 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeCAF: Decentralized Consensus-And-Factorization for Low-Rank Adaptation of Foundation Models
May 27, 2025Low-Rank Adaptation (LoRA) has emerged as one of the most effective, computationally tractable fine-tuning approaches for training Vision-Language Models (VLMs) and Large Language Models (LLMs). LoRA accomplishes this by freezing the pre-trained model weights and injecting trainable low-rank matrices, allowing for efficient learning of these foundation models even on edge devices. However, LoRA in decentralized settings still remains under explored, particularly for the theoretical underpinnings due to the lack of smoothness guarantee and model consensus interference (defined formally below). This work improves the convergence rate of decentralized LoRA (DLoRA) to match the rate of decentralized SGD by ensuring gradient smoothness. We also introduce DeCAF, a novel algorithm integrating DLoRA with truncated singular value decomposition (TSVD)-based matrix factorization to resolve consensus interference. Theoretical analysis shows TSVD's approximation error is bounded and consensus differences between DLoRA and DeCAF vanish as rank increases, yielding DeCAF's matching convergence rate. Extensive experiments across vision/language tasks demonstrate our algorithms outperform local training and rivals federated learning under both IID and non-IID data distributions.
Bidirectional Linear Recurrent Models for Sequence-Level Multisource Fusion
Apr 11, 2025Sequence modeling is a critical yet challenging task with wide-ranging applications, especially in time series forecasting for domains like weather prediction, temperature monitoring, and energy load forecasting. Transformers, with their attention mechanism, have emerged as state-of-the-art due to their efficient parallel training, but they suffer from quadratic time complexity, limiting their scalability for long sequences. In contrast, recurrent neural networks (RNNs) offer linear time complexity, spurring renewed interest in linear RNNs for more computationally efficient sequence modeling. In this work, we introduce BLUR (Bidirectional Linear Unit for Recurrent network), which uses forward and backward linear recurrent units (LRUs) to capture both past and future dependencies with high computational efficiency. BLUR maintains the linear time complexity of traditional RNNs, while enabling fast parallel training through LRUs. Furthermore, it offers provably stable training and strong approximation capabilities, making it highly effective for modeling long-term dependencies. Extensive experiments on sequential image and time series datasets reveal that BLUR not only surpasses transformers and traditional RNNs in accuracy but also significantly reduces computational costs, making it particularly suitable for real-world forecasting tasks. Our code is available here.
FUSE: First-Order and Second-Order Unified SynthEsis in Stochastic Optimization
Mar 06, 2025Stochastic optimization methods have actively been playing a critical role in modern machine learning algorithms to deliver decent performance. While numerous works have proposed and developed diverse approaches, first-order and second-order methods are in entirely different situations. The former is significantly pivotal and dominating in emerging deep learning but only leads convergence to a stationary point. However, second-order methods are less popular due to their computational intensity in large-dimensional problems. This paper presents a novel method that leverages both the first-order and second-order methods in a unified algorithmic framework, termed FUSE, from which a practical version (PV) is derived accordingly. FUSE-PV stands as a simple yet efficient optimization method involving a switch-over between first and second orders. Additionally, we develop different criteria that determine when to switch. FUSE-PV has provably shown a smaller computational complexity than SGD and Adam. To validate our proposed scheme, we present an ablation study on several simple test functions and show a comparison with baselines for benchmark datasets.
Enhancing PPO with Trajectory-Aware Hybrid Policies
Feb 21, 2025



Proximal policy optimization (PPO) is one of the most popular state-of-the-art on-policy algorithms that has become a standard baseline in modern reinforcement learning with applications in numerous fields. Though it delivers stable performance with theoretical policy improvement guarantees, high variance, and high sample complexity still remain critical challenges in on-policy algorithms. To alleviate these issues, we propose Hybrid-Policy Proximal Policy Optimization (HP3O), which utilizes a trajectory replay buffer to make efficient use of trajectories generated by recent policies. Particularly, the buffer applies the "first in, first out" (FIFO) strategy so as to keep only the recent trajectories to attenuate the data distribution drift. A batch consisting of the trajectory with the best return and other randomly sampled ones from the buffer is used for updating the policy networks. The strategy helps the agent to improve its capability on top of the most recent best performance and in turn reduce variance empirically. We theoretically construct the policy improvement guarantees for the proposed algorithm. HP3O is validated and compared against several baseline algorithms using multiple continuous control environments. Our code is available here.
RLS3: RL-Based Synthetic Sample Selection to Enhance Spatial Reasoning in Vision-Language Models for Indoor Autonomous Perception
Jan 31, 2025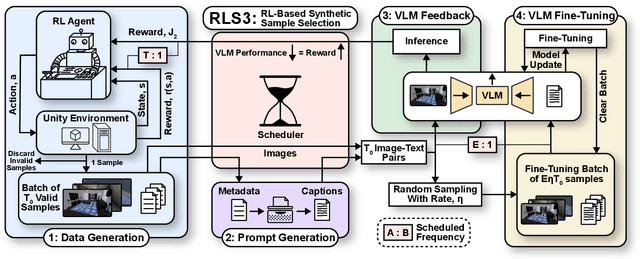
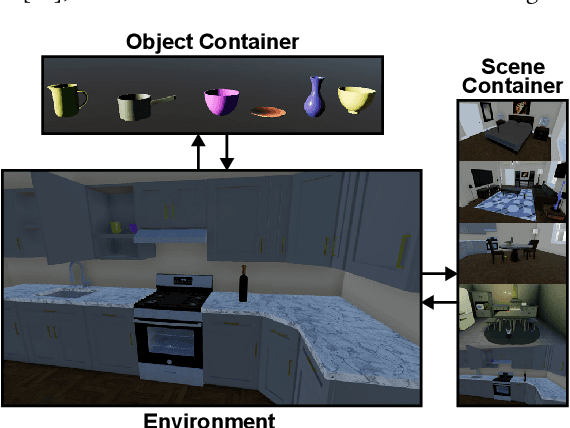
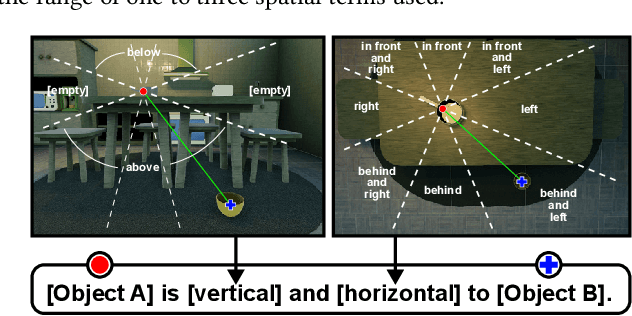
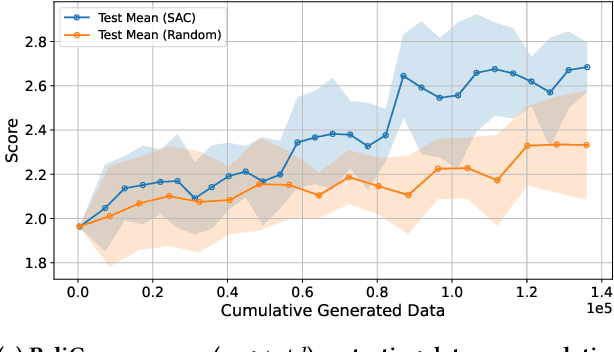
Vision-language model (VLM) fine-tuning for application-specific visual grounding based on natural language instructions has become one of the most popular approaches for learning-enabled autonomous systems. However, such fine-tuning relies heavily on high-quality datasets to achieve successful performance in various downstream tasks. Additionally, VLMs often encounter limitations due to insufficient and imbalanced fine-tuning data. To address these issues, we propose a new generalizable framework to improve VLM fine-tuning by integrating it with a reinforcement learning (RL) agent. Our method utilizes the RL agent to manipulate objects within an indoor setting to create synthetic data for fine-tuning to address certain vulnerabilities of the VLM. Specifically, we use the performance of the VLM to provide feedback to the RL agent to generate informative data that efficiently fine-tune the VLM over the targeted task (e.g. spatial reasoning). The key contribution of this work is developing a framework where the RL agent serves as an informative data sampling tool and assists the VLM in order to enhance performance and address task-specific vulnerabilities. By targeting the data sampling process to address the weaknesses of the VLM, we can effectively train a more context-aware model. In addition, generating synthetic data allows us to have precise control over each scene and generate granular ground truth captions. Our results show that the proposed data generation approach improves the spatial reasoning performance of VLMs, which demonstrates the benefits of using RL-guided data generation in vision-language tasks.
DIMAT: Decentralized Iterative Merging-And-Training for Deep Learning Models
Apr 11, 2024



Recent advances in decentralized deep learning algorithms have demonstrated cutting-edge performance on various tasks with large pre-trained models. However, a pivotal prerequisite for achieving this level of competitiveness is the significant communication and computation overheads when updating these models, which prohibits the applications of them to real-world scenarios. To address this issue, drawing inspiration from advanced model merging techniques without requiring additional training, we introduce the Decentralized Iterative Merging-And-Training (DIMAT) paradigm--a novel decentralized deep learning framework. Within DIMAT, each agent is trained on their local data and periodically merged with their neighboring agents using advanced model merging techniques like activation matching until convergence is achieved. DIMAT provably converges with the best available rate for nonconvex functions with various first-order methods, while yielding tighter error bounds compared to the popular existing approaches. We conduct a comprehensive empirical analysis to validate DIMAT's superiority over baselines across diverse computer vision tasks sourced from multiple datasets. Empirical results validate our theoretical claims by showing that DIMAT attains faster and higher initial gain in accuracy with independent and identically distributed (IID) and non-IID data, incurring lower communication overhead. This DIMAT paradigm presents a new opportunity for the future decentralized learning, enhancing its adaptability to real-world with sparse and light-weight communication and computation.
Active shooter detection and robust tracking utilizing supplemental synthetic data
Sep 06, 2023



The increasing concern surrounding gun violence in the United States has led to a focus on developing systems to improve public safety. One approach to developing such a system is to detect and track shooters, which would help prevent or mitigate the impact of violent incidents. In this paper, we proposed detecting shooters as a whole, rather than just guns, which would allow for improved tracking robustness, as obscuring the gun would no longer cause the system to lose sight of the threat. However, publicly available data on shooters is much more limited and challenging to create than a gun dataset alone. Therefore, we explore the use of domain randomization and transfer learning to improve the effectiveness of training with synthetic data obtained from Unreal Engine environments. This enables the model to be trained on a wider range of data, increasing its ability to generalize to different situations. Using these techniques with YOLOv8 and Deep OC-SORT, we implemented an initial version of a shooter tracking system capable of running on edge hardware, including both a Raspberry Pi and a Jetson Nano.