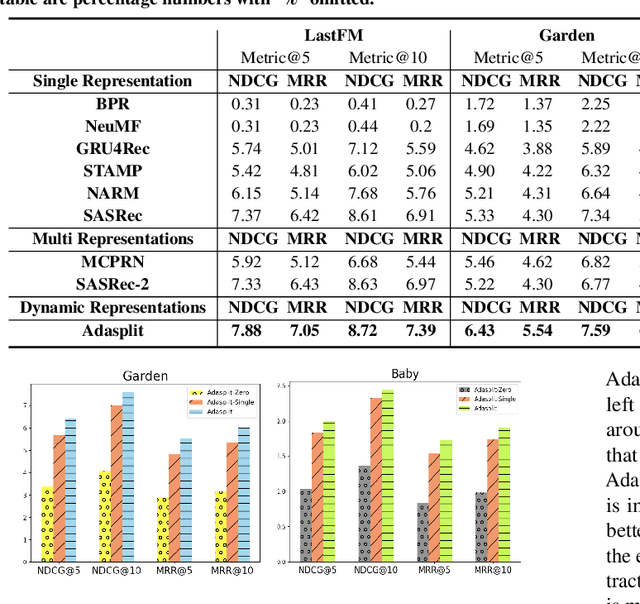
Sequential recommendation holds the promise of being able to infer user preference from the history information. Existing methods mostly assume coherent user preference in the history information, and deploy a unified model to predict the next behavior. However, user preferences are naturally diverse, and different users may enjoy their own personalities, which makes the history information mixed of heterogeneous user preferences. Inspired by this practical consideration, in this paper, we proposed a novel sequential recommender model by disentangling different user preferences. The main building block of our idea is a behavior allocator, which determines how many sub-sequences the history information should be decomposed into, and how to allocate each item into these sub-sequences. In particular, we regard the disentanglement of user preference as a Markov decision process, and design a reinforcement learning method to implement the behavior allocator. The reward in our model is designed to assign the target item to the nearest sub-sequence, and simultaneously encourage orthogonality between the generated sub-sequences. To make the disentangled sub-sequences not too sparse, we introduce a curriculum reward, which adaptively penalizes the action of creating a new sub-sequence. We conduct extensive experiments based on real-world datasets, and compare with many state-of-the-art models to verify the effectiveness of our model. Empirical studies manifest that our model can on average improve the performance by about 7.42$\%$ and 11.98$\%$ on metrics NDCG and MRR, respectively.