Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Higher-order Moments in Adam
Paper and Code
Oct 15, 2019
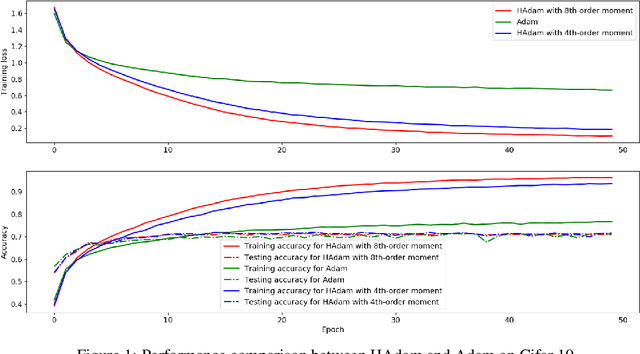
In this paper, we investigate the popular deep learning optimization routine, Adam, from the perspective of statistical moments. While Adam is an adaptive lower-order moment based (of the stochastic gradient) method, we propose an extension namely, HAdam, which uses higher order moments of the stochastic gradient. Our analysis and experiments reveal that certain higher-order moments of the stochastic gradient are able to achieve better performance compared to the vanilla Adam algorithm. We also provide some analysis of HAdam related to odd and even moments to explain some intriguing and seemingly non-intuitive empirical results.
* Accepted in Beyond First Order Methods in Machine Learning workshop
in 33rd Conference on Neural Information Processing Systems (NeurIPS 2019),
Vancouver, Canada
View paper on