 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporally Constrained Action Space Attacks on Deep Reinforcement Learning Agents
Sep 05, 2019
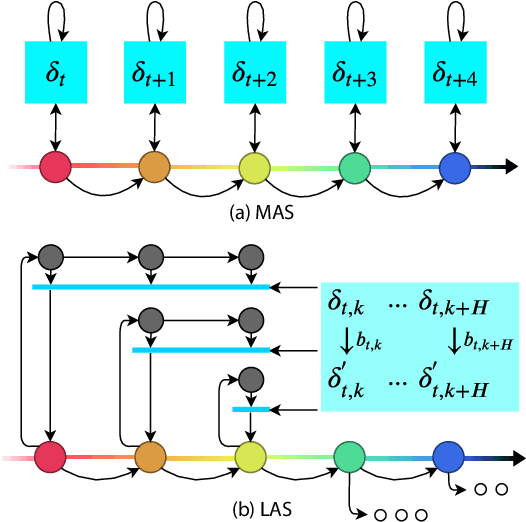
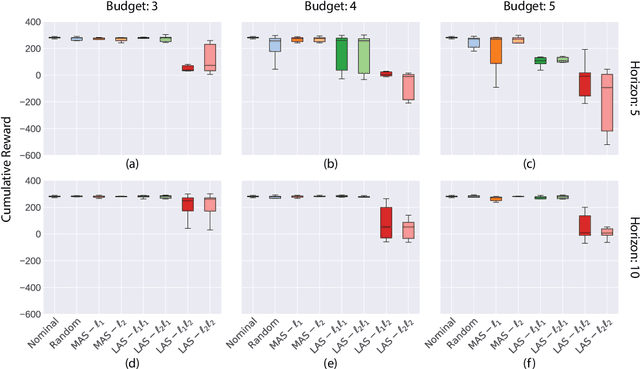
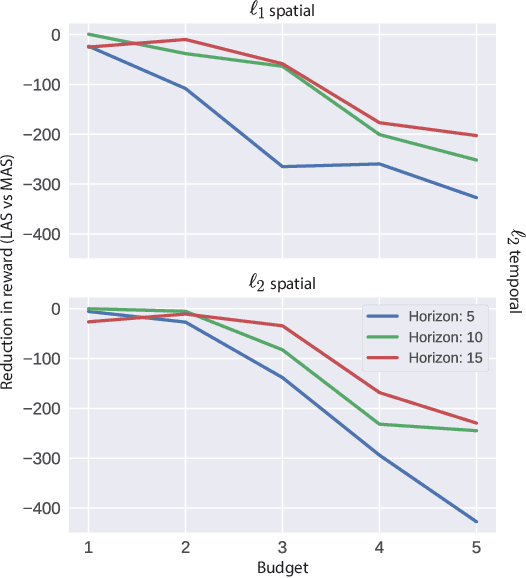
Robustness of Deep Reinforcement Learning (DRL) algorithms towards adversarial attacks in real world applications such as those deployed in cyber-physical systems (CPS) are of increasing concern. Numerous studies have investigated the mechanisms of attacks on the RL agent's state space. Nonetheless, attacks on the RL agent's action space (AS) (corresponding to actuators in engineering systems) are equally perverse; such attacks are relatively less studied in the ML literature. In this work, we first frame the problem as an optimization problem of minimizing the cumulative reward of an RL agent with decoupled constraints as the budget of attack. We propose a white-box Myopic Action Space (MAS) attack algorithm that distributes the attacks across the action space dimensions. Next, we reformulate the optimization problem above with the same objective function, but with a temporally coupled constraint on the attack budget to take into account the approximated dynamics of the agent. This leads to the white-box Look-ahead Action Space (LAS) attack algorithm that distributes the attacks across the action and temporal dimensions. Our results shows that using the same amount of resources, the LAS attack deteriorates the agent's performance significantly more than the MAS attack. This reveals the possibility that with limited resource, an adversary can utilize the agent's dynamics to malevolently craft attacks that causes the agent to fail. Additionally, we leverage these attack strategies as a possible tool to gain insights on the potential vulnerabilities of DRL agents.
Multi-Resolution 3D Convolutional Neural Networks for Object Recognition
May 30, 2018



Learning from 3D Data is a fascinating idea which is well explored and studied in computer vision. This allows one to learn from very sparse LiDAR data, point cloud data as well as 3D objects in terms of CAD models and surfaces etc. Most of the approaches to learn from such data are limited to uniform 3D volume occupancy grids or octree representations. A major challenge in learning from 3D data is that one needs to define a proper resolution to represent it in a voxel grid and this becomes a bottleneck for the learning algorithms. Specifically, while we focus on learning from 3D data, a fine resolution is very important to capture key features in the object and at the same time the data becomes sparser as the resolution becomes finer. There are numerous applications in computer vision where a multi-resolution representation is used instead of a uniform grid representation in order to make the applications memory efficient. Though such methods are difficult to learn from, they are much more efficient in representing 3D data. In this paper, we explore the challenges in learning from such data representation. In particular, we use a multi-level voxel representation where we define a coarse voxel grid that contains information of important voxels(boundary voxels) and multiple fine voxel grids corresponding to each significant voxel of the coarse grid. A multi-level voxel representation can capture important features in the 3D data in a memory efficient way in comparison to an octree representation. Consequently, learning from a 3D object with high resolution, which is paramount in feature recognition, is made efficient.
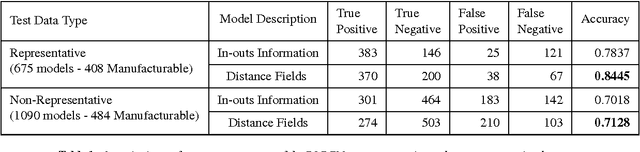
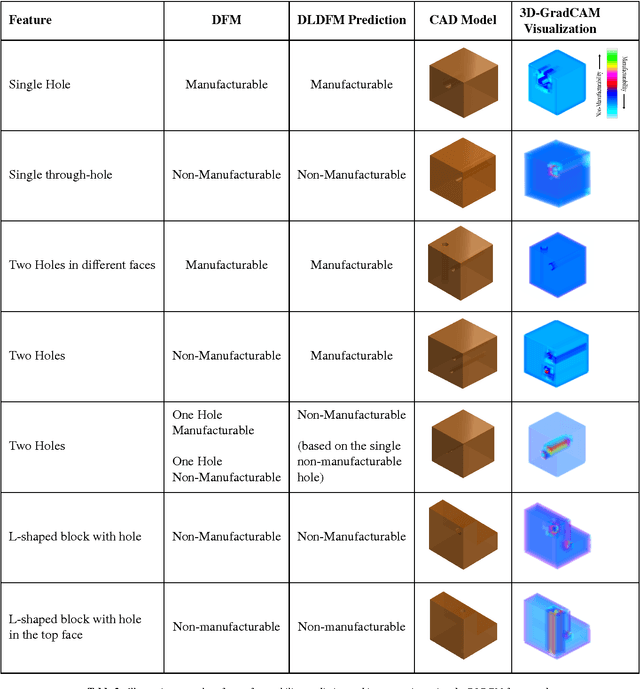
Learning and Visualizing Localized Geometric Features Using 3D-CNN: An Application to Manufacturability Analysis of Drilled Holes
Mar 28, 2018

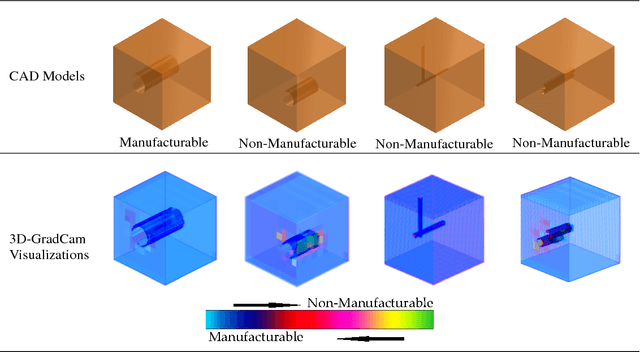
3D Convolutional Neural Networks (3D-CNN) have been used for object recognition based on the voxelized shape of an object. However, interpreting the decision making process of these 3D-CNNs is still an infeasible task. In this paper, we present a unique 3D-CNN based Gradient-weighted Class Activation Mapping method (3D-GradCAM) for visual explanations of the distinct local geometric features of interest within an object. To enable efficient learning of 3D geometries, we augment the voxel data with surface normals of the object boundary. We then train a 3D-CNN with this augmented data and identify the local features critical for decision-making using 3D GradCAM. An application of this feature identification framework is to recognize difficult-to-manufacture drilled hole features in a complex CAD geometry. The framework can be extended to identify difficult-to-manufacture features at multiple spatial scales leading to a real-time design for manufacturability decision support system.
Learning Localized Geometric Features Using 3D-CNN: An Application to Manufacturability Analysis of Drilled Holes
Jun 22, 2017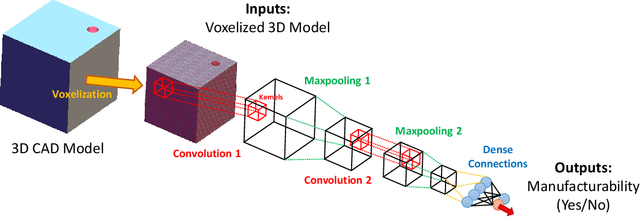
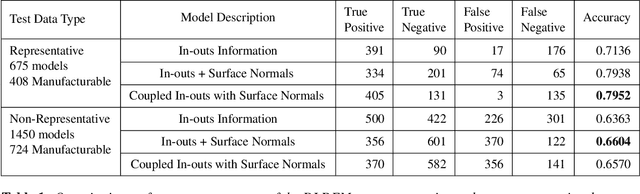
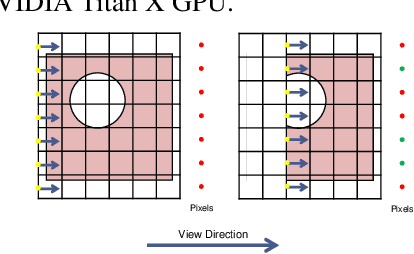
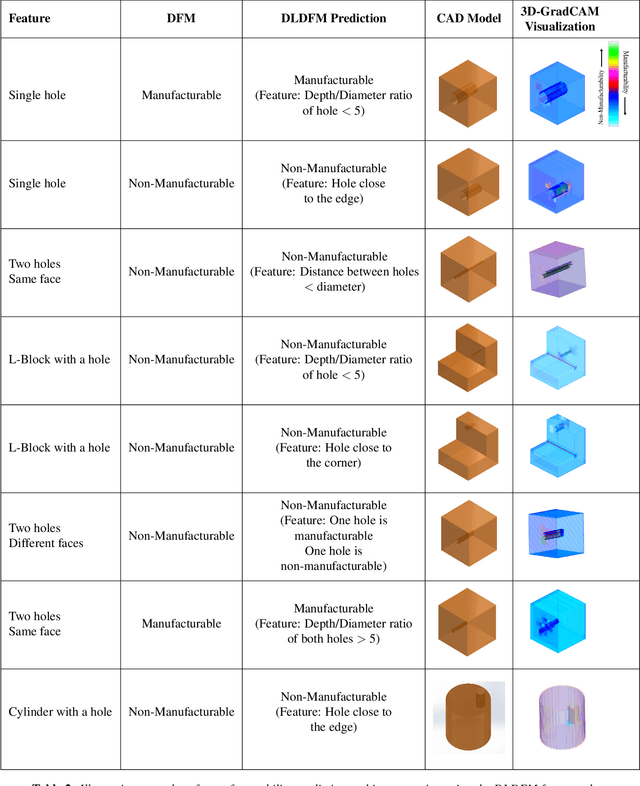
3D convolutional neural networks (3D-CNN) have been used for object recognition based on the voxelized shape of an object. In this paper, we present a 3D-CNN based method to learn distinct local geometric features of interest within an object. In this context, the voxelized representation may not be sufficient to capture the distinguishing information about such local features. To enable efficient learning, we augment the voxel data with surface normals of the object boundary. We then train a 3D-CNN with this augmented data and identify the local features critical for decision-making using 3D gradient-weighted class activation maps. An application of this feature identification framework is to recognize difficult-to-manufacture drilled hole features in a complex CAD geometry. The framework can be extended to identify difficult-to-manufacture features at multiple spatial scales leading to a real-time decision support system for design for manufacturability.
A Machine-Learning Framework for Design for Manufacturability
Mar 15, 2017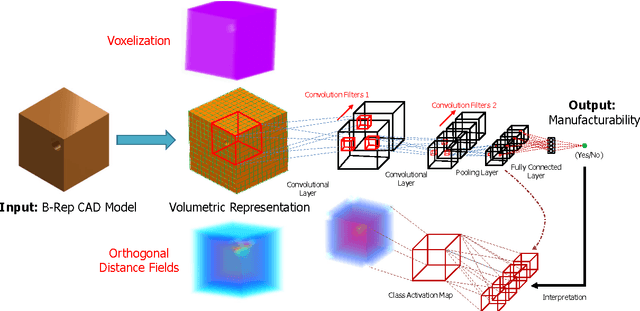

this is a duplicate submission(original is arXiv:1612.02141). Hence want to withdraw it