 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePix4Point: Image Pretrained Transformers for 3D Point Cloud Understanding
Aug 25, 2022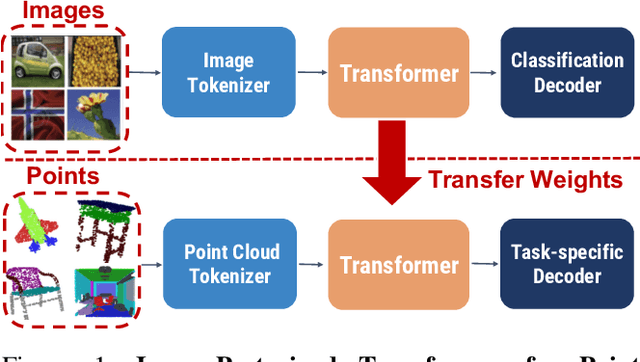
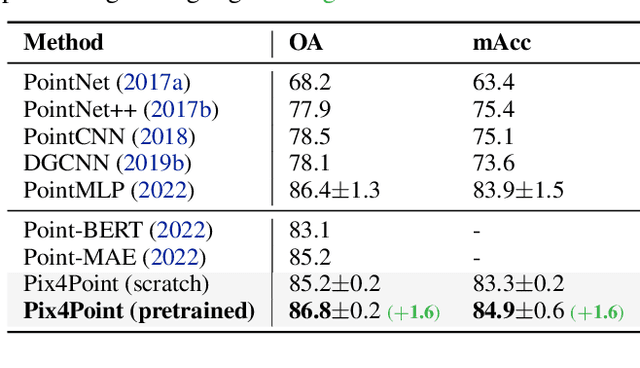
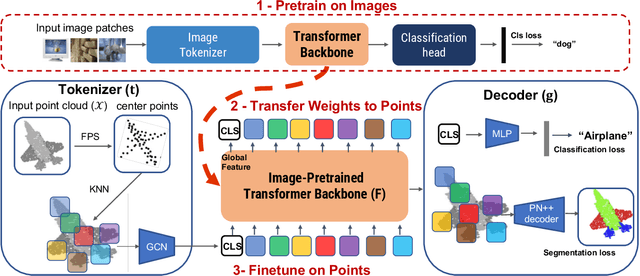
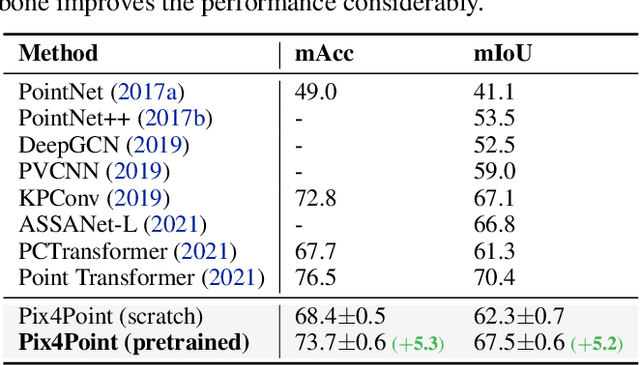
Pure Transformer models have achieved impressive success in natural language processing and computer vision. However, one limitation with Transformers is their need for large training data. In the realm of 3D point clouds, the availability of large datasets is a challenge, which exacerbates the issue of training Transformers for 3D tasks. In this work, we empirically study and investigate the effect of utilizing knowledge from a large number of images for point cloud understanding. We formulate a pipeline dubbed \textit{Pix4Point} that allows harnessing pretrained Transformers in the image domain to improve downstream point cloud tasks. This is achieved by a modality-agnostic pure Transformer backbone with the help of tokenizer and decoder layers specialized in the 3D domain. Using image-pretrained Transformers, we observe significant performance gains of Pix4Point on the tasks of 3D point cloud classification, part segmentation, and semantic segmentation on ScanObjectNN, ShapeNetPart, and S3DIS benchmarks, respectively. Our code and models are available at: \url{https://github.com/guochengqian/Pix4Point}.
DeepLiDAR: Deep Surface Normal Guided Depth Prediction for Outdoor Scene from Sparse LiDAR Data and Single Color Image
Dec 02, 2018
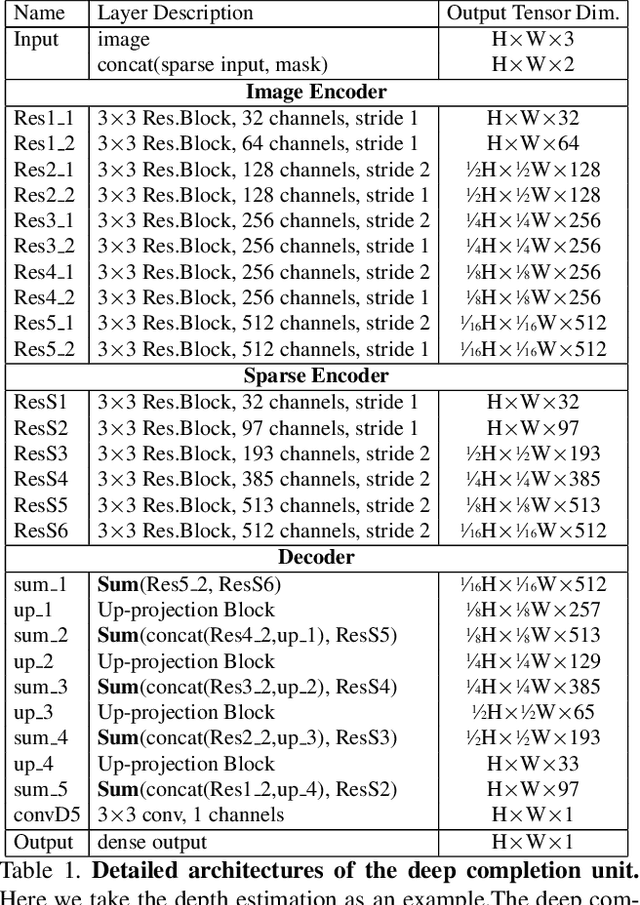
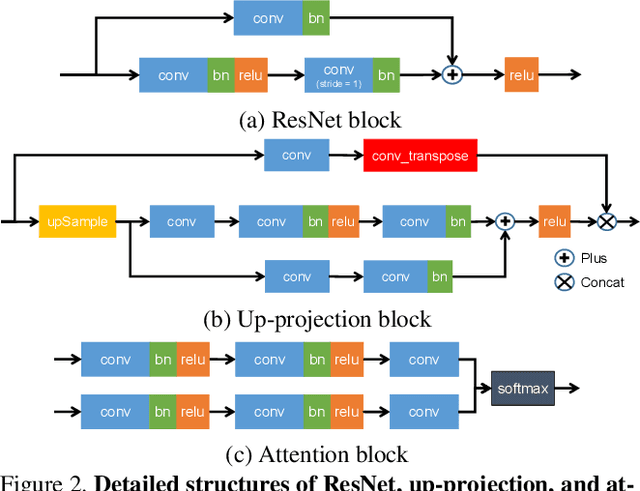
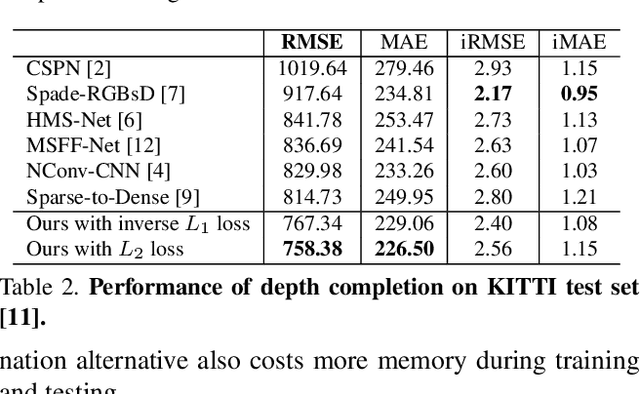
In this paper, we propose a deep learning architecture that produces accurate dense depth for the outdoor scene from a single color image and a sparse depth. Inspired by the indoor depth completion, our network estimates surface normals as the intermediate representation to produce dense depth, and can be trained end-to-end. With a modified encoder-decoder structure, our network effectively fuses the dense color image and the sparse LiDAR depth. To address outdoor specific challenges, our network predicts a confidence mask to handle mixed LiDAR signals near foreground boundaries due to occlusion, and combines estimates from the color image and surface normals with learned attention maps to improve the depth accuracy especially for distant areas. Extensive experiments demonstrate that our model improves upon the state-of-the-art performance on KITTI depth completion benchmark. Ablation study shows the positive impact of each model components to the final performance, and comprehensive analysis shows that our model generalizes well to the input with higher sparsity or from indoor scenes.