 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLS3: RL-Based Synthetic Sample Selection to Enhance Spatial Reasoning in Vision-Language Models for Indoor Autonomous Perception
Paper and Code
Jan 31, 2025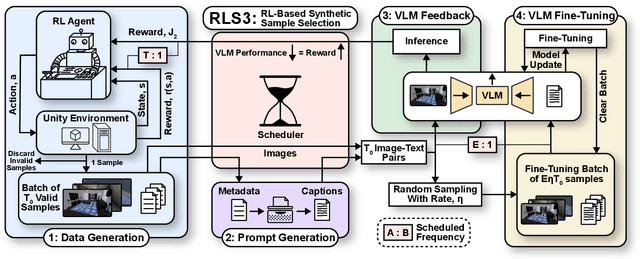
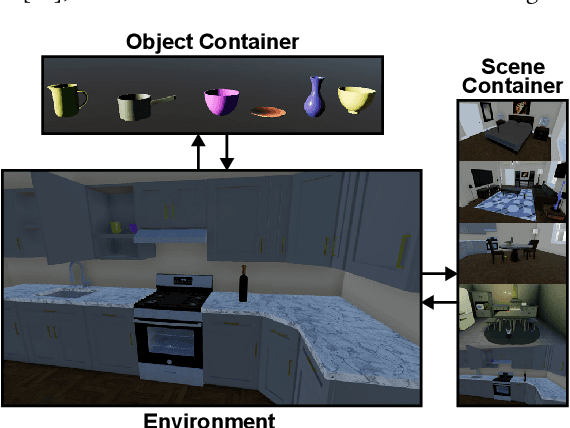
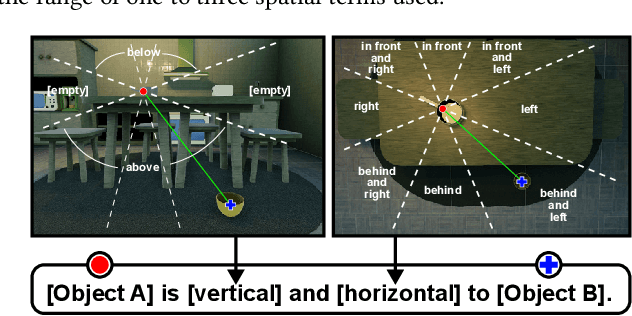
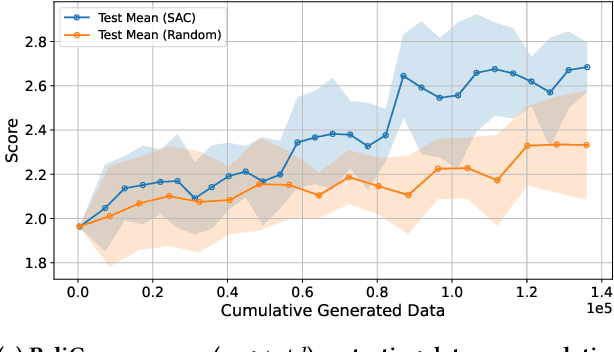
Vision-language model (VLM) fine-tuning for application-specific visual grounding based on natural language instructions has become one of the most popular approaches for learning-enabled autonomous systems. However, such fine-tuning relies heavily on high-quality datasets to achieve successful performance in various downstream tasks. Additionally, VLMs often encounter limitations due to insufficient and imbalanced fine-tuning data. To address these issues, we propose a new generalizable framework to improve VLM fine-tuning by integrating it with a reinforcement learning (RL) agent. Our method utilizes the RL agent to manipulate objects within an indoor setting to create synthetic data for fine-tuning to address certain vulnerabilities of the VLM. Specifically, we use the performance of the VLM to provide feedback to the RL agent to generate informative data that efficiently fine-tune the VLM over the targeted task (e.g. spatial reasoning). The key contribution of this work is developing a framework where the RL agent serves as an informative data sampling tool and assists the VLM in order to enhance performance and address task-specific vulnerabilities. By targeting the data sampling process to address the weaknesses of the VLM, we can effectively train a more context-aware model. In addition, generating synthetic data allows us to have precise control over each scene and generate granular ground truth captions. Our results show that the proposed data generation approach improves the spatial reasoning performance of VLMs, which demonstrates the benefits of using RL-guided data generation in vision-language tasks.