 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXAI-Increment: A Novel Approach Leveraging LIME Explanations for Improved Incremental Learning
Nov 02, 2022



Explainability of neural network prediction is essential to understand feature importance and gain interpretable insight into neural network performance. In this work, model explanations are fed back to the feed-forward training to help the model generalize better. To this extent, a custom weighted loss where the weights are generated by considering the Euclidean distances between true LIME (Local Interpretable Model-Agnostic Explanations) explanations and model-predicted LIME explanations is proposed. Also, in practical training scenarios, developing a solution that can help the model learn sequentially without losing information on previous data distribution is imperative due to the unavailability of all the training data at once. Thus, the framework known as XAI-Increment incorporates the custom weighted loss developed with elastic weight consolidation (EWC), to maintain performance in sequential testing sets. Finally, the training procedure involving the custom weighted loss shows around 1% accuracy improvement compared to the traditional loss based training for the keyword spotting task on the Google Speech Commands dataset and also shows low loss of information when coupled with EWC in the incremental learning setup.
A Fast Network Exploration Strategy to Profile Low Energy Consumption for Keyword Spotting
Feb 04, 2022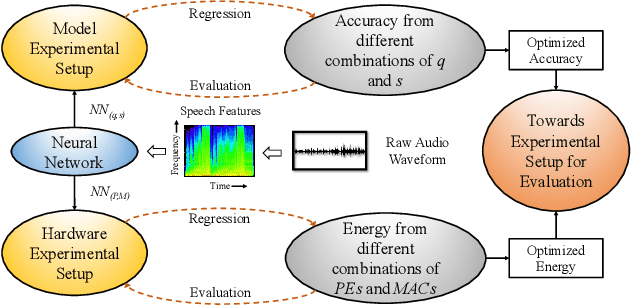
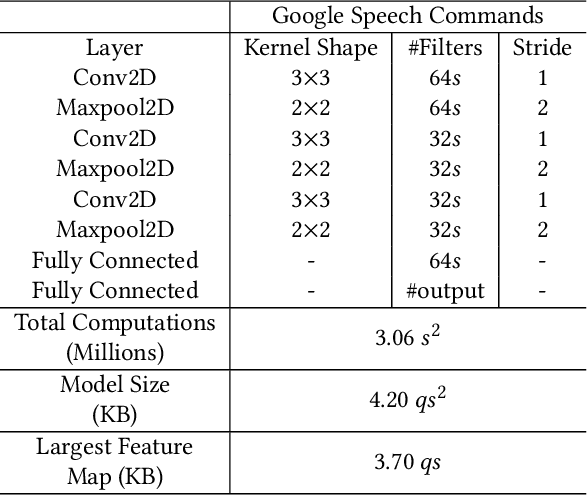
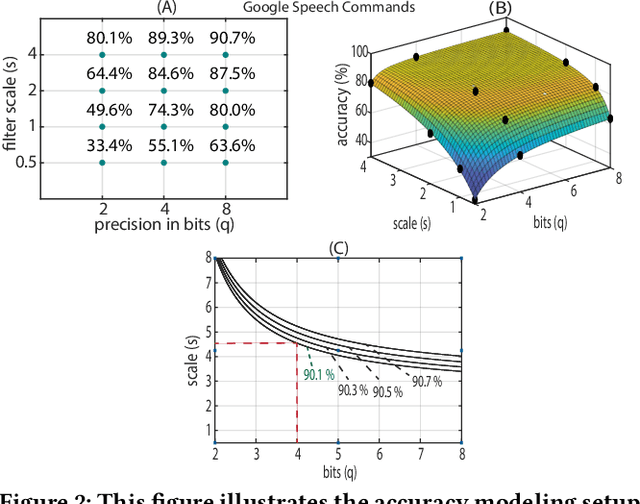

Keyword Spotting nowadays is an integral part of speech-oriented user interaction targeted for smart devices. To this extent, neural networks are extensively used for their flexibility and high accuracy. However, coming up with a suitable configuration for both accuracy requirements and hardware deployment is a challenge. We propose a regression-based network exploration technique that considers the scaling of the network filters ($s$) and quantization ($q$) of the network layers, leading to a friendly and energy-efficient configuration for FPGA hardware implementation. We experiment with different combinations of $\mathcal{NN}\scriptstyle\langle q,\,s\rangle \displaystyle$ on the FPGA to profile the energy consumption of the deployed network so that the user can choose the most energy-efficient network configuration promptly. Our accelerator design is deployed on the Xilinx AC 701 platform and has at least 2.1$\times$ and 4$\times$ improvements on energy and energy efficiency results, respectively, compared to recent hardware implementations for keyword spotting.
Neural Networks for Pulmonary Disease Diagnosis using Auditory and Demographic Information
Nov 26, 2020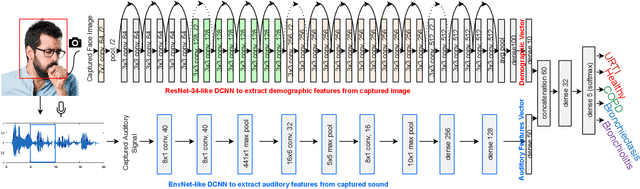
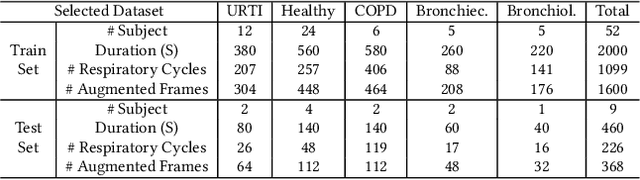


Pulmonary diseases impact millions of lives globally and annually. The recent outbreak of the pandemic of the COVID-19, a novel pulmonary infection, has more than ever brought the attention of the research community to the machine-aided diagnosis of respiratory problems. This paper is thus an effort to exploit machine learning for classification of respiratory problems and proposes a framework that employs as much correlated information (auditory and demographic information in this work) as a dataset provides to increase the sensitivity and specificity of a diagnosing system. First, we use deep convolutional neural networks (DCNNs) to process and classify a publicly released pulmonary auditory dataset, and then we take advantage of the existing demographic information within the dataset and show that the accuracy of the pulmonary classification increases by 5% when trained on the auditory information in conjunction with the demographic information. Since the demographic data can be extracted using computer vision, we suggest using another parallel DCNN to estimate the demographic information of the subject under test visioned by the processing computer. Lastly, as a proposition to bring the healthcare system to users' fingertips, we measure deployment characteristics of the auditory DCNN model onto processing components of an NVIDIA TX2 development board.