 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet Distortion Guide Restoration (DGR): A physics-informed learning framework for Prostate Diffusion MRI
Jan 01, 2026We present Distortion-Guided Restoration (DGR), a physics-informed hybrid CNN-diffusion framework for acquisition-free correction of severe susceptibility-induced distortions in prostate single-shot EPI diffusion-weighted imaging (DWI). DGR is trained to invert a realistic forward distortion model using large-scale paired distorted and undistorted data synthesized from distortion-free prostate DWI and co-registered T2-weighted images from 410 multi-institutional studies, together with 11 measured B0 field maps from metal-implant cases incorporated into a forward simulator to generate low-b DWI (b = 50 s per mm squared), high-b DWI (b = 1400 s per mm squared), and ADC distortions. The network couples a CNN-based geometric correction module with conditional diffusion refinement under T2-weighted anatomical guidance. On a held-out synthetic validation set (n = 34) using ground-truth simulated distortion fields, DGR achieved higher PSNR and lower NMSE than FSL TOPUP and FUGUE. In 34 real clinical studies with severe distortion, including hip prostheses and marked rectal distension, DGR improved geometric fidelity and increased radiologist-rated image quality and diagnostic confidence. Overall, learning the inverse of a physically simulated forward process provides a practical alternative to acquisition-dependent distortion-correction pipelines for prostate DWI.
Groupwise Registration with Physics-Informed Test-Time Adaptation on Multi-parametric Cardiac MRI
Oct 29, 2025Multiparametric mapping MRI has become a viable tool for myocardial tissue characterization. However, misalignment between multiparametric maps makes pixel-wise analysis challenging. To address this challenge, we developed a generalizable physics-informed deep-learning model using test-time adaptation to enable group image registration across contrast weighted images acquired from multiple physical models (e.g., a T1 mapping model and T2 mapping model). The physics-informed adaptation utilized the synthetic images from specific physics model as registration reference, allows for transductive learning for various tissue contrast. We validated the model in healthy volunteers with various MRI sequences, demonstrating its improvement for multi-modal registration with a wide range of image contrast variability.
Data-driven Kinematic Modeling in Soft Robots: System Identification and Uncertainty Quantification
Jul 10, 2025Precise kinematic modeling is critical in calibration and controller design for soft robots, yet remains a challenging issue due to their highly nonlinear and complex behaviors. To tackle the issue, numerous data-driven machine learning approaches have been proposed for modeling nonlinear dynamics. However, these models suffer from prediction uncertainty that can negatively affect modeling accuracy, and uncertainty quantification for kinematic modeling in soft robots is underexplored. In this work, using limited simulation and real-world data, we first investigate multiple linear and nonlinear machine learning models commonly used for kinematic modeling of soft robots. The results reveal that nonlinear ensemble methods exhibit the most robust generalization performance. We then develop a conformal kinematic modeling framework for soft robots by utilizing split conformal prediction to quantify predictive position uncertainty, ensuring distribution-free prediction intervals with a theoretical guarantee.
Find the Fruit: Designing a Zero-Shot Sim2Real Deep RL Planner for Occlusion Aware Plant Manipulation
May 22, 2025This paper presents an end-to-end deep reinforcement learning (RL) framework for occlusion-aware robotic manipulation in cluttered plant environments. Our approach enables a robot to interact with a deformable plant to reveal hidden objects of interest, such as fruits, using multimodal observations. We decouple the kinematic planning problem from robot control to simplify zero-shot sim2real transfer for the trained policy. Our results demonstrate that the trained policy, deployed using our framework, achieves up to 86.7% success in real-world trials across diverse initial conditions. Our findings pave the way toward autonomous, perception-driven agricultural robots that intelligently interact with complex foliage plants to "find the fruit" in challenging occluded scenarios, without the need for explicitly designed geometric and dynamic models of every plant scenario.
Zero-shot Sim-to-Real Transfer for Reinforcement Learning-based Visual Servoing of Soft Continuum Arms
Apr 23, 2025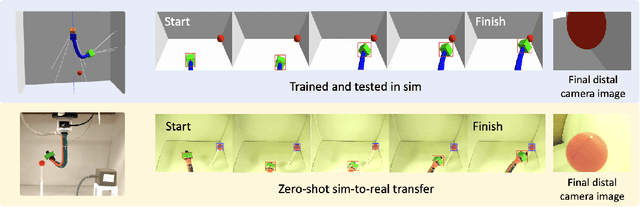
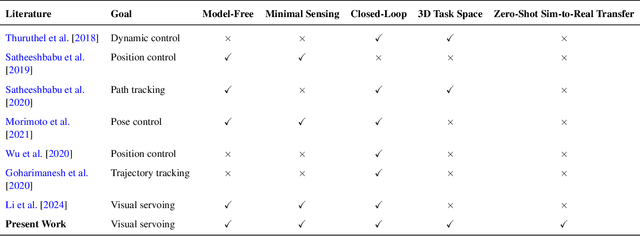
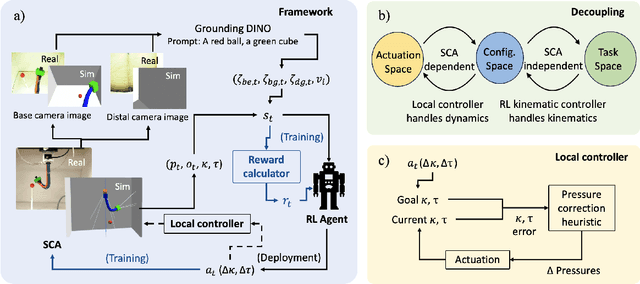
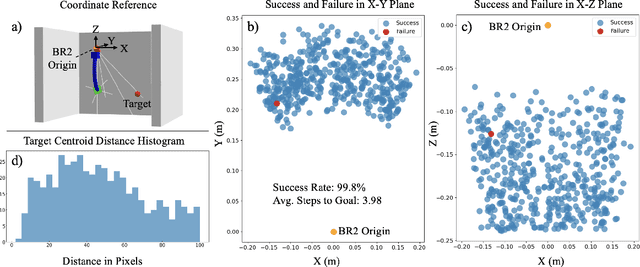
Soft continuum arms (SCAs) soft and deformable nature presents challenges in modeling and control due to their infinite degrees of freedom and non-linear behavior. This work introduces a reinforcement learning (RL)-based framework for visual servoing tasks on SCAs with zero-shot sim-to-real transfer capabilities, demonstrated on a single section pneumatic manipulator capable of bending and twisting. The framework decouples kinematics from mechanical properties using an RL kinematic controller for motion planning and a local controller for actuation refinement, leveraging minimal sensing with visual feedback. Trained entirely in simulation, the RL controller achieved a 99.8% success rate. When deployed on hardware, it achieved a 67% success rate in zero-shot sim-to-real transfer, demonstrating robustness and adaptability. This approach offers a scalable solution for SCAs in 3D visual servoing, with potential for further refinement and expanded applications.
Enhancing PPO with Trajectory-Aware Hybrid Policies
Feb 21, 2025



Proximal policy optimization (PPO) is one of the most popular state-of-the-art on-policy algorithms that has become a standard baseline in modern reinforcement learning with applications in numerous fields. Though it delivers stable performance with theoretical policy improvement guarantees, high variance, and high sample complexity still remain critical challenges in on-policy algorithms. To alleviate these issues, we propose Hybrid-Policy Proximal Policy Optimization (HP3O), which utilizes a trajectory replay buffer to make efficient use of trajectories generated by recent policies. Particularly, the buffer applies the "first in, first out" (FIFO) strategy so as to keep only the recent trajectories to attenuate the data distribution drift. A batch consisting of the trajectory with the best return and other randomly sampled ones from the buffer is used for updating the policy networks. The strategy helps the agent to improve its capability on top of the most recent best performance and in turn reduce variance empirically. We theoretically construct the policy improvement guarantees for the proposed algorithm. HP3O is validated and compared against several baseline algorithms using multiple continuous control environments. Our code is available here.
GENESIS-RL: GEnerating Natural Edge-cases with Systematic Integration of Safety considerations and Reinforcement Learning
Mar 27, 2024



In the rapidly evolving field of autonomous systems, the safety and reliability of the system components are fundamental requirements. These components are often vulnerable to complex and unforeseen environments, making natural edge-case generation essential for enhancing system resilience. This paper presents GENESIS-RL, a novel framework that leverages system-level safety considerations and reinforcement learning techniques to systematically generate naturalistic edge cases. By simulating challenging conditions that mimic the real-world situations, our framework aims to rigorously test entire system's safety and reliability. Although demonstrated within the autonomous driving application, our methodology is adaptable across diverse autonomous systems. Our experimental validation, conducted on high-fidelity simulator underscores the overall effectiveness of this framework.