 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multimodal Diffusion Models Using Joint Data Infilling with Partially Shared U-Net
Paper and Code
Nov 28, 2023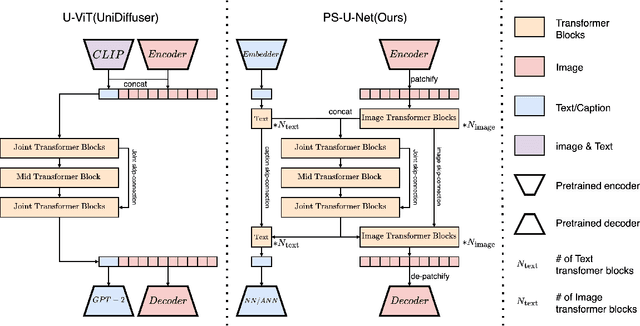
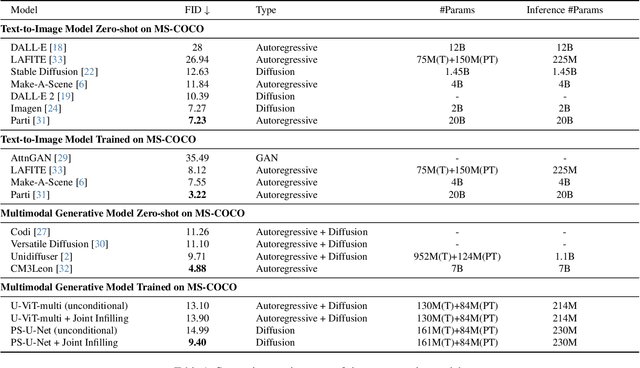
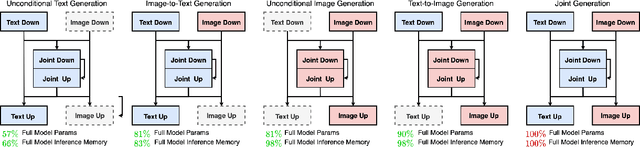
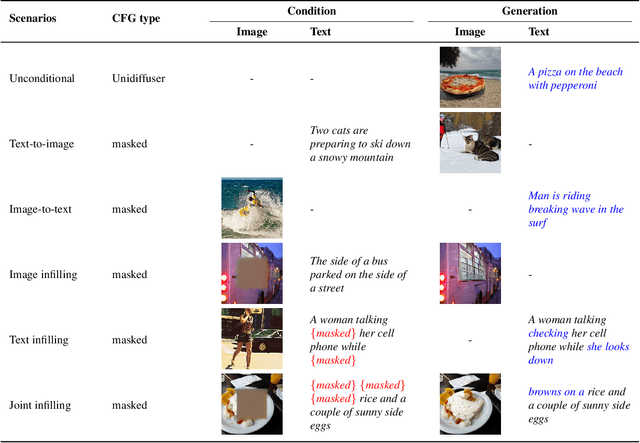
Recently, diffusion models have been used successfully to fit distributions for cross-modal data translation and multimodal data generation. However, these methods rely on extensive scaling, overlooking the inefficiency and interference between modalities. We develop Partially Shared U-Net (PS-U-Net) architecture which is an efficient multimodal diffusion model that allows text and image inputs to pass through dedicated layers and skip-connections for preserving modality-specific fine-grained details. Inspired by image inpainting, we also propose a new efficient multimodal sampling method that introduces new scenarios for conditional generation while only requiring a simple joint distribution to be learned. Our empirical exploration of the MS-COCO dataset demonstrates that our method generates multimodal text and image data with higher quality compared to existing multimodal diffusion models while having a comparable size, faster training, faster multimodal sampling, and more flexible generation.