 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempLM: Distilling Language Models into Template-Based Generators
May 23, 2022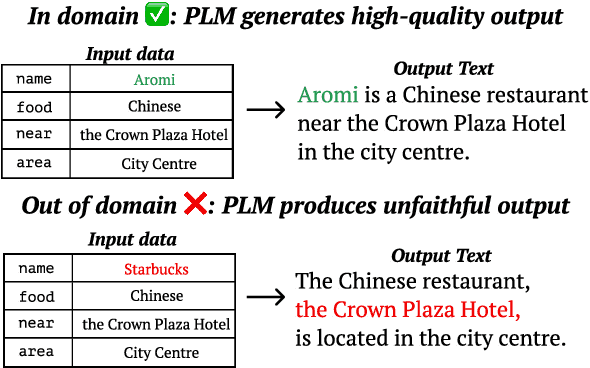

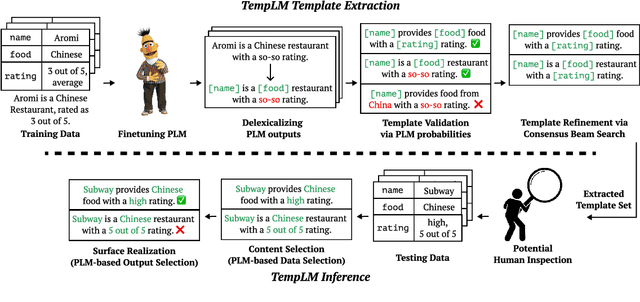

While pretrained language models (PLMs) have greatly improved text generation, they have also been known to produce unfaithful or inappropriate content. In contrast, classic template-based systems provide strong guarantees of faithfulness at the cost of fluency. We propose TempLM, which achieves the best of both worlds by distilling a PLM into a template-based generator. On the E2E and SynthBio data-to-text datasets, we show that TempLM is more faithful than the original PLM and is more fluent than prior template systems. Notably, on an out-of-domain evaluation, TempLM reduces a finetuned BART model's unfaithfulness rate from 83% to 0%. In a human study, we find that TempLM's templates substantially improve upon human-written ones in BERTScore.