 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXAI-BayesHAR: A novel Framework for Human Activity Recognition with Integrated Uncertainty and Shapely Values
Nov 07, 2022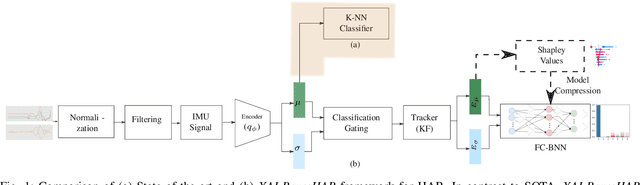
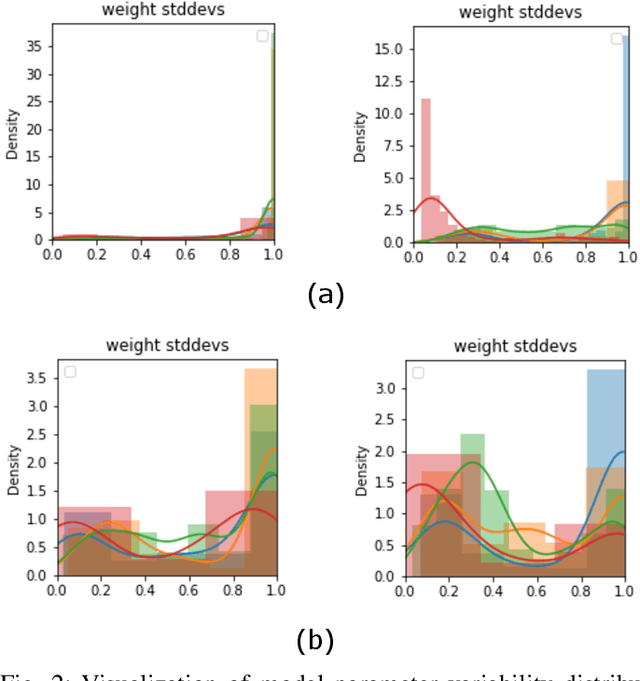
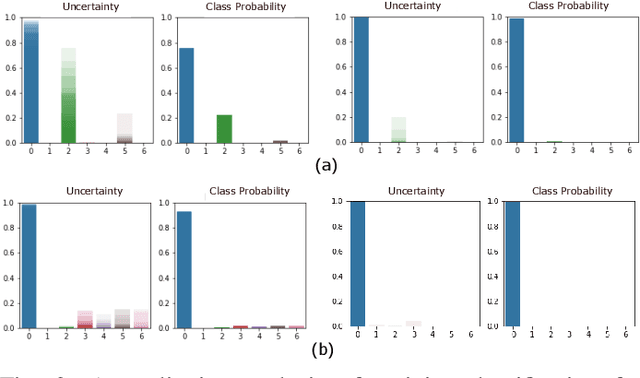
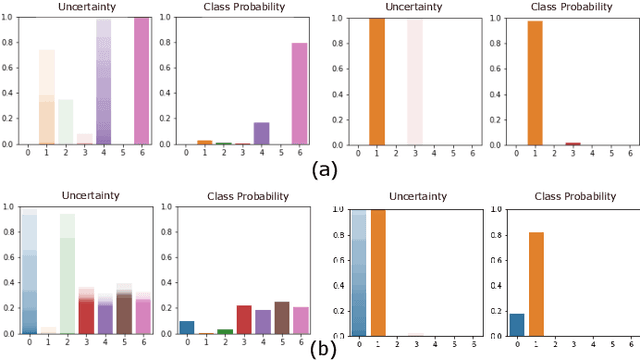
Human activity recognition (HAR) using IMU sensors, namely accelerometer and gyroscope, has several applications in smart homes, healthcare and human-machine interface systems. In practice, the IMU-based HAR system is expected to encounter variations in measurement due to sensor degradation, alien environment or sensor noise and will be subjected to unknown activities. In view of practical deployment of the solution, analysis of statistical confidence over the activity class score are important metrics. In this paper, we therefore propose XAI-BayesHAR, an integrated Bayesian framework, that improves the overall activity classification accuracy of IMU-based HAR solutions by recursively tracking the feature embedding vector and its associated uncertainty via Kalman filter. Additionally, XAI-BayesHAR acts as an out of data distribution (OOD) detector using the predictive uncertainty which help to evaluate and detect alien input data distribution. Furthermore, Shapley value-based performance of the proposed framework is also evaluated to understand the importance of the feature embedding vector and accordingly used for model compression
XAI-Increment: A Novel Approach Leveraging LIME Explanations for Improved Incremental Learning
Nov 02, 2022



Explainability of neural network prediction is essential to understand feature importance and gain interpretable insight into neural network performance. In this work, model explanations are fed back to the feed-forward training to help the model generalize better. To this extent, a custom weighted loss where the weights are generated by considering the Euclidean distances between true LIME (Local Interpretable Model-Agnostic Explanations) explanations and model-predicted LIME explanations is proposed. Also, in practical training scenarios, developing a solution that can help the model learn sequentially without losing information on previous data distribution is imperative due to the unavailability of all the training data at once. Thus, the framework known as XAI-Increment incorporates the custom weighted loss developed with elastic weight consolidation (EWC), to maintain performance in sequential testing sets. Finally, the training procedure involving the custom weighted loss shows around 1% accuracy improvement compared to the traditional loss based training for the keyword spotting task on the Google Speech Commands dataset and also shows low loss of information when coupled with EWC in the incremental learning setup.