 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Uncertainty and Personalization via Efficient Second-order Optimization
Nov 27, 2024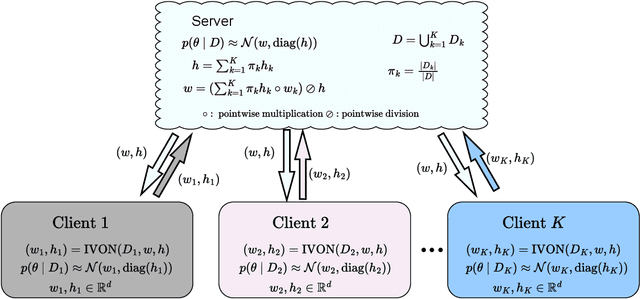


Federated Learning (FL) has emerged as a promising method to collaboratively learn from decentralized and heterogeneous data available at different clients without the requirement of data ever leaving the clients. Recent works on FL have advocated taking a Bayesian approach to FL as it offers a principled way to account for the model and predictive uncertainty by learning a posterior distribution for the client and/or server models. Moreover, Bayesian FL also naturally enables personalization in FL to handle data heterogeneity across the different clients by having each client learn its own distinct personalized model. In particular, the hierarchical Bayesian approach enables all the clients to learn their personalized models while also taking into account the commonalities via a prior distribution provided by the server. However, despite their promise, Bayesian approaches for FL can be computationally expensive and can have high communication costs as well because of the requirement of computing and sending the posterior distributions. We present a novel Bayesian FL method using an efficient second-order optimization approach, with a computational cost that is similar to first-order optimization methods like Adam, but also provides the various benefits of the Bayesian approach for FL (e.g., uncertainty, personalization), while also being significantly more efficient and accurate than SOTA Bayesian FL methods (both for standard as well as personalized FL settings). Our method achieves improved predictive accuracies as well as better uncertainty estimates as compared to the baselines which include both optimization based as well as Bayesian FL methods.
Robust Black-box Testing of Deep Neural Networks using Co-Domain Coverage
Aug 13, 2024Rigorous testing of machine learning models is necessary for trustworthy deployments. We present a novel black-box approach for generating test-suites for robust testing of deep neural networks (DNNs). Most existing methods create test inputs based on maximizing some "coverage" criterion/metric such as a fraction of neurons activated by the test inputs. Such approaches, however, can only analyze each neuron's behavior or each layer's output in isolation and are unable to capture their collective effect on the DNN's output, resulting in test suites that often do not capture the various failure modes of the DNN adequately. These approaches also require white-box access, i.e., access to the DNN's internals (node activations). We present a novel black-box coverage criterion called Co-Domain Coverage (CDC), which is defined as a function of the model's output and thus takes into account its end-to-end behavior. Subsequently, we develop a new fuzz testing procedure named CoDoFuzz, which uses CDC to guide the fuzzing process to generate a test suite for a DNN. We extensively compare the test suite generated by CoDoFuzz with those generated using several state-of-the-art coverage-based fuzz testing methods for the DNNs trained on six publicly available datasets. Experimental results establish the efficiency and efficacy of CoDoFuzz in generating the largest number of misclassified inputs and the inputs for which the model lacks confidence in its decision.
Insuring Smiles: Predicting routine dental coverage using Spark ML
Oct 13, 2023Finding suitable health insurance coverage can be challenging for individuals and small enterprises in the USA. The Health Insurance Exchange Public Use Files (Exchange PUFs) dataset provided by CMS offers valuable information on health and dental policies [1]. In this paper, we leverage machine learning algorithms to predict if a health insurance plan covers routine dental services for adults. By analyzing plan type, region, deductibles, out-of-pocket maximums, and copayments, we employ Logistic Regression, Decision Tree, Random Forest, Gradient Boost, Factorization Model and Support Vector Machine algorithms. Our goal is to provide a clinical strategy for individuals and families to select the most suitable insurance plan based on income and expenses.
Bayesian Federated Learning via Predictive Distribution Distillation
Jun 15, 2022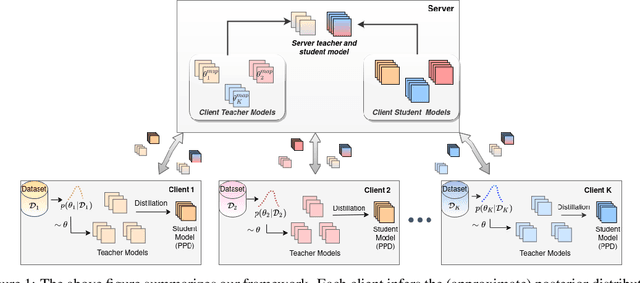
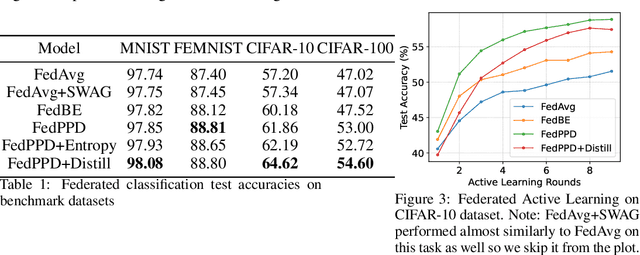
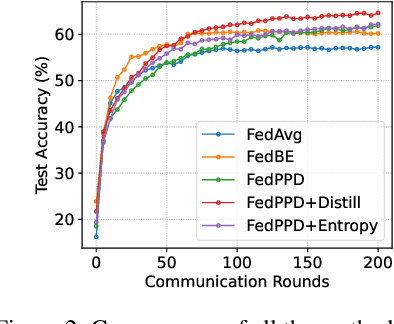
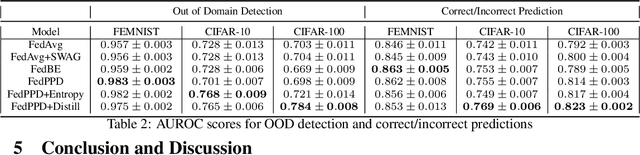
For most existing federated learning algorithms, each round consists of minimizing a loss function at each client to learn an optimal model at the client, followed by aggregating these client models at the server. Point estimation of the model parameters at the clients does not take into account the uncertainty in the models estimated at each client. In many situations, however, especially in limited data settings, it is beneficial to take into account the uncertainty in the client models for more accurate and robust predictions. Uncertainty also provides useful information for other important tasks, such as active learning and out-of-distribution (OOD) detection. We present a framework for Bayesian federated learning where each client infers the posterior predictive distribution using its training data and present various ways to aggregate these client-specific predictive distributions at the server. Since communicating and aggregating predictive distributions can be challenging and expensive, our approach is based on distilling each client's predictive distribution into a single deep neural network. This enables us to leverage advances in standard federated learning to Bayesian federated learning as well. Unlike some recent works that have tried to estimate model uncertainty of each client, our work also does not make any restrictive assumptions, such as the form of the client's posterior distribution. We evaluate our approach on classification in federated setting, as well as active learning and OOD detection in federated settings, on which our approach outperforms various existing federated learning baselines.
Humor@IITK at SemEval-2021 Task 7: Large Language Models for Quantifying Humor and Offensiveness
Apr 02, 2021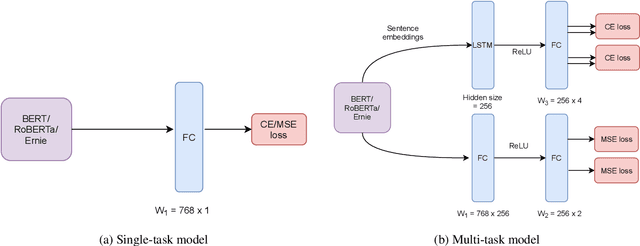
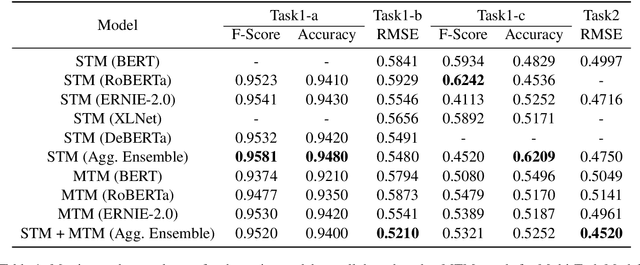
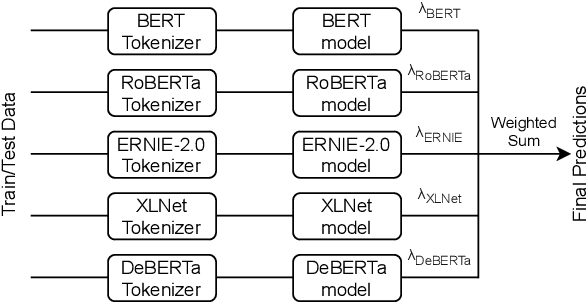
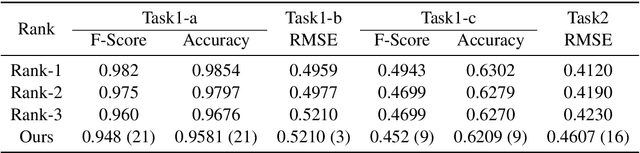
Humor and Offense are highly subjective due to multiple word senses, cultural knowledge, and pragmatic competence. Hence, accurately detecting humorous and offensive texts has several compelling use cases in Recommendation Systems and Personalized Content Moderation. However, due to the lack of an extensive labeled dataset, most prior works in this domain haven't explored large neural models for subjective humor understanding. This paper explores whether large neural models and their ensembles can capture the intricacies associated with humor/offense detection and rating. Our experiments on the SemEval-2021 Task 7: HaHackathon show that we can develop reasonable humor and offense detection systems with such models. Our models are ranked third in subtask 1b and consistently ranked around the top 33% of the leaderboard for the remaining subtasks.