 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Mining of Naturally Occurring Inputs and Outputs
Paper and Code
May 09, 2022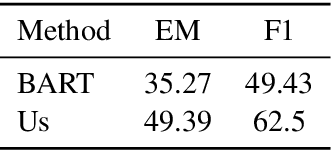
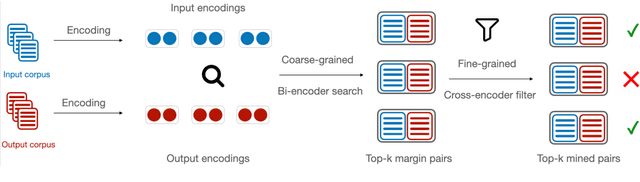
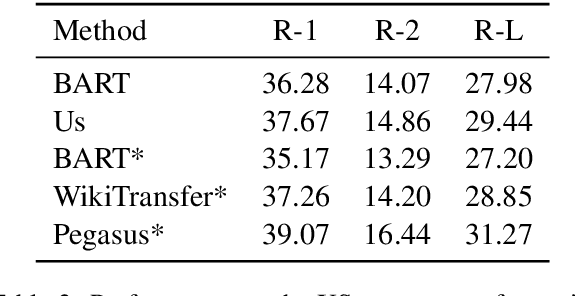

Creating labeled natural language training data is expensive and requires significant human effort. We mine input output examples from large corpora using a supervised mining function trained using a small seed set of only 100 examples. The mining consists of two stages -- (1) a biencoder-based recall-oriented dense search which pairs inputs with potential outputs, and (2) a crossencoder-based filter which re-ranks the output of the biencoder stage for better precision. Unlike model-generated data augmentation, our method mines naturally occurring high-quality input output pairs to mimic the style of the seed set for multiple tasks. On SQuAD-style reading comprehension, augmenting the seed set with the mined data results in an improvement of 13 F1 over a BART-large baseline fine-tuned only on the seed set. Likewise, we see improvements of 1.46 ROUGE-L on Xsum abstractive summarization.