 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLateralization MLP: A Simple Brain-inspired Architecture for Diffusion
Paper and Code
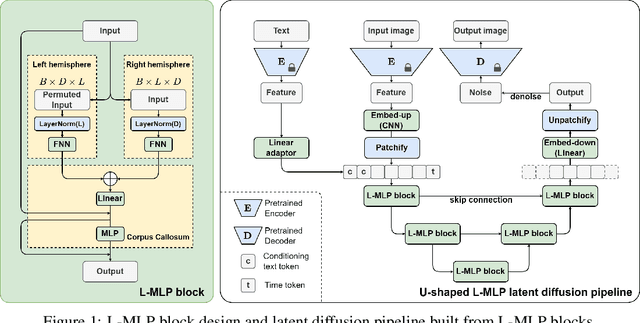
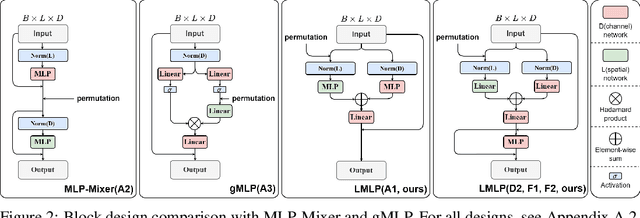
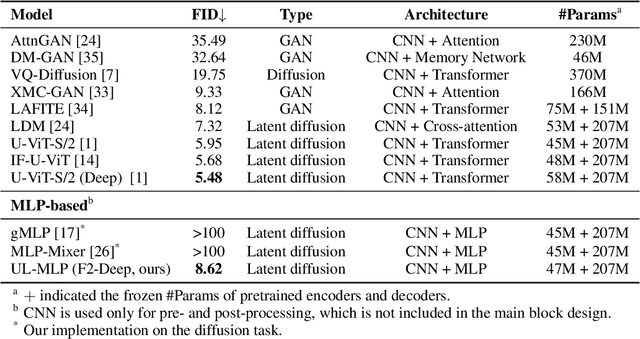
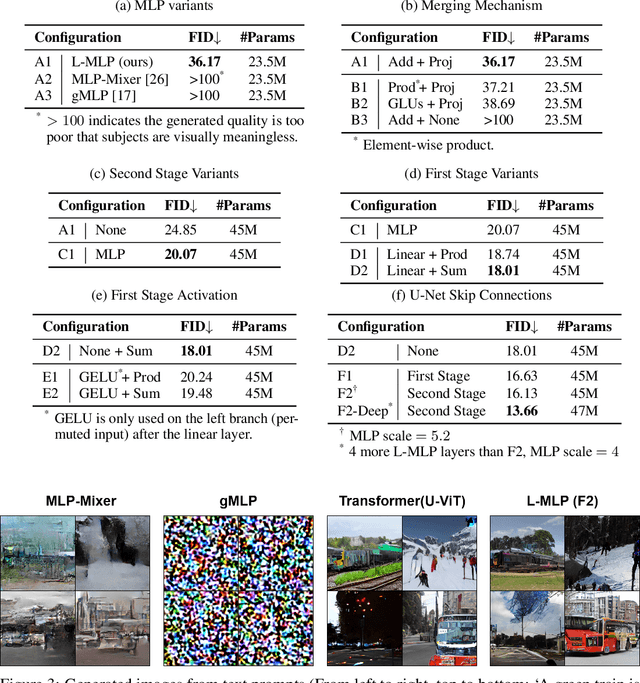
The Transformer architecture has dominated machine learning in a wide range of tasks. The specific characteristic of this architecture is an expensive scaled dot-product attention mechanism that models the inter-token interactions, which is known to be the reason behind its success. However, such a mechanism does not have a direct parallel to the human brain which brings the question if the scaled-dot product is necessary for intelligence with strong expressive power. Inspired by the lateralization of the human brain, we propose a new simple but effective architecture called the Lateralization MLP (L-MLP). Stacking L-MLP blocks can generate complex architectures. Each L-MLP block is based on a multi-layer perceptron (MLP) that permutes data dimensions, processes each dimension in parallel, merges them, and finally passes through a joint MLP. We discover that this specific design outperforms other MLP variants and performs comparably to a transformer-based architecture in the challenging diffusion task while being highly efficient. We conduct experiments using text-to-image generation tasks to demonstrate the effectiveness and efficiency of L-MLP. Further, we look into the model behavior and discover a connection to the function of the human brain. Our code is publicly available: \url{https://github.com/zizhao-hu/L-MLP}